
Publications
Towards Multi-View Object Class Detection
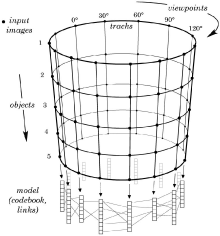
We present a novel system for generic object class de- tection. In contrast to most existing systems which focus on a single viewpoint or aspect, our approach can detect ob- ject instances from arbitrary viewpoints. This is achieved by combining the Implicit Shape Model for object class de- tection proposed by Leibe and Schiele with the multi-view specific object recognition system of Ferrari et al. After learning single-view codebooks, these are inter- connected by so-called activation links, obtained through multi-view region tracks across different training views of individual object instances. During recognition, these inte- grated codebooks work together to determine the location and pose of the object. Experimental results demonstrate the viability of the approach and compare it to a bank of independent single-view detectors.
Multi-Aspect Detection of Articulated Objects
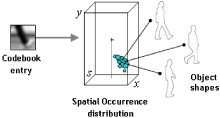
A wide range of methods have been proposed to detect and recognize objects. However, effective and efficient multi- viewpoint detection of objects is still in its infancy, since most current approaches can only handle single viewpoints or as- pects. This paper proposes a general approach for multi- aspect detection of objects. As the running example for de- tection we use pedestrians, which add another difficulty to the problem, namely human body articulations. Global ap- pearance changes caused by different articulations and view- points of pedestrians are handled in a unified manner by a generalization of the Implicit Shape Model [5]. An important property of this new approach is to share local appearance across different articulations and viewpoints, therefore re- quiring relatively few training samples. The effectiveness of the approach is shown and compared to previous approaches on two datasets containing pedestrians with different articu- lations and from multiple viewpoints.
Multiple Object Class Detection with a Generative Model

In this paper we propose an approach capable of si- multaneous recognition and localization of multiple object classes using a generative model. A novel hierarchical rep- resentation allows to represent individual images as well as various objects classes in a single, scale and rotation invari- ant model. The recognition method is based on a codebook representation where appearance clusters built from edge based features are shared among several object classes. A probabilistic model allows for reliable detection of various objects in the same image. The approach is highly effi- cient due to fast clustering and matching methods capable of dealing with millions of high dimensional features. The system shows excellent performance on several object cate- gories over a wide range of scales, in-plane rotations, back- ground clutter, and partial occlusions. The performance of the proposed multi-object class detection approach is com- petitive to state of the art approaches dedicated to a single object class recognition problem.
3D City Modeling Using Cognitive Loops

3D city modeling using computer vision is very chal- lenging. A typical city contains objects which are a night- mare for some vision algorithms, while other algorithms have been designed to identify exactly these parts but, in their turn, suffer from other weaknesses which limit their application. For instance, moving cars with metallic sur- faces can degrade the results of a 3D city reconstruction algorithm which is primarily based on the assumption of a static scene with diffuse reflection properties. On the other hand, a specialized object recognition algorithm could be able to detect cars, but also yields too many false positives without the availability of additional scene knowledge. In this paper, the design of a cognitive loop which intertwines both aforementioned algorithms is demonstrated for 3D city modeling, proving that the whole can be much more than the simple sum of its parts. A cognitive loop is the mutual trans- fer of higher knowledge between algorithms, which enables the combination of algorithms to overcome the weaknesses of any single algorithm. We demonstrate the promise of this approach on a real-world city modeling task using video data recorded by a survey vehicle. Our results show that the cognitive combination of algorithms delivers convincing city models which improve upon the degree of realism that is possible from a purely reconstruction-based approach.
Efficient Clustering and Matching for Object Class Recognition
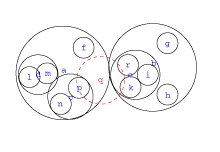
In this paper we address the problem of building object class representations based on local features and fast matching in a large database. We propose an efficient algorithm for hierarchical agglomerative clustering. We examine different agglomerative and partitional clustering strategies and compare the quality of obtained clusters. Our combination of partitional-agglomerative clustering gives significant improvement in terms of efficiency while main- taining the same quality of clusters. We also propose a method for building data structures for fast matching in high dimensional feature spaces. These improvements allow to deal with large sets of training data typically used in recognition of multiple object classes.
Segmentation Based Multi-Cue Integration for Object Detection

This paper proposes a novel method for integrating multiple local cues, i.e. lo- cal region detectors as well as descriptors, in the context of object detection. Rather than to fuse the outputs of several distinct classifiers in a fixed setup, our approach implements a highly flexible combination scheme, where the con- tributions of all individual cues are flexibly recombined depending on their ex- planatory power for each new test image. The key idea behind our approach is to integrate the cues over an estimated top-down segmentation, which allows to quantify how much each of them contributed to the object hypothesis. By combining those contributions on a per-pixel level, our approach ensures that each cue only contributes to object regions for which it is confident and that potential correlations between cues are effectively factored out. Experimental results on several benchmark data sets show that the proposed multi-cue combi- nation scheme significantly increases detection performance compared to any of its constituent cues alone. Moreover, it provides an interesting evaluation tool to analyze the complementarity of local feature detectors and descriptors.
Integrating Recognition and Reconstruction for Cognitive Traffic Scene Analysis from a Moving Vehicle

This paper presents a practical system for vision-based traffic scene analysis from a moving vehicle based on a cognitive feedback loop which in- tegrates real-time geometry estimation with appearance-based object detection. We demonstrate how those two components can benefit from each other’s con- tinuous input and how the transferred knowledge can be used to improve scene analysis. Thus, scene interpretation is not left as a matter of logical reasoning, but is instead addressed by the repeated interaction and consistency checks between different levels and modes of visual processing. As our results show, the proposed tight integration significantly increases recognition performance, as well as over- all system robustness. In addition, it enables the construction of novel capabilities such as the accurate 3D estimation of object locations and orientations and their temporal integration in a world coordinate frame. The system is evaluated on a challenging real-world car detection task in an urban scenario.
Previous Year (2005)
