
Semi-Supervised Deep Learning for Monocular Depth Map Prediction
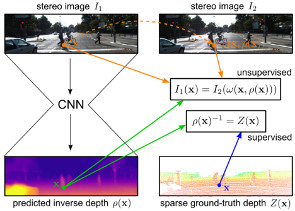
Supervised deep learning often suffers from the lack of sufficient training data. Specifically in the context of monocular depth map prediction, it is barely possible to determine dense ground truth depth images in realistic dynamic outdoor environments. When using LiDAR sensors, for instance, noise is present in the distance measurements, the calibration between sensors cannot be perfect, and the measurements are typically much sparser than the camera images. In this paper, we propose a novel approach to depth map prediction from monocular images that learns in a semi-supervised way. While we use sparse ground-truth depth for supervised learning, we also enforce our deep network to produce photoconsistent dense depth maps in a stereo setup using a direct image alignment loss. In experiments we demonstrate superior performance in depth map prediction from single images compared to the state-of-the-art methods.
@inproceedings{kuznietsov2017_semsupdepth,
title = {Semi-Supervised Deep Learning for Monocular Depth Map Prediction},
author = {Kuznietsov, Yevhen and St\"uckler, J\"org and Leibe, Bastian},
booktitle = {IEEE International Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2017}
}
