
Profile

|
Dr. Jörg Stückler |
I am postdoctoral researcher in the Computer Vision Group (CVG) within the Visual Computing Institute at RWTH Aachen University.
My research interests include robotics, robot/computer vision and machine learning.
Before joining the CVG at RWTH Aachen University, I have been a postdoctoral researcher in the CVG at TU Munich from Sept. 2014 to Sept 2015. I've obtained a PhD from University of Bonn in September 2014, where I have been working as a research associate in the Autonomous Intelligent Systems group. During my time as a PhD student I have been team leader of very successful RoboCup Humanoid Soccer and RoboCup@Home teams. For my PhD thesis on RGB-D environment perception I have received the prestigious 2015 Georges Giralt Award from euRobotics aisbl for an outstanding thesis in European robotics.
The publications list below only contains my recent publications from 2015 on.
Detailed and more complete lists of my publications can be found on my google scholar profile and on dblp.
Former profile at TUM (2014-2015)
Former profile at the University of Bonn (2008-2014)
Teaching:
- In summer term 2017, I will offer a lab course on Deep Robot Learning.
- In summer term 2016, I have been lecturing on visual odometry, SLAM and 3D reconstruction in the lecture Computer Vision 2 at RWTH Aachen University.
Publications
Semi-Supervised Deep Learning for Monocular Depth Map Prediction
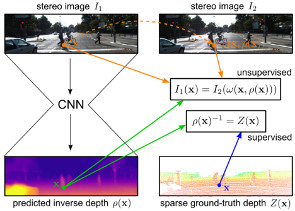
Supervised deep learning often suffers from the lack of sufficient training data. Specifically in the context of monocular depth map prediction, it is barely possible to determine dense ground truth depth images in realistic dynamic outdoor environments. When using LiDAR sensors, for instance, noise is present in the distance measurements, the calibration between sensors cannot be perfect, and the measurements are typically much sparser than the camera images. In this paper, we propose a novel approach to depth map prediction from monocular images that learns in a semi-supervised way. While we use sparse ground-truth depth for supervised learning, we also enforce our deep network to produce photoconsistent dense depth maps in a stereo setup using a direct image alignment loss. In experiments we demonstrate superior performance in depth map prediction from single images compared to the state-of-the-art methods.
» Show BibTeX
@inproceedings{kuznietsov2017_semsupdepth,
title = {Semi-Supervised Deep Learning for Monocular Depth Map Prediction},
author = {Kuznietsov, Yevhen and St\"uckler, J\"org and Leibe, Bastian},
booktitle = {IEEE International Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2017}
}
Multi-View Deep Learning for Consistent Semantic Mapping with RGB-D Cameras
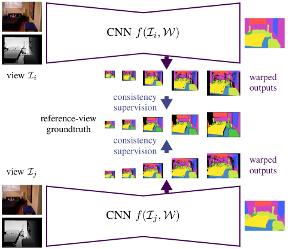
Visual scene understanding is an important capability that enables robots to purposefully act in their environment. In this paper, we propose a novel deep neural network approach to predict semantic segmentation from RGB-D sequences. The key innovation is to train our network to predict multi-view consistent semantics in a self-supervised way. At test time, its semantics predictions can be fused more consistently in semantic keyframe maps than predictions of a network trained on individual views. We base our network architecture on a recent single-view deep learning approach to RGB and depth fusion for semantic object-class segmentation and enhance it with multi-scale loss minimization. We obtain the camera trajectory using RGB-D SLAM and warp the predictions of RGB-D images into ground-truth annotated frames in order to enforce multi-view consistency during training. At test time, predictions from multiple views are fused into keyframes. We propose and analyze several methods for enforcing multi-view consistency during training and testing. We evaluate the benefit of multi-view consistency training and demonstrate that pooling of deep features and fusion over multiple views outperforms single-view baselines on the NYUDv2 benchmark for semantic segmentation. Our end-to-end trained network achieves state-of-the-art performance on the NYUDv2 dataset in single-view segmentation as well as multi-view semantic fusion.
@string{iros="International Conference on Intelligent Robots and Systems (IROS)"}
@InProceedings{lingni17iros,
author = "Lingni Ma and J\"org St\"uckler and Christian Kerl and Daniel Cremers",
title = "Multi-View Deep Learning for Consistent Semantic Mapping with RGB-D Cameras",
booktitle = "IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS)",
year = "2017",
}
Keyframe-Based Visual-Inertial Online SLAM with Relocalization
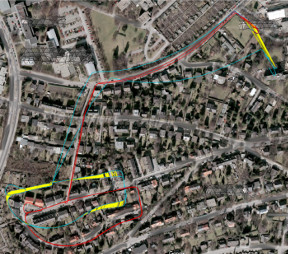
Complementing images with inertial measurements has become one of the most popular approaches to achieve highly accurate and robust real-time camera pose tracking. In this paper, we present a keyframe-based approach to visual-inertial simultaneous localization and mapping (SLAM) for monocular and stereo cameras. Our method is based on a real-time capable visual-inertial odometry method that provides locally consistent trajectory and map estimates. We achieve global consistency in the estimate through online loop-closing and non-linear optimization. Furthermore, our approach supports relocalization in a map that has been previously obtained and allows for continued SLAM operation. We evaluate our approach in terms of accuracy, relocalization capability and run-time efficiency on public benchmark datasets and on newly recorded sequences. We demonstrate state-of-the-art performance of our approach towards a visual-inertial odometry method in recovering the trajectory of the camera.
@article{Kasyanov2017_VISLAM,
title={{Keyframe-Based Visual-Inertial Online SLAM with Relocalization}},
author={Anton Kasyanov and Francis Engelmann and J\"org St\"uckler and Bastian Leibe},
booktitle={{IEEE/RSJ} International Conference on Intelligent Robots and Systems {(IROS)}},
year={2017}
}
SAMP: Shape and Motion Priors for 4D Vehicle Reconstruction

Inferring the pose and shape of vehicles in 3D from a movable platform still remains a challenging task due to the projective sensing principle of cameras, difficult surface properties, e.g. reflections or transparency, and illumination changes between images. In this paper, we propose to use 3D shape and motion priors to regularize the estimation of the trajectory and the shape of vehicles in sequences of stereo images. We represent shapes by 3D signed distance functions and embed them in a low-dimensional manifold. Our optimization method allows for imposing a common shape across all image observations along an object track. We employ a motion model to regularize the trajectory to plausible object motions. We evaluate our method on the KITTI dataset and show state-of-the-art results in terms of shape reconstruction and pose estimation accuracy.
@inproceedings{EngelmannWACV17_samp,
author = {Francis Engelmann and J{\"{o}}rg St{\"{u}}ckler and Bastian Leibe},
title = {{SAMP:} Shape and Motion Priors for 4D Vehicle Reconstruction},
booktitle = {{IEEE} Winter Conference on Applications of Computer Vision,
{WACV}},
year = {2017}
}
From Monocular SLAM to Autonomous Drone Exploration
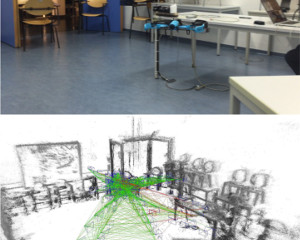
Micro aerial vehicles (MAVs) are strongly limited in their payload and power capacity. In order to implement autonomous navigation, algorithms are therefore desirable that use sensory equipment that is as small, low-weight, and low- power consuming as possible. In this paper, we propose a method for autonomous MAV navigation and exploration using a low-cost consumer-grade quadrocopter equipped with a monocular camera. Our vision-based navigation system builds on LSD-SLAM which estimates the MAV trajectory and a semi-dense reconstruction of the environment in real-time. Since LSD-SLAM only determines depth at high gradient pixels, texture-less areas are not directly observed. We propose an obstacle mapping and exploration approach that takes this property into account. In experiments, we demonstrate our vision-based autonomous navigation and exploration system with a commercially available Parrot Bebop MAV.
» Show BibTeX
@inproceedings{stumberg2017_mavexplore,
author={Lukas von Stumberg and Vladyslav Usenko and Jakob Engel and J\"org St\"uckler and Daniel Cremers},
title={From Monoular {SLAM} to Autonomous Drone Exploration},
booktitle = {Accepted for the European Conference on Mobile Robots (ECMR)},
year = {2017},
}
Unsupervised Learning of Shape-Motion Patterns for Objects in Urban Street Scenes
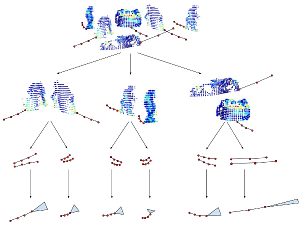
Tracking in urban street scenes is predominantly based on pretrained object-specific detectors and Kalman filter based tracking. More recently, methods have been proposed that track objects by modelling their shape, as well as ones that predict the motion of ob- jects using learned trajectory models. In this paper, we combine these ideas and propose shape-motion patterns (SMPs) that incorporate shape as well as motion to model a vari- ety of objects in an unsupervised way. By using shape, our method can learn trajectory models that distinguish object categories with distinct behaviour. We develop methods to classify objects into SMPs and to predict future motion. In experiments, we analyze our learned categorization and demonstrate superior performance of our motion predictions compared to a Kalman filter and a learned pure trajectory model. We also demonstrate how SMPs can indicate potentially harmful situations in traffic scenarios.
» Show BibTeX
@inproceedings{klostermann2016_smps,
title = {Unsupervised Learning of Shape-Motion Patterns for Objects in Urban Street Scenes},
author = {Dirk Klostermann and Aljosa Osep and J\"org St\"uckler and Bastian Leibe},
booktitle = {Proc. of the British Machine Vision Conference (BMVC)},
year = {2016}, note = {to appear}
}
Scene Flow Propagation for Semantic Mapping and Object Discovery in Dynamic Street Scenes

Scene understanding is an important prerequisite for vehicles and robots that operate autonomously in dynamic urban street scenes. For navigation and high-level behavior planning, the robots not only require a persistent 3D model of the static surroundings - equally important, they need to perceive and keep track of dynamic objects. In this paper, we propose a method that incrementally fuses stereo frame observations into temporally consistent semantic 3D maps. In contrast to previous work, our approach uses scene flow to propagate dynamic objects within the map. Our method provides a persistent 3D occupancy as well as semantic belief on static as well as moving objects. This allows for advanced reasoning on objects despite noisy single-frame observations and occlusions. We develop a novel approach to discover object instances based on the temporally consistent shape, appearance, motion, and semantic cues in our maps. We evaluate our approaches to dynamic semantic mapping and object discovery on the popular KITTI benchmark and demonstrate improved results compared to single-frame methods.
» Show BibTeX
@inproceedings{kochanov2016_sceneflowprop,
title = {Scene Flow Propagation for Semantic Mapping and Object Discovery in Dynamic Street Scenes},
author = {Deyvid Kochanov and Aljosa Osep and J\"org St\"uckler and Bastian Leibe},
booktitle = {Proc. of the IEEE Int. Conf. on Intelligent Robots and Systems (IROS)}, year = {2016},
note = {to appear}
}
Joint Object Pose Estimation and Shape Reconstruction in Urban Street Scenes Using 3D Shape Priors

Estimating the pose and 3D shape of a large variety of instances within an object class from stereo images is a challenging problem, especially in realistic conditions such as urban street scenes. We propose a novel approach for using compact shape manifolds of the shape within an object class for object segmentation, pose and shape estimation. Our method first detects objects and estimates their pose coarsely in the stereo images using a state-of-the-art 3D object detection method. An energy minimization method then aligns shape and pose concurrently with the stereo reconstruction of the object. In experiments, we evaluate our approach for detection, pose and shape estimation of cars in real stereo images of urban street scenes. We demonstrate that our shape manifold alignment method yields improved results over the initial stereo reconstruction and object detection method in depth and pose accuracy.
» Show BibTeX
@inproceedings{EngelmannGCPR16_shapepriors,
title = {Joint Object Pose Estimation and Shape Reconstruction in Urban Street Scenes Using {3D} Shape Priors},
author = {Francis Engelmann and J\"org St\"uckler and Bastian Leibe},
booktitle = {Proc. of the German Conference on Pattern Recognition (GCPR)},
year = {2016}}
CPA-SLAM: Consistent Plane-Model Alignment for Direct RGB-D SLAM
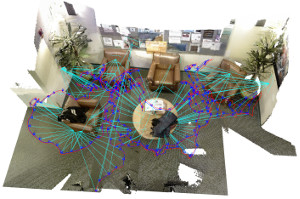
Planes are predominant features of man-made environments which have been exploited in many mapping approaches. In this paper, we propose a real-time capable RGB-D SLAM system that consistently integrates frame-to-keyframe and frame-to-plane alignment. Our method models the environment with a global plane model and – besides direct image alignment – it uses the planes for tracking and global graph optimization. This way, our method makes use of the dense image information available in keyframes for accurate short-term tracking. At the same time it uses a global model to reduce drift. Both components are integrated consistently in an expectation-maximization framework. In experiments, we demonstrate the benefits our approach and its state-of-the-art accuracy on challenging benchmarks.
@InProceedings{lingni16icra,
author = "L. Ma and C. Kerl and J. Stueckler and D. Cremers",
title = "CPA-SLAM: Consistent Plane-Model Alignment for Direct RGB-D SLAM",
booktitle = "Int. Conf. on Robotics and Automation",
year = "2016",
month = "May",
}
Direct Visual-Inertial Odometry with Stereo Cameras
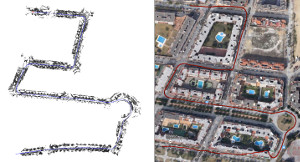
We propose a novel direct visual-inertial odometry method for stereo cameras. Camera pose, velocity and IMU biases are simultaneously estimated by minimizing a combined photometric and inertial energy functional. This allows us to exploit the complementary nature of vision and inertial data. At the same time, and in contrast to all existing visual-inertial methods, our approach is fully direct: geometry is estimated in the form of semi-dense depth maps instead of manually designed sparse keypoints. Depth information is obtained both from static stereo – relating the fixed-baseline images of the stereo camera – and temporal stereo – relating images from the same camera, taken at different points in time. We show that our method outperforms not only vision-only or loosely coupled approaches, but also can achieve more accurate results than state-of-the-art keypoint-based methods on different datasets, including rapid motion and significant illumination changes. In addition, our method provides high-fidelity semi-dense, metric reconstructions of the environment, and runs in real-time on a CPU.
» Show BibTeX
@InProceedings{usenko16icra,
title = "Direct Visual-Inertial Odometry with Stereo Cameras",
author = "V. Usenko and J. Engel and J. Stueckler and D. Cremers",
booktitle = {Int. Conf. on Robotics and Automation},
year = "2016",
}
Mobile Manipulation, Tool Use, and Intuitive Interaction for Cognitive Service Robot Cosero

Cognitive service robots that shall assist persons in need of performing their activities of daily living have recently received much attention in robotics research. Such robots require a vast set of control and perception capabilities to provide useful assistance through mobile manipulation and human–robot interaction. In this article, we present hardware design, perception, and control methods for our cognitive service robot Cosero. We complement autonomous capabilities with handheld teleoperation interfaces on three levels of autonomy. The robot demonstrated various advanced skills, including the use of tools. With our robot, we participated in the annual international RoboCup@Home competitions, winning them three times in a row.
» Show BibTeX
@ARTICLE{stueckler2016_cosero,
AUTHOR={St\"uckler, J\"org and Schwarz, Max and Behnke, Sven},
TITLE={Mobile Manipulation, Tool Use, and Intuitive Interaction for Cognitive Service Robot Cosero},
JOURNAL={Frontiers in Robotics and AI},
VOLUME={3},
PAGES={58},
YEAR={2016},
URL={http://journal.frontiersin.org/article/10.3389/frobt.2016.00058},
DOI={10.3389/frobt.2016.00058},
}
Efficient Dense Rigid-Body Motion Segmentation and Estimation in RGB-D Video

Motion is a fundamental grouping cue in video. Many current approaches to motion segmentation in monocular or stereo image sequences rely on sparse interest points or are dense but computationally demanding. We propose an efficient expectation-maximization (EM) framework for dense 3D segmentation of moving rigid parts in RGB-D video. Our approach segments images into pixel regions that undergo coherent 3D rigid-body motion. Our formulation treats background and foreground objects equally and poses no further assumptions on the motion of the camera or the objects than rigidness. While our EM-formulation is not restricted to a specific image representation, we supplement it with efficient image representation and registration for rapid segmentation of RGB-D video. In experiments, we demonstrate that our approach recovers segmentation and 3D motion at good precision.
@string{ijcv="International Journal of Computer Vision"}
@article{stueckler-ijcv15,
author = {J. Stueckler and S. Behnke},
title = {Efficient Dense Rigid-Body Motion Segmentation and Estimation in RGB-D Video},
journal = ijcv,
month = jan,
year = {2015},
doi = {10.1007/s11263-014-0796-3},
publisher = {Springer US},
}
NimbRo Explorer: Semi-Autonomous Exploration and Mobile Manipulation in Rough Terrain

Fully autonomous exploration and mobile manipulation in rough terrain are still beyond the state of the art—robotics challenges and competitions are held to facilitate and benchmark research in this direction. One example is the DLR SpaceBot Cup 2013, for which we developed an integrated robot system to semi-autonomously perform planetary exploration and manipulation tasks. Our robot explores, maps, and navigates in previously unknown, uneven terrain using a 3D laser scanner and an omnidirectional RGB-D camera. We developed manipulation capabilities for object retrieval and pick-and-place tasks. Many parts of the mission can be performed autonomously. In addition, we developed teleoperation interfaces on different levels of shared autonomy which allow for specifying missions, monitoring mission progress, and on-the-fly reconfiguration. To handle network communication interruptions and latencies between robot and operator station, we implemented a robust network layer for the middleware ROS. The integrated system has been demonstrated at the DLR SpaceBot Cup 2013. In addition, we conducted systematic experiments to evaluate the performance of our approaches.
» Show BibTeX
@article{stueckler15_jfr_explorer,
author={J. Stueckler and M. Schwarz and M. Schadler and A. Topalidou-Kyniazopoulou and S. Behnke},
title={NimbRo Explorer: Semi-Autonomous Exploration and Mobile Manipulation in Rough Terrain},
journal={Journal of Field Robotics},
note={published online},
year={2015},
}
Multi-Layered Mapping and Navigation for Autonomous Micro Aerial Vehicles

Micro aerial vehicles, such as multirotors, are particularly well suited for the autonomous monitoring, inspection, and surveillance of buildings, e.g., for maintenance or disaster management. Key prerequisites for the fully autonomous operation of micro aerial vehicles are real-time obstacle detection and planning of collision-free trajectories. In this article, we propose a complete system with a multimodal sensor setup for omnidirectional obstacle perception consisting of a 3D laser scanner, two stereo camera pairs, and ultrasonic distance sensors. Detected obstacles are aggregated in egocentric local multiresolution grid maps. Local maps are efficiently merged in order to simultaneously build global maps of the environment and localize in these. For autonomous navigation, we generate trajectories in a multi-layered approach: from mission planning over global and local trajectory planning to reactive obstacle avoidance. We evaluate our approach and the involved components in simulation and with the real autonomous micro aerial vehicle. Finally, we present the results of a complete mission for autonomously mapping a building and its surroundings.
@article{droeschel15-jfr-mod,
author={D. Droeschel and M. Nieuwenhuisen and M. Beul and J. Stueckler and D. Holz and S. Behnke},
title={Multi-Layered Mapping and Navigation for Autonomous Micro Aerial Vehicles},
journal={Journal of Field Robotics},
year={2015},
note={published online},
}
Dense Continuous-Time Tracking and Mapping with Rolling Shutter RGB-D Cameras
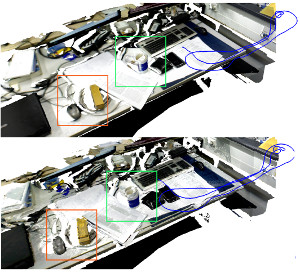
We propose a dense continuous-time tracking and mapping method for RGB-D cameras. We parametrize the camera trajectory using continuous B-splines and optimize the trajectory through dense, direct image alignment. Our method also directly models rolling shutter in both RGB and depth images within the optimization, which improves tracking and reconstruction quality for low-cost CMOS sensors. Using a continuous trajectory representation has a number of advantages over a discrete-time representation (e.g. camera poses at the frame interval). With splines, less variables need to be optimized than with a discrete represen- tation, since the trajectory can be represented with fewer control points than frames. Splines also naturally include smoothness constraints on derivatives of the trajectory estimate. Finally, the continuous trajectory representation allows to compensate for rolling shutter effects, since a pose estimate is available at any exposure time of an image. Our approach demonstrates superior quality in tracking and reconstruction compared to approaches with discrete-time or global shutter assumptions.
» Show BibTeX
@string{iccv="IEEE International Conference on Computer Vision (ICCV)"}
@inproceedings{kerl15iccv,
author = {C. Kerl and J. Stueckler and D. Cremers},
title = {Dense Continuous-Time Tracking and Mapping with Rolling Shutter {RGB-D} Cameras},
booktitle = iccv,
year = {2015},
address = {Santiago, Chile},
}
Motion Cooperation: Smooth Piece-Wise Rigid Scene Flow from RGB-D Images
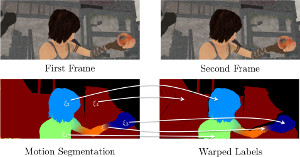
We propose a novel joint registration and segmentation approach to estimate scene flow from RGB-D images. In- stead of assuming the scene to be composed of a number of independent rigidly-moving parts, we use non-binary labels to capture non-rigid deformations at transitions between the rigid parts of the scene. Thus, the velocity of any point can be computed as a linear combination (interpolation) of the estimated rigid motions, which provides better results than traditional sharp piecewise segmentations. Within a variational framework, the smooth segments of the scene and their corresponding rigid velocities are alternately re- fined until convergence. A K-means-based segmentation is employed as an initialization, and the number of regions is subsequently adapted during the optimization process to capture any arbitrary number of independently moving ob- jects. We evaluate our approach with both synthetic and real RGB-D images that contain varied and large motions. The experiments show that our method estimates the scene flow more accurately than the most recent works in the field, and at the same time provides a meaningful segmentation of the scene based on 3D motion.
» Show BibTeX
@inproceedings{jaimez15_mocoop,
author= {M. Jaimez and M. Souiai and J. Stueckler and J. Gonzalez-Jimenez and D. Cremers},
title = {Motion Cooperation: Smooth Piece-Wise Rigid Scene Flow from RGB-D Images},
booktitle = {Proc. of the Int. Conference on 3D Vision (3DV)},
month = oct,
year = 2015,
}
Reconstructing Street-Scenes in Real-Time From a Driving Car

Most current approaches to street-scene 3D reconstruction from a driving car to date rely on 3D laser scanning or tedious offline computation from visual images. In this paper, we compare a real-time capable 3D reconstruction method using a stereo extension of large-scale di- rect SLAM (LSD-SLAM) with laser-based maps and traditional stereo reconstructions based on processing individual stereo frames. In our reconstructions, small-baseline comparison over several subsequent frames are fused with fixed-baseline disparity from the stereo camera setup. These results demonstrate that our direct SLAM technique provides an excellent compromise between speed and accuracy, generating visually pleasing and globally consistent semi- dense reconstructions of the environment in real-time on a single CPU.
@inproceedings{usenko15_3drecon_stereolsdslam,
author= {V. Usenko and J. Engel and J. Stueckler and D. Cremers},
title = {Reconstructing Street-Scenes in Real-Time From a Driving Car},
booktitle = {Proc. of the Int. Conference on 3D Vision (3DV)},
month = oct,
year = 2015,
}
Super-Resolution Keyframe Fusion for 3D Modeling with High-Quality Textures

We propose a novel fast and robust method for obtaining 3D models with high-quality appearance using commod- ity RGB-D sensors. Our method uses a direct keyframe- based SLAM frontend to consistently estimate the camera motion during the scan. The aligned images are fused into a volumetric truncated signed distance function rep- resentation, from which we extract a mesh. For obtaining a high-quality appearance model, we additionally deblur the low-resolution RGB-D frames using filtering techniques and fuse them into super-resolution keyframes. The meshes are textured from these sharp super-resolution keyframes employing a texture mapping approach. In experiments, we demonstrate that our method achieves superior quality in appearance compared to other state-of-the-art approaches.
@inproceedings{maier2015superresolution,
author= {R. Maier and J. Stueckler and D. Cremers},
title = {Super-Resolution Keyframe Fusion for 3D Modeling with High-Quality Textures},
booktitle = {International Conference on 3D Vision ({3DV})},
month = October,
year = 2015,
}
Large-Scale Direct SLAM with Stereo Cameras
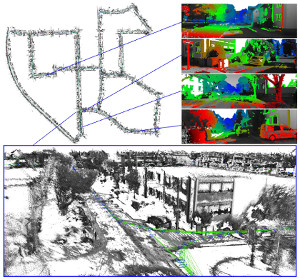
We propose a novel Large-Scale Direct SLAM algorithm for stereo cameras (Stereo LSD-SLAM) that runs in real-time at high frame rate on standard CPUs. In contrast to sparse interest-point based methods, our approach aligns images directly based on the photoconsistency of all high- contrast pixels, including corners, edges and high texture areas. It concurrently estimates the depth at these pixels from two types of stereo cues: Static stereo through the fixed-baseline stereo camera setup as well as temporal multi-view stereo exploiting the camera motion. By incorporating both disparity sources, our algorithm can even estimate depth of pixels that are under-constrained when only using fixed-baseline stereo. Using a fixed baseline, on the other hand, avoids scale-drift that typically occurs in pure monocular SLAM. We furthermore propose a robust approach to enforce illumination invariance, capable of handling aggressive brightness changes between frames – greatly improving the performance in realistic settings. In experiments, we demonstrate state-of-the-art results on stereo SLAM benchmarks such as Kitti or challenging datasets from the EuRoC Challenge 3 for micro aerial vehicles.
» Show BibTeX
@string{iros="International Conference on Intelligent Robots and Systems (IROS)"}
@inproceedings{engel2015_stereo_lsdslam,
author = {J. Engel and J. Stueckler and D. Cremers},
title = {Large-Scale Direct SLAM with Stereo Cameras},
booktitle = iros,
year = 2015,
month = sept,
}
Real-Time Object Detection, Localization and Verification for Fast Robotic Depalletizing
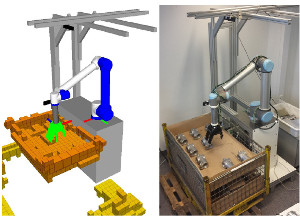
Depalletizing is a challenging task for manipulation robots. Key to successful application are not only robustness of the approach, but also achievable cycle times in order to keep up with the rest of the process. In this paper, we propose a system for depalletizing and a complete pipeline for detecting and localizing objects as well as verifying that the found object does not deviate from the known object model, e.g., if it is not the object to pick. In order to achieve high robustness (e.g., with respect to different lighting conditions) and generality with respect to the objects to pick, our approach is based on multi-resolution surfel models. All components (both software and hardware) allow operation at high frame rates and, thus, allow for low cycle times. In experiments, we demonstrate depalletizing of automotive and other prefabricated parts with both high reliability (w.r.t. success rates) and efficiency (w.r.t. low cycle times).
» Show BibTeX
@string{iros="International Conference on Intelligent Robots and Systems (IROS)"}
@inproceedings{holz2015_depalette,
author = {D. Holz and A. Topalidou-Kyniazopoulou and J. Stueckler and S. Behnke},
title = {Real-Time Object Detection, Localization and Verification for Fast Robotic Depalletizing},
booktitle = iros,
year = 2015,
}
Depth-Enhanced Hough Forests for Object-Class Detection and Continuous Pose Estimation

Much work on the detection and pose estimation of objects in the robotics context focused on object instances. We propose a novel approach that detects object classes and finds the pose of the detected objects in RGB-D images. Our method is based on Hough forests, a variant of random decision and regression trees that categorize pixels and vote for 3D object position and orientation. It makes efficient use of dense depth for scale-invariant detection and pose estimation. We propose an effective way to train our method for arbitrary scenes that are rendered from training data in a turn-table setup. We evaluate our approach on publicly available RGB-D object recognition benchmark datasets and demonstrate stateof-the-art performance in varying background and view poses, clutter, and occlusions.
