
Profile

|
Dr. Paul Voigtlaender |
Teaching
Einführung in die Informatik (Introduction to Computer Science), WS 19/20
Students
(hiwi = student assistant)
Current
- Jens Piekenbrinck (master thesis)
Past
- Ali Mohamed Fatouh Ahmed (master thesis)
- Bruno Vollmer (master thesis)
- Kinan Halloum (master thesis)
- Bin Huang (hiwi)
- Berin Gnana (hiwi)
- Blin Beqa (hiwi)
- Bojana Stefanovska (hiwi)
- Rohit Ravi (hiwi)
- Umair Sabir (hiwi)
- Jonathan Schieren (hiwi)
- Valentin Steiner (hiwi)
- Sourabh Swain (hiwi)
- Michael Krause (master thesis)
- Jonathon Luiten (master thesis)
- Sabarinath Mahadevan (master thesis)
- Hendrik Gruß (master thesis)
- Valentin Steiner (bachelor thesis)
Publications
Point-VOS: Pointing Up Video Object Segmentation

Current state-of-the-art Video Object Segmentation (VOS) methods rely on dense per-object mask annotations both during training and testing. This requires time-consuming and costly video annotation mechanisms. We propose a novel Point-VOS task with a spatio-temporally sparse point-wise annotation scheme that substantially reduces the annotation effort. We apply our annotation scheme to two large-scale video datasets with text descriptions and annotate over 19M points across 133K objects in 32K videos. Based on our annotations, we propose a new Point-VOS benchmark, and a corresponding point-based training mechanism, which we use to establish strong baseline results. We show that existing VOS methods can easily be adapted to leverage our point annotations during training, and can achieve results close to the fully-supervised performance when trained on pseudo-masks generated from these points. In addition, we show that our data can be used to improve models that connect vision and language, by evaluating it on the Video Narrative Grounding (VNG) task. We will make our code and annotations available at https://pointvos.github.io.
BURST: A Benchmark for Unifying Object Recognition, Segmentation and Tracking in Video

Multiple existing benchmarks involve tracking and segmenting objects in video e.g., Video Object Segmentation (VOS) and Multi-Object Tracking and Segmentation (MOTS), but there is little interaction between them due to the use of disparate benchmark datasets and metrics (e.g. J&F, mAP, sMOTSA). As a result, published works usually target a particular benchmark, and are not easily comparable to each another. We believe that the development of generalized methods that can tackle multiple tasks requires greater cohesion among these research sub-communities. In this paper, we aim to facilitate this by proposing BURST, a dataset which contains thousands of diverse videos with high-quality object masks, and an associated benchmark with six tasks involving object tracking and segmentation in video. All tasks are evaluated using the same data and comparable metrics, which enables researchers to consider them in unison, and hence, more effectively pool knowledge from different methods across different tasks. Additionally, we demonstrate several baselines for all tasks and show that approaches for one task can be applied to another with a quantifiable and explainable performance difference.
» Show BibTeX
@inproceedings{athar2023burst,
title={BURST: A Benchmark for Unifying Object Recognition, Segmentation and Tracking in Video},
author={Athar, Ali and Luiten, Jonathon and Voigtlaender, Paul and Khurana, Tarasha and Dave, Achal and Leibe, Bastian and Ramanan, Deva},
booktitle={WACV},
year={2023}
}
Reducing the Annotation Effort for Video Object Segmentation Datasets

For further progress in video object segmentation (VOS), larger, more diverse, and more challenging datasets will be necessary. However, densely labeling every frame with pixel masks does not scale to large datasets. We use a deep convolutional network to automatically create pseudo-labels on a pixel level from much cheaper bounding box annotations and investigate how far such pseudo-labels can carry us for training state-of-the-art VOS approaches. A very encouraging result of our study is that adding a manually annotated mask in only a single video frame for each object is sufficient to generate pseudo-labels which can be used to train a VOS method to reach almost the same performance level as when training with fully segmented videos. We use this workflow to create pixel pseudo-labels for the training set of the challenging tracking dataset TAO, and we manually annotate a subset of the validation set. Together, we obtain the new TAO-VOS benchmark, which we make publicly available at http://www.vision.rwth-aachen.de/page/taovos. While the performance of state-of-the-art methods on existing datasets starts to saturate, TAO-VOS remains very challenging for current algorithms and reveals their shortcomings.
@inproceedings{Voigtlaender21WACV,
title={Reducing the Annotation Effort for Video Object Segmentation Datasets},
author={Paul Voigtlaender and Lishu Luo and Chun Yuan and Yong Jiang and Bastian Leibe},
booktitle={WACV},
year={2021}
}
Siam R-CNN: Visual Tracking by Re-Detection

We present Siam R-CNN, a Siamese re-detection architecture which unleashes the full power of two-stage object detection approaches for visual object tracking. We combine this with a novel tracklet-based dynamic programming algorithm, which takes advantage of re-detections of both the first-frame template and previous-frame predictions, to model the full history of both the object to be tracked and potential distractor objects. This enables our approach to make better tracking decisions, as well as to re-detect tracked objects after long occlusion. Finally, we propose a novel hard example mining strategy to improve Siam RCNN’s robustness to similar looking objects. The proposed tracker achieves the current best performance on ten tracking benchmarks, with especially strong results for long-term tracking.
@inproceedings{Voigtlaender20CVPR,
title={Siam R-CNN: Visual Tracking by Re-Detection},
author={Paul Voigtlaender and Jonathon Luiten and Philip H. S. Torr and Bastian Leibe},
year={2020},
booktitle={CVPR},
}
FEELVOS: Fast End-to-End Embedding Learning for Video Object Segmentation
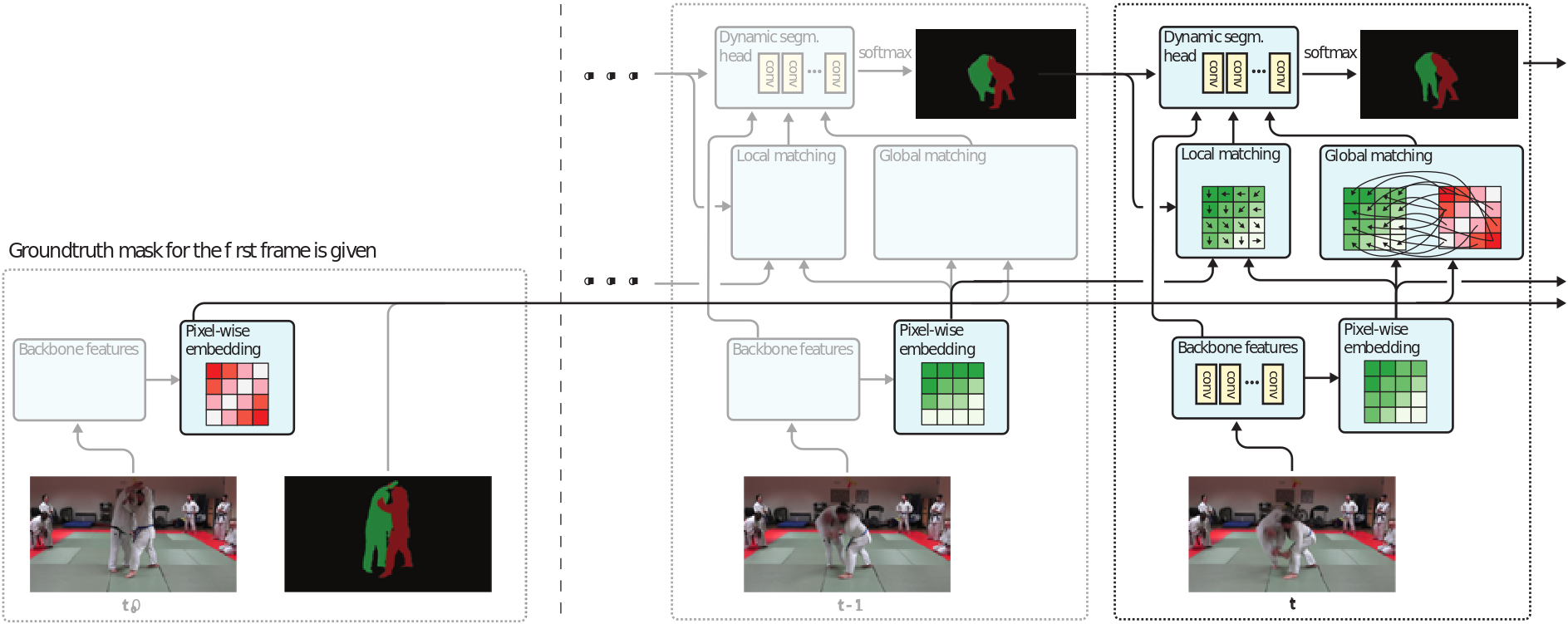
Many of the recent successful methods for video object segmentation (VOS) are overly complicated, heavily rely on fine-tuning on the first frame, and/or are slow, and are hence of limited practical use. In this work, we propose FEELVOS as a simple and fast method which does not rely on fine-tuning. In order to segment a video, for each frame FEELVOS uses a semantic pixel-wise embedding together with a global and a local matching mechanism to transfer information from the first frame and from the previous frame of the video to the current frame. In contrast to previous work, our embedding is only used as an internal guidance of a convolutional network. Our novel dynamic segmentation head allows us to train the network, including the embedding, end-to-end for the multiple object segmentation task with a cross entropy loss. We achieve a new state of the art in video object segmentation without fine-tuning with a J&F measure of 71.5% on the DAVIS 2017 validation set. We make our code and models available at https://github.com/tensorflow/models/tree/master/research/feelvos.
@inproceedings{Voigtlaender19CVPR,
title={{FEELVOS}: Fast End-to-End Embedding Learning for Video Object Segmentation},
author={Paul Voigtlaender and Yuning Chai and Florian Schroff and Hartwig Adam and Bastian Leibe and Liang-Chieh Chen},
booktitle={CVPR},
year={2019}
}
MOTS: Multi-Object Tracking and Segmentation

This paper extends the popular task of multi-object tracking to multi-object tracking and segmentation (MOTS). Towards this goal, we create dense pixel-level annotations for two existing tracking datasets using a semi-automatic annotation procedure. Our new annotations comprise 65,213 pixel masks for 977 distinct objects (cars and pedestrians) in 10,870 video frames. For evaluation, we extend existing multi-object tracking metrics to this new task. Moreover, we propose a new baseline method which jointly addresses detection, tracking, and segmentation with a single convolutional network. We demonstrate the value of our datasets by achieving improvements in performance when training on MOTS annotations. We believe that our datasets, metrics and baseline will become a valuable resource towards developing multi-object tracking approaches that go beyond 2D bounding boxes. We make our annotations, code, and models available at https://www.vision.rwth-aachen.de/page/mots.
» Show BibTeX
@inproceedings{Voigtlaender19CVPR_MOTS,
author = {Paul Voigtlaender and Michael Krause and Aljo\u{s}a O\u{s}ep and Jonathon Luiten and Berin Balachandar Gnana Sekar and Andreas Geiger and Bastian Leibe},
title = {{MOTS}: Multi-Object Tracking and Segmentation},
booktitle = {CVPR},
year = {2019},
}
Large-Scale Object Mining for Object Discovery from Unlabeled Video
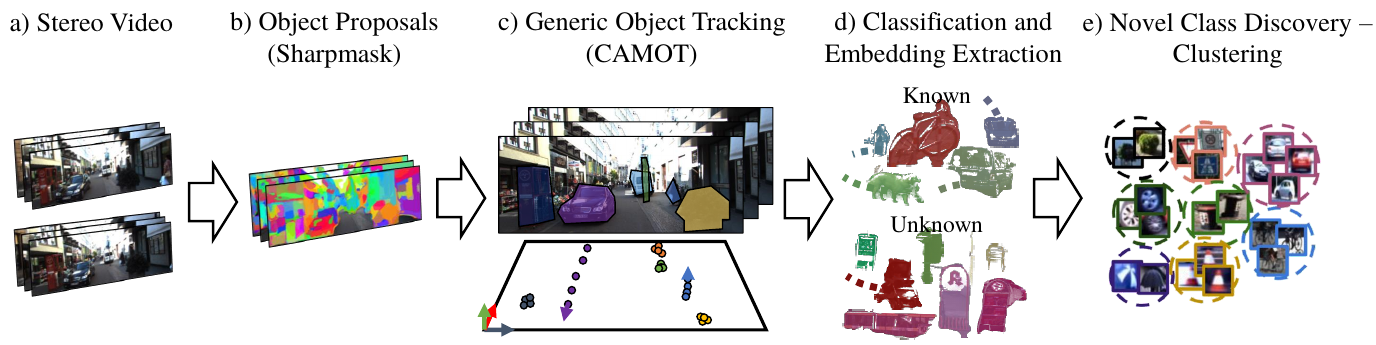
This paper addresses the problem of object discovery from unlabeled driving videos captured in a realistic automotive setting. Identifying recurring object categories in such raw video streams is a very challenging problem. Not only do object candidates first have to be localized in the input images, but many interesting object categories occur relatively infrequently. Object discovery will therefore have to deal with the difficulties of operating in the long tail of the object distribution. We demonstrate the feasibility of performing fully automatic object discovery in such a setting by mining object tracks using a generic object tracker. In order to facilitate further research in object discovery, we will release a collection of more than 360'000 automatically mined object tracks from 10+ hours of video data (560'000 frames). We use this dataset to evaluate the suitability of different feature representations and clustering strategies for object discovery.
@article{Osep19ICRA,
author = {O\v{s}ep, Aljo\v{s}a and Voigtlaender, Paul and Luiten, Jonathon and Breuers, Stefan and Leibe, Bastian},
title = {Large-Scale Object Mining for Object Discovery from Unlabeled Video},
journal = {ICRA},
year = {2019}
}
4D Generic Video Object Proposals

Many high-level video understanding methods require input in the form of object proposals. Currently, such proposals are predominantly generated with the help of networks that were trained for detecting and segmenting a set of known object classes, which limits their applicability to cases where all objects of interest are represented in the training set. This is a restriction for automotive scenarios, where unknown objects can frequently occur. We propose an approach that can reliably extract spatio-temporal object proposals for both known and unknown object categories from stereo video. Our 4D Generic Video Tubes (4D-GVT) method leverages motion cues, stereo data, and object instance segmentation to compute a compact set of video-object proposals that precisely localizes object candidates and their contours in 3D space and time. We show that given only a small amount of labeled data, our 4D-GVT proposal generator generalizes well to real-world scenarios, in which unknown categories appear. It outperforms other approaches that try to detect as many objects as possible by increasing the number of classes in the training set to several thousand.
@inproceedings{Osep19ICRA,
author = {O\v{s}ep, Aljo\v{s}a and Voigtlaender, Paul and Weber, Mark and Luiten, Jonathon and Leibe, Bastian},
title = {4D Generic Video Object Proposals},
booktitle = {ICRA},
year = {2020}
}
Combining PReMVOS with Box-Level Tracking for the 2019 DAVIS Challenge
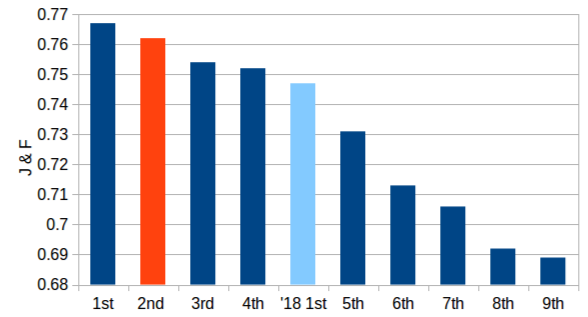
Recently a number of different approaches have beenproposed for tackling the task of Video Object Segmentation(VOS). In this paper we compare and contrast two particu-larly powerful methods, PReMVOS (Proposal-generation,Refinement and Merging for VOS), and BoLTVOS (Box-Level Tracking for VOS). PReMVOS follows a tracking-by-detection framework in which a set of object proposals aregenerated per frame and are then linked into tracks overtime by optical flow and appearance similarity cues. In con-trast, BoLTVOS uses a Siamese architecture to directly de-tect the object to be tracked based on its similarity to thegiven first-frame object. Although BoLTVOS can outper-form PReMVOS when the number of objects to be trackedis small, it does not scale as well to tracking multiple ob-jects. Finally we develop a model which combines bothBoLTVOS and PReMVOS and achieves aJ&Fscore of76.2% on the DAVIS 2017 test-challenge benchmark, re-sulting in a 2nd place finish in the 2019 DAVIS challengeon semi-supervised VOS.
@article{LuitenDAVIS2019,
title={Combining PReMVOS with Box-Level Tracking for the 2019 DAVIS Challenge},
author={Luiten, Jonathon and Voigtlaender, Paul and Leibe, Bastian},
booktitle = {The 2019 DAVIS Challenge on Video Object Segmentation - CVPR Workshops},
year = {2019}
}
Exploring the Combination of PReMVOS, BoLTVOS and UnOVOST for the 2019 YouTube-VOS Challenge
Video Object Segmentation is the task of tracking and segmenting objects in a video given the first-frame mask of objects to be tracked. There have been a number of different successful paradigms for tackling this task, from creating object proposals and linking them in time as in PReMVOS, to detecting objects to be tracked conditioned on the given first-frame as in BoLTVOS, and creating tracklets based on motion consistency before merging these into long-term tracks as in UnOVOST. In this paper we explore how these three different approaches can be combined into a novel Video Object Segmentation algorithm. We evaluate our approach on the 2019 Youtube-VOS challenge where we obtain 6th place with an overall score of 71.5%.
@inproceedings{Luiten19ICCVW_Video,
author = {Jonathon Luiten and Paul Voigtlaender and Bastian Leibe},
title = {{Exploring the Combination of PReMVOS, BoLTVOS and UnOVOST for the 2019 YouTube-VOS Challenge}},
booktitle = {The 2nd Large-scale Video Object Segmentation Challenge: International Conference on Computer Vision Workshop (ICCVW)},
year = {2019},
}
BoLTVOS: Box-Level Tracking for Video Object Segmentation

We approach video object segmentation (VOS) by splitting the task into two sub-tasks: bounding box level tracking, followed by bounding box segmentation. Following this paradigm, we present BoLTVOS (Box Level Tracking for VOS), which consists of an R-CNN detector conditioned on the first-frame bounding box to detect the object of interest, a temporal consistency rescoring algorithm, and a Box2Seg network that converts bounding boxes to segmentation masks. BoLTVOS performs VOS using only the first-frame bounding box without the mask. We evaluate our approach on DAVIS 2017 and YouTube-VOS, and show that it outperforms all methods that do not perform first-frame fine-tuning. We further present BoLTVOS-ft, which learns to segment the object in question using the first-frame mask while it is being tracked, without increasing the runtime. BoLTVOS-ft outperforms PReMVOS, the previously best performing VOS method on DAVIS 2016 and YouTube-VOS, while running up to 45 times faster. Our bounding box tracker also outperforms all previous short-term and longterm trackers on the bounding box level tracking datasets OTB 2015 and LTB35.
@article{VoigtlaenderLuiten19arxiv,
author = {Paul Voigtlaender and Jonathon Luiten and Bastian Leibe},
title = {{BoLTVOS: Box-Level Tracking for Video Object Segmentation}},
journal = {arXiv:1904.04552},
year = {2019}
}
PReMVOS: Proposal-generation, Refinement and Merging for Video Object Segmentation
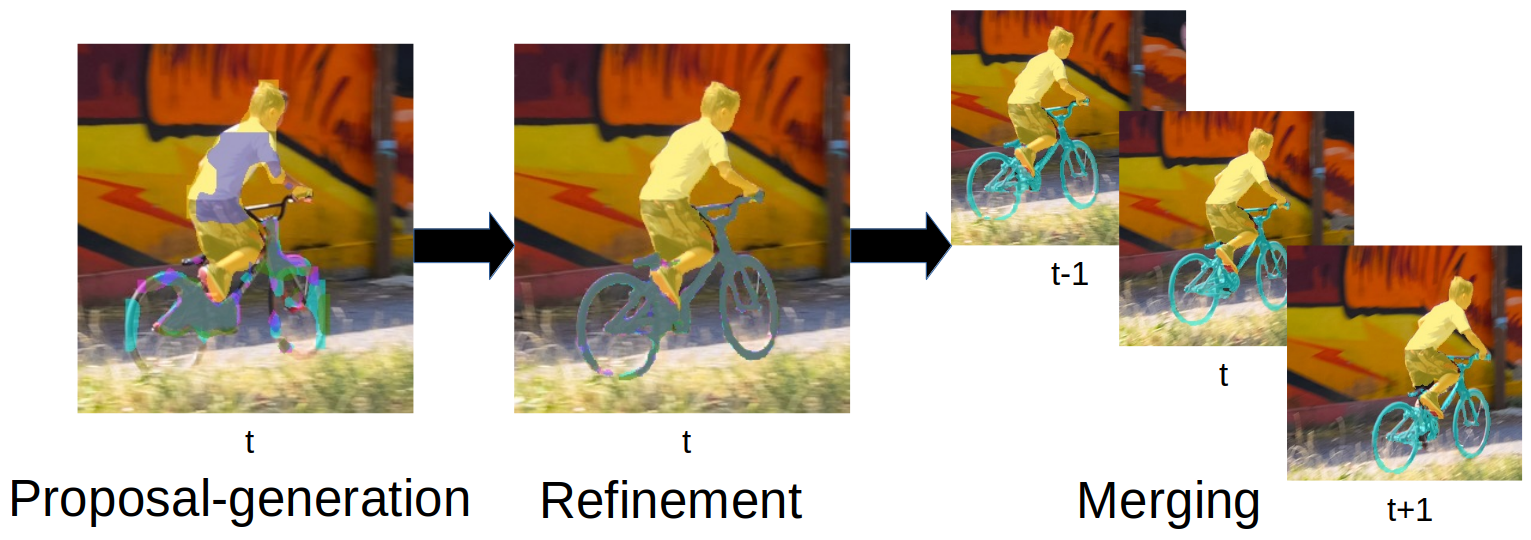
We address semi-supervised video object segmentation, the task of automatically generating accurate and consistent pixel masks for objects in a video sequence, given the first-frame ground truth annotations. Towards this goal, we present the PReMVOS algorithm (Proposalgeneration, Refinement and Merging for Video Object Segmentation). Our method separates this problem into two steps, first generating a set of accurate object segmentation mask proposals for each video frame and then selecting and merging these proposals into accurate and temporally consistent pixel-wise object tracks over a video sequence in a way which is designed to specifically tackle the difficult challenges involved with segmenting multiple objects across a video sequence. Our approach surpasses all previous state-of-the-art results on the DAVIS 2017 video object egmentation benchmark with a J & F mean score of 71.6 on the test-dev dataset, and achieves first place in both the DAVIS 2018 Video Object Segmentation Challenge and the YouTube-VOS 1st Large-scale Video Object Segmentation Challenge.
@inproceedings{luiten2018premvos,
title={PReMVOS: Proposal-generation, Refinement and Merging for Video Object Segmentation},
author={Jonathon Luiten and Paul Voigtlaender and Bastian Leibe},
booktitle={Asian Conference on Computer Vision},
year={2018}
}
Track, then Decide: Category-Agnostic Vision-based Multi-Object Tracking

The most common paradigm for vision-based multi-object tracking is tracking-by-detection, due to the availability of reliable detectors for several important object categories such as cars and pedestrians. However, future mobile systems will need a capability to cope with rich human-made environments, in which obtaining detectors for every possible object category would be infeasible. In this paper, we propose a model-free multi-object tracking approach that uses a category-agnostic image segmentation method to track objects. We present an efficient segmentation mask-based tracker which associates pixel-precise masks reported by the segmentation. Our approach can utilize semantic information whenever it is available for classifying objects at the track level, while retaining the capability to track generic unknown objects in the absence of such information. We demonstrate experimentally that our approach achieves performance comparable to state-of-the-art tracking-by-detection methods for popular object categories such as cars and pedestrians. Additionally, we show that the proposed method can discover and robustly track a large variety of other objects.
@article{Osep18ICRA,
author = {O\v{s}ep, Aljo\v{s}a and Mehner, Wolfgang and Voigtlaender, Paul and Leibe, Bastian},
title = {Track, then Decide: Category-Agnostic Vision-based Multi-Object Tracking},
journal = {ICRA},
year = {2018}
}
PReMVOS: Proposal-generation, Refinement and Merging for the DAVIS Challenge on Video Object Segmentation 2018
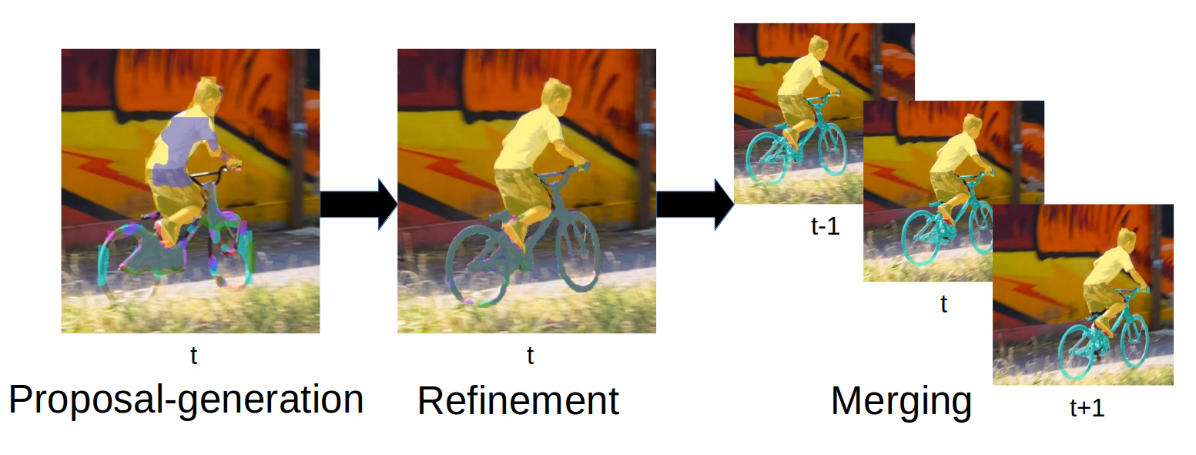
We address semi-supervised video object segmentation, the task of automatically generating accurate and consistent pixel masks for objects in a video sequence, given the first-frame ground truth annotations. Towards this goal, we present the PReMVOS algorithm (Proposal-generation, Refinement and Merging for Video Object Segmentation). This method involves generating coarse object proposals using a Mask R-CNN like object detector, followed by a refinement network that produces accurate pixel masks for each proposal. We then select and link these proposals over time using a merging algorithm that takes into account an objectness score, the optical flow warping, and a Re-ID feature embedding vector for each proposal. We adapt our networks to the target video domain by fine-tuning on a large set of augmented images generated from the first-frame ground truth. Our approach surpasses all previous state-of-the-art results on the DAVIS 2017 video object segmentation benchmark and achieves first place in the DAVIS 2018 Video Object Segmentation Challenge with a mean of J & F score of 74.7.
@article{Luiten18CVPRW,
author = {Jonathon Luiten and Paul Voigtlaender and Bastian Leibe},
title = {{PReMVOS: Proposal-generation, Refinement and Merging for the DAVIS Challenge on Video Object Segmentation 2018}},
journal = {The 2018 DAVIS Challenge on Video Object Segmentation - CVPR Workshops},
year = {2018}
}
PReMVOS: Proposal-generation, Refinement and Merging for the YouTube-VOS Challenge on Video Object Segmentation 2018
We evaluate our PReMVOS algorithm [1]2 on the new YouTube-VOS dataset [3] for the task of semi-supervised video object segmentation (VOS). This task consists of automatically generating accurate and consistent pixel masks for multiple objects in a video sequence, given the object’s first-frame ground truth annotations. The new YouTube-VOS dataset and the corresponding challenge, the 1st Large-scale Video Object Segmentation Challenge, provide a much larger scale evaluation than any previous VOS benchmarks. Our method achieves the best results in the 2018 Large-scale Video Object Segmentation Challenge with a J &F overall mean score over both known and unknown categories of 72.2.
@article{Luiten18ECCVW,
author = {Jonathon Luiten and Paul Voigtlaender and Bastian Leibe},
title = {{PReMVOS: Proposal-generation, Refinement and Merging for the YouTube-VOS Challenge on Video Object Segmentation 2018}},
journal = {The 1st Large-scale Video Object Segmentation Challenge - ECCV Workshops},
year = {2018}
}
Towards Large-Scale Video Video Object Mining
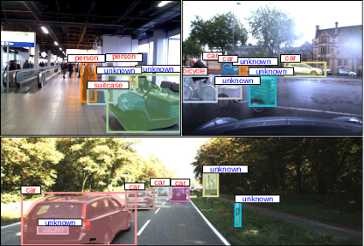
We propose to leverage a generic object tracker in order to perform object mining in large-scale unlabeled videos, captured in a realistic automotive setting. We present a dataset of more than 360'000 automatically mined object tracks from 10+ hours of video data (560'000 frames) and propose a method for automated novel category discovery and detector learning. In addition, we show preliminary results on using the mined tracks for object detector adaptation.
@article{OsepVoigtlaender18ECCVW,
title={Towards Large-Scale Video Object Mining},
author={Aljo\v{s}a O\v{s}ep and Paul Voigtlaender and Jonathon Luiten and Stefan Breuers and Bastian Leibe},
journal={ECCV 2018 Workshop on Interactive and Adaptive Learning in an Open World},
year={2018}
}
Iteratively Trained Interactive Segmentation
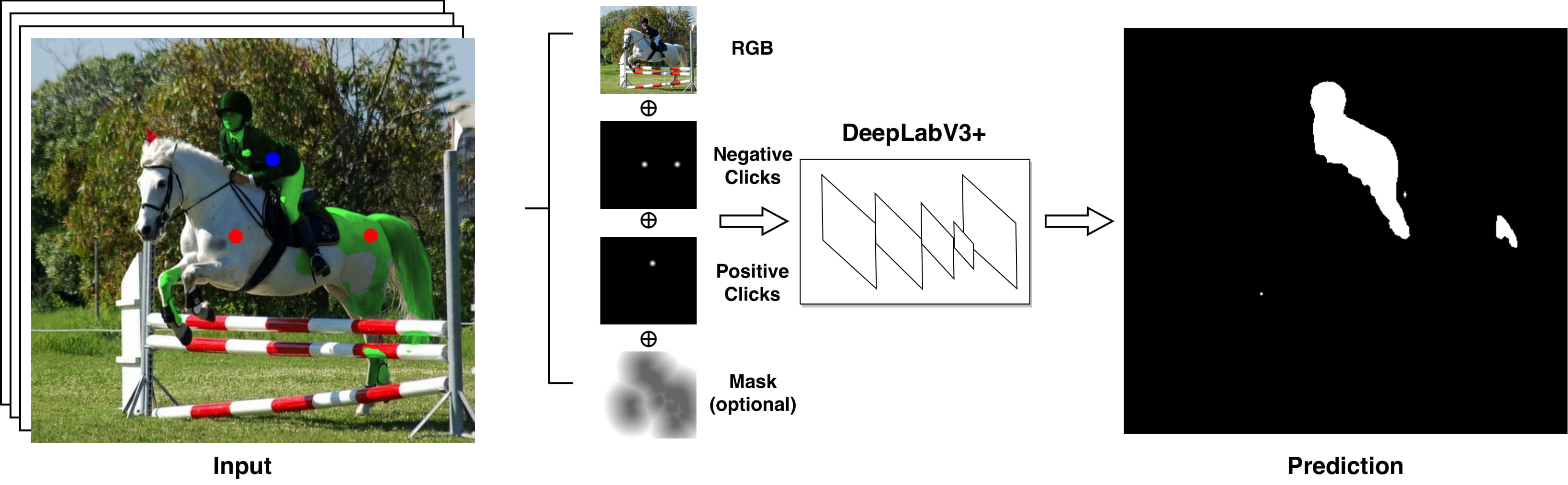
Deep learning requires large amounts of training data to be effective. For the task of object segmentation, manually labeling data is very expensive, and hence interactive methods are needed. Following recent approaches, we develop an interactive object segmentation system which uses user input in the form of clicks as the input to a convolutional network. While previous methods use heuristic click sampling strategies to emulate user clicks during training, we propose a new iterative training strategy. During training, we iteratively add clicks based on the errors of the currently predicted segmentation. We show that our iterative training strategy together with additional improvements to the network architecture results in improved results over the state-of-the-art.
Large-Scale Object Discovery and Detector Adaptation from Unlabeled Video
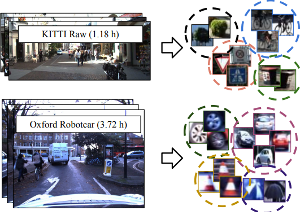
We explore object discovery and detector adaptation based on unlabeled video sequences captured from a mobile platform. We propose a fully automatic approach for object mining from video which builds upon a generic object tracking approach. By applying this method to three large video datasets from autonomous driving and mobile robotics scenarios, we demonstrate its robustness and generality. Based on the object mining results, we propose a novel approach for unsupervised object discovery by appearance-based clustering. We show that this approach successfully discovers interesting objects relevant to driving scenarios. In addition, we perform self-supervised detector adaptation in order to improve detection performance on the KITTI dataset for existing categories. Our approach has direct relevance for enabling large-scale object learning for autonomous driving.
@article{OsepVoigtlaender18arxiv,
title={Large-Scale Object Discovery and Detector Adaptation from Unlabeled Video},
author={Aljo\v{s}a O\v{s}ep and Paul Voigtlaender and Jonathon Luiten and Stefan Breuers and Bastian Leibe},
journal={arXiv preprint arXiv:1712.08832},
year={2018}
}
Online Adaptation of Convolutional Neural Networks for Video Object Segmentation

We tackle the task of semi-supervised video object segmentation, i.e. segmenting the pixels belonging to an object in the video using the ground truth pixel mask for the first frame. We build on the recently introduced one-shot video object segmentation (OSVOS) approach which uses a pretrained network and fine-tunes it on the first frame. While achieving impressive performance, at test time OSVOS uses the fine-tuned network in unchanged form and is not able to adapt to large changes in object appearance. To overcome this limitation, we propose Online Adaptive Video Object Segmentation (OnAVOS) which updates the network online using training examples selected based on the confidence of the network and the spatial configuration. Additionally, we add a pretraining step based on objectness, which is learned on PASCAL. Our experiments show that both extensions are highly effective and improve the state of the art on DAVIS to an intersection-over-union score of 85.7%.
@inproceedings{voigtlaender17BMVC,
author = {Paul Voigtlaender and Bastian Leibe},
title = {Online Adaptation of Convolutional Neural Networks for Video Object Segmentation},
booktitle = {BMVC},
year = {2017}
}
Online Adaptation of Convolutional Neural Networks for the 2017 DAVIS Challenge on Video Object Segmentation
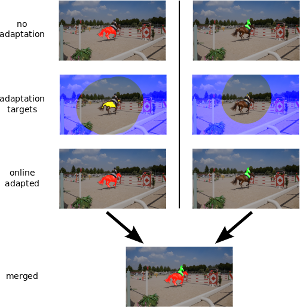
This paper describes our method used for the 2017 DAVIS Challenge on Video Object Segmentation [26]. The challenge’s task is to segment the pixels belonging to multiple objects in a video using the ground truth pixel masks, which are given for the first frame. We build on our recently proposed Online Adaptive Video Object Segmentation (OnAVOS) method which pretrains a convolutional neural network for objectness, fine-tunes it on the first frame, and further updates the network online while processing the video. OnAVOS selects confidently predicted foreground pixels as positive training examples and pixels, which are far away from the last assumed object position as negative examples. While OnAVOS was designed to work with a single object, we extend it to handle multiple objects by combining the predictions of multiple single-object runs. We introduce further extensions including upsampling layers which increase the output resolution. We achieved the fifth place out of 22 submissions to the competition.
@article{voigtlaender17DAVIS,
author = {Paul Voigtlaender and Bastian Leibe},
title = {Online Adaptation of Convolutional Neural Networks for the 2017 DAVIS Challenge on Video Object Segmentation},
journal = {The 2017 DAVIS Challenge on Video Object Segmentation - CVPR Workshops},
year = {2017}
}
RETURNN: The RWTH Extensible Training Framework for Universal Recurrent Neural Networks
In this work we release our extensible and easily configurable neural network training software. It provides a rich set of functional layers with a particular focus on efficient training of recurrent neural network topologies on multiple GPUs. The source of the software package is public and freely available for academic research purposes and can be used as a framework or as a standalone tool which supports a flexible configuration. The software allows to train state-of-the-art deep bidirectional long short-term memory (LSTM) models on both one dimensional data like speech or two dimensional data like handwritten text and was used to develop successful submission systems in several evaluation campaigns.
@inproceedings{doetsch2017returnn,
title={RETURNN: the RWTH extensible training framework for universal recurrent neural networks},
author={Doetsch, Patrick and Zeyer, Albert and Voigtlaender, Paul and Kulikov, Ilya and Schl{\"u}ter, Ralf and Ney, Hermann},
booktitle={IEEE International Conference on Acoustics, Speech, and Signal Processing},
year={2017},
month=mar,
pages={5345--5349}
}
A Comprehensive Study of Deep Bidirectional LSTM RNNs for Acoustic Modeling in Speech Recognition
Recent experiments show that deep bidirectional long short-term memory (BLSTM) recurrent neural network acoustic models outperform feedforward neural networks for automatic speech recognition (ASR). However, their training requires a lot of tuning and experience. In this work, we provide a comprehensive overview over various BLSTM training aspects and their interplay within ASR, which has been missing so far in the literature. We investigate on different variants of optimization methods, batching, truncated backpropagation, and regularization techniques such as dropout, and we study the effect of size and depth, training models of up to 10 layers. This includes a comparison of computation times vs. recognition performance. Furthermore, we introduce a pretraining scheme for LSTMs with layer-wise construction of the network showing good improvements especially for deep networks. The experimental analysis mainly was performed on the Quaero task, with additional results on Switchboard. The best BLSTM model gave a relative improvement in word error rate of over 15% compared to our best feed-forward baseline on our Quaero 50h task. All experiments were done using RETURNN and RASR, RWTH’s extensible training framework for universal recurrent neural networks and ASR toolkit. The training configuration files are publicly available.
@inproceedings{zeyer2017lstm,
title={A comprehensive study of deep bidirectional LSTM RNNs for acoustic modeling in speech recognition},
author={Zeyer, Albert and Doetsch, Patrick and Voigtlaender, Paul and Schl{\"u}ter, Ralf and Ney, Hermann},
booktitle={IEEE International Conference on Acoustics, Speech, and Signal Processing},
year={2017},
month=mar,
pages={2462--2466}
}
Handwriting Recognition with Large Multidimensional Long Short-Term Memory Recurrent Neural Networks
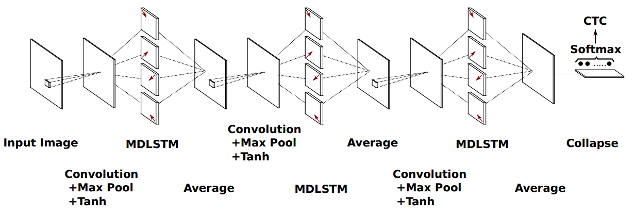
Multidimensional long short-term memory recurrent neural networks achieve impressive results for handwriting recognition. However, with current CPU-based implementations, their training is very expensive and thus their capacity has so far been limited. We release an efficient GPU-based implementation which greatly reduces training times by processing the input in a diagonal-wise fashion. We use this implementation to explore deeper and wider architectures than previously used for handwriting recognition and show that especially the depth plays an important role. We outperform state of the art results on two databases with a deep multidimensional network.
@InProceedings { voigtlaender16:mdlstm,
author= {Voigtlaender, Paul and Doetsch, Patrick and Ney, Hermann},
title= {Handwriting Recognition with Large Multidimensional Long Short-Term Memory Recurrent Neural Networks},
booktitle= {International Conference on Frontiers in Handwriting Recognition},
year= 2016,
pages= {228-233},
address= {Shenzhen, China},
month= oct,
note= {IAPR Best Student Paper Award},
booktitlelink= {http://www.nlpr.ia.ac.cn/icfhr2016/}
}
Sequence-Discriminative Training of Recurrent Neural Networks
We investigate sequence-discriminative training of long short-term memory recurrent neural networks using the maximum mutual information criterion. We show that although recurrent neural networks already make use of the whole observation sequence and are able to incorporate more contextual information than feed forward networks, their performance can be improved with sequence-discriminative training. Experiments are performed on two publicly available handwriting recognition tasks containing English and French handwriting. On the English corpus, we obtain a relative improvement in WER of over 11% with maximum mutual information (MMI) training compared to cross-entropy training. On the French corpus, we observed that it is necessary to interpolate the MMI objective function with cross-entropy.
@InProceedings { voigtlaender2015:seq,
author= {Voigtlaender, Paul and Doetsch, Patrick and Wiesler, Simon and Schlüter, Ralf and Ney, Hermann},
title= {Sequence-Discriminative Training of Recurrent Neural Networks},
booktitle= {IEEE International Conference on Acoustics, Speech, and Signal Processing},
year= 2015,
pages= {2100-2104},
address= {Brisbane, Australia},
month= apr,
booktitlelink= {http://icassp2015.org/}
}
