
Profile

|
Prof. Dr. Bastian Leibe |
Publications
Fine-Tuning Image-Conditional Diffusion Models is Easier than You Think
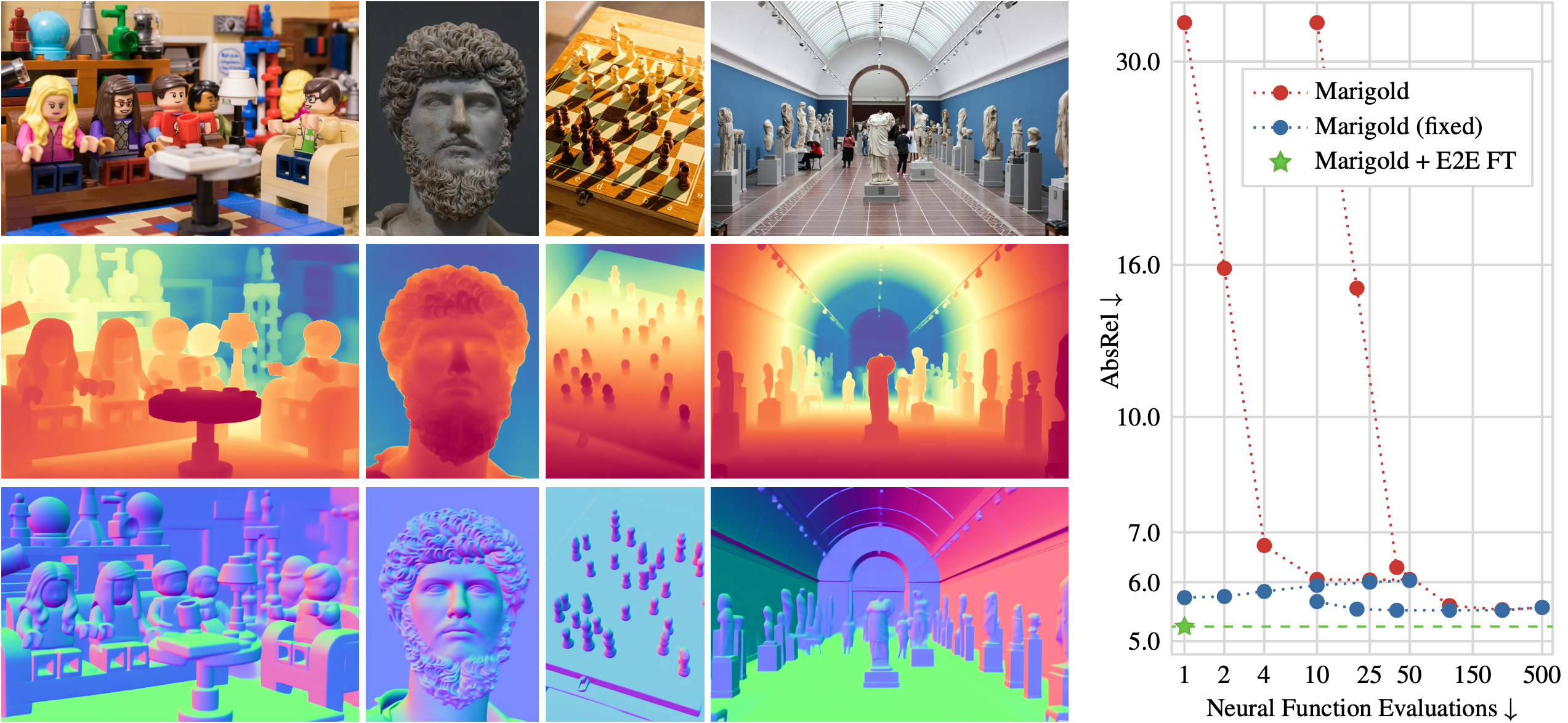
Recent work showed that large diffusion models can be reused as highly precise monocular depth estimators by casting depth estimation as an image-conditional image generation task. While the proposed model achieved state-of-the-art results, high computational demands due to multi-step inference limited its use in many scenarios. In this paper, we show that the perceived inefficiency was caused by a flaw in the inference pipeline that has so far gone unnoticed. The fixed model performs comparably to the best previously reported configuration while being more than 200x faster. To optimize for downstream task performance, we perform end-to-end fine-tuning on top of the single-step model with task-specific losses and get a deterministic model that outperforms all other diffusion-based depth and normal estimation models on common zero-shot benchmarks. We surprisingly find that this fine-tuning protocol also works directly on Stable Diffusion and achieves comparable performance to current state-of-the-art diffusion-based depth and normal estimation models, calling into question some of the conclusions drawn from prior works.
@article{martingarcia2024diffusione2eft,
title = {Fine-Tuning Image-Conditional Diffusion Models is Easier than You Think},
author = {Martin Garcia, Gonzalo and Abou Zeid, Karim and Schmidt, Christian and de Geus, Daan and Hermans, Alexander and Leibe, Bastian},
journal = {arXiv preprint arXiv:2409.11355},
year = {2024}
}
Interactive4D: Interactive 4D LiDAR Segmentation
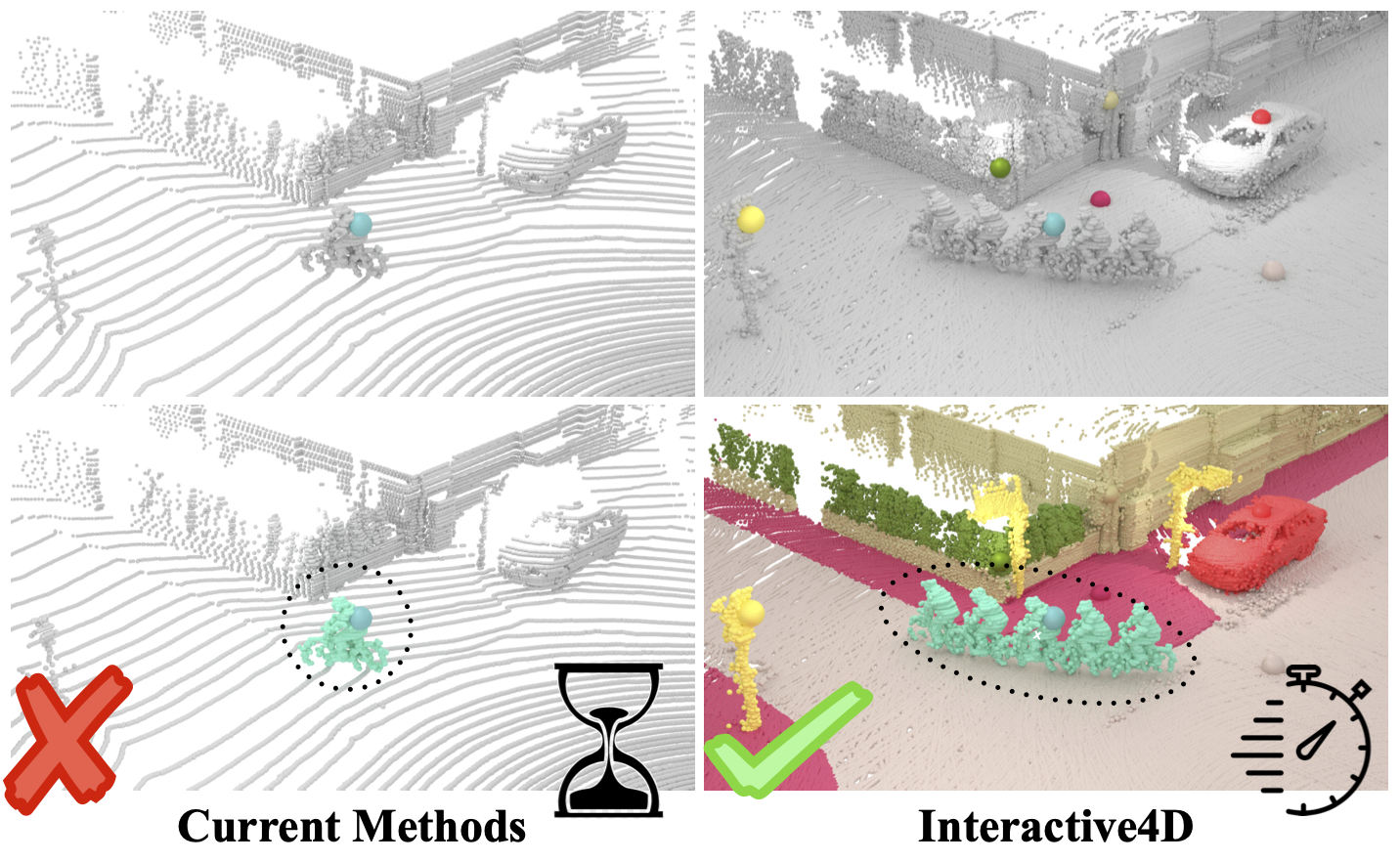
Interactive segmentation has an important role in facilitating the annotation process of future LiDAR datasets. Existing approaches sequentially segment individual objects at each LiDAR scan, repeating the process throughout the entire sequence, which is redundant and ineffective. In this work, we propose interactive 4D segmentation, a new paradigm that allows segmenting multiple objects on multiple LiDAR scans simultaneously, and Interactive4D, the first interactive 4D segmentation model that segments multiple objects on superimposed consecutive LiDAR scans in a single iteration by utilizing the sequential nature of LiDAR data. While performing interactive segmentation, our model leverages the entire space-time volume, leading to more efficient segmentation. Operating on the 4D volume, it directly provides consistent instance IDs over time and also simplifies tracking annotations. Moreover, we show that click simulations are crucial for successful model training on LiDAR point clouds. To this end, we design a click simulation strategy that is better suited for the characteristics of LiDAR data. To demonstrate its accuracy and effectiveness, we evaluate Interactive4D on multiple LiDAR datasets, where Interactive4D achieves a new state-of-the-art by a large margin.
@article{fradlin2024interactive4d,
title = {{Interactive4D: Interactive 4D LiDAR Segmentation}},
author = {Fradlin, Ilya and Zulfikar, Idil Esen and Yilmaz, Kadir and Kontogianni, Thodora and Leibe, Bastian},
journal = {arXiv preprint arXiv:2410.08206},
year = {2024}
}
OCCUQ: Efficient Uncertainty Quantification for 3D Occupancy Prediction
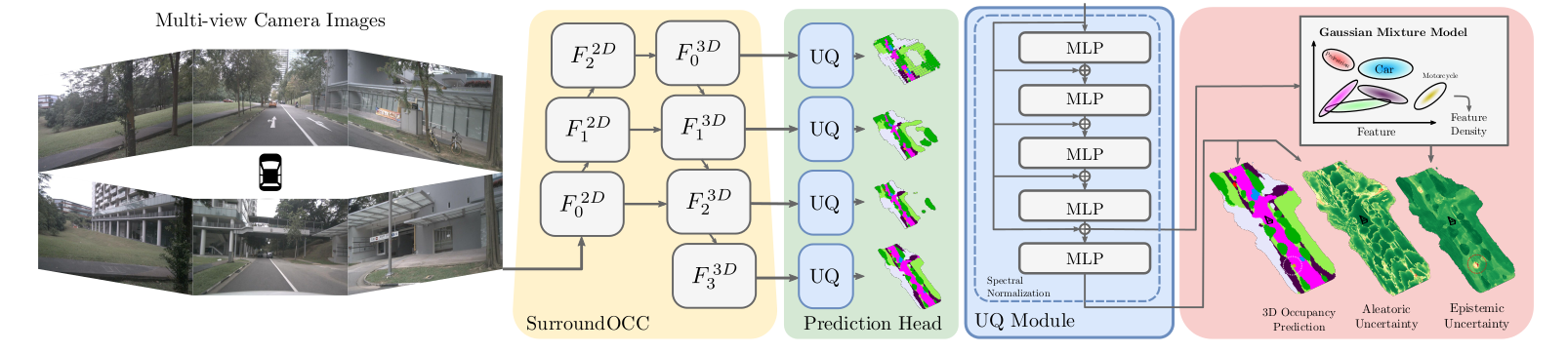
Autonomous driving has the potential to significantly enhance productivity and provide numerous societal benefits. Ensuring robustness in these safety-critical systems is essential, particularly when vehicles must navigate adverse weather conditions and sensor corruptions that may not have been encountered during training. Current methods often overlook uncertainties arising from adversarial conditions or distributional shifts, limiting their real-world applicability. We propose an efficient adaptation of an uncertainty estimation technique for 3D occupancy prediction. Our method dynamically calibrates model confidence using epistemic uncertainty estimates. Our evaluation under various camera corruption scenarios, such as fog or missing cameras, demonstrates that our approach effectively quantifies epistemic uncertainty by assigning higher uncertainty values to unseen data. We introduce region-specific corruptions to simulate defects affecting only a single camera and validate our findings through both scene-level and region-level assessments. Our results show superior performance in Out-of-Distribution (OoD) detection and confidence calibration compared to common baselines such as Deep Ensembles and MC-Dropout. Our approach consistently demonstrates reliable uncertainty measures, indicating its potential for enhancing the robustness of autonomous driving systems in real-world scenarios.
@inproceedings{heidrich2025occuq,
title={{OCCUQ: Exploring Efficient Uncertainty Quantification for 3D Occupancy Prediction}},
author={Heidrich, Severin and Beemelmanns, Till and Nekrasov, Alexey and Leibe, Bastian and Eckstein, Lutz},
booktitle="International Conference on Robotics and Automation (ICRA)",
year={2025}
}
Spotting the Unexpected (STU): A 3D LiDAR Dataset for Anomaly Segmentation in Autonomous Driving
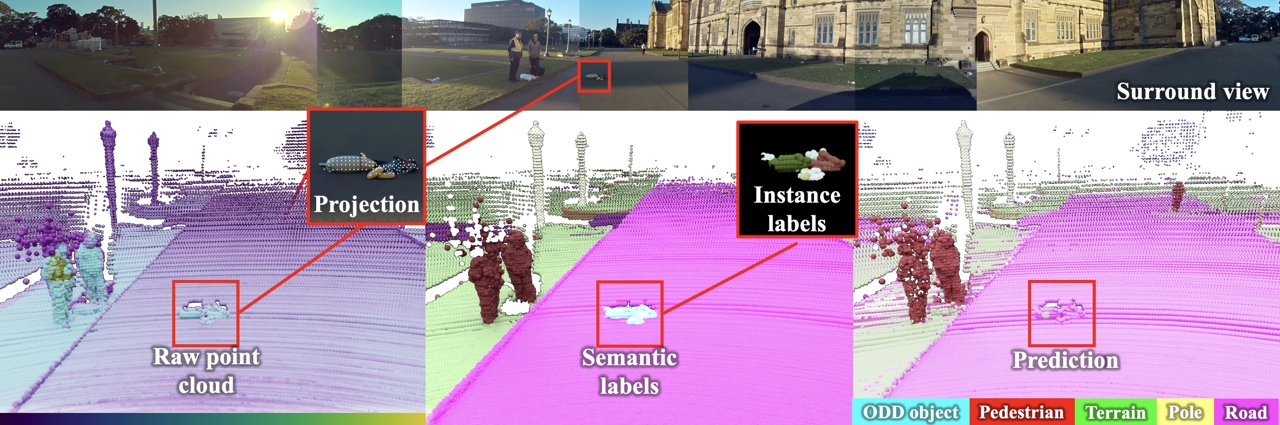
To operate safely, autonomous vehicles (AVs) need to detect and handle unexpected objects or anomalies on the road. While significant research exists for anomaly detection and segmentation in 2D, research progress in 3D is underexplored. Existing datasets lack high-quality multimodal data that are typically found in AVs. This paper presents a novel dataset for anomaly segmentation in driving scenarios. To the best of our knowledge, it is the first publicly available dataset focused on road anomaly segmentation with dense 3D semantic labeling, incorporating both LiDAR and camera data, as well as sequential information to enable anomaly detection across various ranges. This capability is critical for the safe navigation of autonomous vehicles. We adapted and evaluated several baseline models for 3D segmentation, highlighting the challenges of 3D anomaly detection in driving environments. Our dataset and evaluation code will be openly available, facilitating the testing and performance comparison of different approaches.
@inproceedings{nekrasov2025stu,
title = {{Spotting the Unexpected (STU): A 3D LiDAR Dataset for Anomaly Segmentation in Autonomous Driving}},
author = {Nekrasov, Alexey and Burdorf, Malcolm and Worrall, Stewart and Leibe, Bastian and Julie Stephany Berrio Perez},
booktitle = {{"Conference on Computer Vision and Pattern Recognition (CVPR)"}},
year = {2025}
}
Systematic Evaluation of Different Projection Methods for Monocular 3D Human Pose Estimation on Heavily Distorted Fisheye Images
Authors: Stephanie Käs, Sven Peter, Henrik Thillmann, Anton Burenko, Timm Linder, David Adrian, and Dennis Mack, Bastian Leibe
In this work, we tackle the challenge of 3D human pose estimation in fisheye images, which is crucial for applications in robotics, human-robot interaction, and automotive perception. Fisheye cameras offer a wider field of view, but their distortions make pose estimation difficult. We systematically analyze how different camera models impact prediction accuracy and introduce a strategy to improve pose estimation across diverse viewing conditions.
A key contribution of our work is FISHnCHIPS, a novel dataset featuring 3D human skeleton annotations in fisheye images, including extreme close-ups, ground-mounted cameras, and wide-FOV human poses. To support future research, we will be publicly releasing this dataset.
More details coming soon — stay tuned for the final publication! Looking forward to sharing our findings at ICRA 2025!
OoDIS: Anomaly Instance Segmentation Benchmark

Autonomous vehicles require a precise understanding of their environment to navigate safely. Reliable identification of unknown objects, especially those that are absent during training, such as wild animals, is critical due to their potential to cause serious accidents. Significant progress in semantic segmentation of anomalies has been driven by the availability of out-of-distribution (OOD) benchmarks. However, a comprehensive understanding of scene dynamics requires the segmentation of individual objects, and thus the segmentation of instances is essential. Development in this area has been lagging, largely due to the lack of dedicated benchmarks. To address this gap, we have extended the most commonly used anomaly segmentation benchmarks to include the instance segmentation task. Our evaluation of anomaly instance segmentation methods shows that this challenge remains an unsolved problem. The benchmark website and the competition page can be found at: https://vision.rwth-aachen.de/oodis
@article{nekrasov2024oodis,
title={{OoDIS: Anomaly Instance Segmentation Benchmark}},
author={Nekrasov, Alexey and Zhou, Rui and Ackermann, Miriam and Hermans, Alexander and Leibe, Bastian and Rottmann, Matthias},
journal={ICRA},
year={2025}
}
Look Gauss, No Pose: Novel View Synthesis using Gaussian Splatting without Accurate Pose Initialization
3D Gaussian Splatting has recently emerged as a powerful tool for fast and accurate novel-view synthesis from a set of posed input images. However, like most novel-view synthesis approaches, it relies on accurate camera pose information, limiting its applicability in real-world scenarios where acquiring accurate camera poses can be challenging or even impossible. We propose an extension to the 3D Gaussian Splatting framework by optimizing the extrinsic camera parameters with respect to photometric residuals. We derive the analytical gradients and integrate their computation with the existing high-performance CUDA implementation. This enables downstream tasks such as 6-DoF camera pose estimation as well as joint reconstruction and camera refinement. In particular, we achieve rapid convergence and high accuracy for pose estimation on real-world scenes. Our method enables fast reconstruction of 3D scenes without requiring accurate pose information by jointly optimizing geometry and camera poses, while achieving state-of-the-art results in novel-view synthesis. Our approach is considerably faster to optimize than most com- peting methods, and several times faster in rendering. We show results on real-world scenes and complex trajectories through simulated environments, achieving state-of-the-art results on LLFF while reducing runtime by two to four times compared to the most efficient competing method. Source code will be available at https://github.com/Schmiddo/noposegs.
Point-VOS: Pointing Up Video Object Segmentation

Current state-of-the-art Video Object Segmentation (VOS) methods rely on dense per-object mask annotations both during training and testing. This requires time-consuming and costly video annotation mechanisms. We propose a novel Point-VOS task with a spatio-temporally sparse point-wise annotation scheme that substantially reduces the annotation effort. We apply our annotation scheme to two large-scale video datasets with text descriptions and annotate over 19M points across 133K objects in 32K videos. Based on our annotations, we propose a new Point-VOS benchmark, and a corresponding point-based training mechanism, which we use to establish strong baseline results. We show that existing VOS methods can easily be adapted to leverage our point annotations during training, and can achieve results close to the fully-supervised performance when trained on pseudo-masks generated from these points. In addition, we show that our data can be used to improve models that connect vision and language, by evaluating it on the Video Narrative Grounding (VNG) task. We will make our code and annotations available at https://pointvos.github.io.
ControlRoom3D: Room Generation using Semantic Proxies

Manually creating 3D environments for AR/VR applications is a complex process requiring expert knowledge in 3D modeling software. Pioneering works facilitate this process by generating room meshes conditioned on textual style descriptions. Yet, many of these automatically generated 3D meshes do not adhere to typical room layouts, compromising their plausibility, e.g., by placing several beds in one bedroom. To address these challenges, we present ControlRoom3D, a novel method to generate high-quality room meshes. Central to our approach is a user-defined 3D semantic proxy room that outlines a rough room layout based on semantic bounding boxes and a textual description of the overall room style. Our key insight is that when rendered to 2D, this 3D representation provides valuable geometric and semantic information to control powerful 2D models to generate 3D consistent textures and geometry that aligns well with the proxy room. Backed up by an extensive study including quantitative metrics and qualitative user evaluations, our method generates diverse and globally plausible 3D room meshes, thus empowering users to design 3D rooms effortlessly without specialized knowledge.
@inproceedings{schult23controlroom3d,
author = {Schult, Jonas and Tsai, Sam and H\"ollein, Lukas and Wu, Bichen and Wang, Jialiang and Ma, Chih-Yao and Li, Kunpeng and Wang, Xiaofang and Wimbauer, Felix and He, Zijian and Zhang, Peizhao and Leibe, Bastian and Vajda, Peter and Hou, Ji},
title = {ControlRoom3D: Room Generation using Semantic Proxy Rooms},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024},
}
Mask4Former: Mask Transformer for 4D Panoptic Segmentation

Accurately perceiving and tracking instances over time is essential for the decision-making processes of autonomous agents interacting safely in dynamic environments. With this intention, we propose Mask4Former for the challenging task of 4D panoptic segmentation of LiDAR point clouds.
Mask4Former is the first transformer-based approach unifying semantic instance segmentation and tracking of sparse and irregular sequences of 3D point clouds into a single joint model. Our model directly predicts semantic instances and their temporal associations without relying on hand-crafted non-learned association strategies such as probabilistic clustering or voting-based center prediction. Instead, Mask4Former introduces spatio-temporal instance queries that encode the semantic and geometric properties of each semantic tracklet in the sequence.
In an in-depth study, we find that promoting spatially compact instance predictions is critical as spatio-temporal instance queries tend to merge multiple semantically similar instances, even if they are spatially distant. To this end, we regress 6-DOF bounding box parameters from spatio-temporal instance queries, which are used as an auxiliary task to foster spatially compact predictions.
Mask4Former achieves a new state-of-the-art on the SemanticKITTI test set with a score of 68.4 LSTQ.
@inproceedings{yilmaz24mask4former,
title = {{Mask4Former: Mask Transformer for 4D Panoptic Segmentation}},
author = {Yilmaz, Kadir and Schult, Jonas and Nekrasov, Alexey and Leibe, Bastian},
booktitle = {International Conference on Robotics and Automation (ICRA)},
year = {2024}
}
AGILE3D: Attention Guided Interactive Multi-object 3D Segmentation

During interactive segmentation, a model and a user work together to delineate objects of interest in a 3D point cloud. In an iterative process, the model assigns each data point to an object (or the background), while the user corrects errors in the resulting segmentation and feeds them back into the model. The current best practice formulates the problem as binary classification and segments objects one at a time. The model expects the user to provide positive clicks to indicate regions wrongly assigned to the background and negative clicks on regions wrongly assigned to the object. Sequentially visiting objects is wasteful since it disregards synergies between objects: a positive click for a given object can, by definition, serve as a negative click for nearby objects. Moreover, a direct competition between adjacent objects can speed up the identification of their common boundary. We introduce AGILE3D, an efficient, attention-based model that (1) supports simultaneous segmentation of multiple 3D objects, (2) yields more accurate segmentation masks with fewer user clicks, and (3) offers faster inference. Our core idea is to encode user clicks as spatial-temporal queries and enable explicit interactions between click queries as well as between them and the 3D scene through a click attention module. Every time new clicks are added, we only need to run a lightweight decoder that produces updated segmentation masks. In experiments with four different 3D point cloud datasets, AGILE3D sets a new state-of-the-art. Moreover, we also verify its practicality in real-world setups with real user studies.
@inproceedings{yue2023agile3d,
title = {{AGILE3D: Attention Guided Interactive Multi-object 3D Segmentation}},
author = {Yue, Yuanwen and Mahadevan, Sabarinath and Schult, Jonas and Engelmann, Francis and Leibe, Bastian and Schindler, Konrad and Kontogianni, Theodora},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2024}
}
Benchmarks and Challenges in Pose Estimation for Egocentric Hand Interactions with Objects

We interact with the world with our hands and see it through our own (egocentric) perspective. A holistic 3Dunderstanding of such interactions from egocentric views is important for tasks in robotics, AR/VR, action recognition and motion generation. Accurately reconstructing such interactions in 3D is challenging due to heavy occlusion, viewpoint bias, camera distortion, and motion blur from the head movement. To this end, we designed the HANDS23 challenge based on the AssemblyHands and ARCTIC datasets with carefully designed training and testing splits. Based on the results of the top submitted methods and more recent baselines on the leaderboards, we perform a thorough analysis on 3D hand(-object) reconstruction tasks. Our analysis demonstrates the effectiveness of addressing distortion specific to egocentric cameras, adopting high-capacity transformers to learn complex hand-object interactions, and fusing predictions from different views. Our study further reveals challenging scenarios intractable with state-of-the-art methods, such as fast hand motion, object reconstruction from narrow egocentric views, and close contact between two hands and objects. Our efforts will enrich the community's knowledge foundation and facilitate future hand studies on egocentric hand-object interactions.
RGB-D Cube R-CNN: 3D Object Detection with Selective Modality Dropout
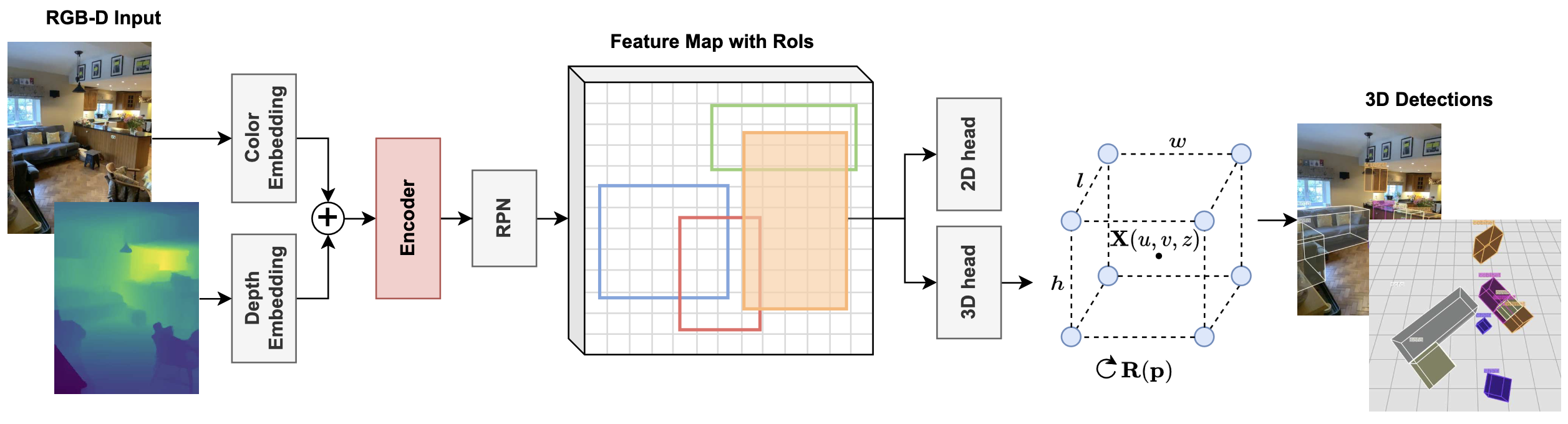
In this paper we create an RGB-D 3D object detector targeted at indoor robotics use cases where one modality may be unavailable due to a specific sensor setup or a sensor failure. We incorporate RGB and depth fusion into the recent Cube R-CNN framework with support for selective modality dropout. To train this model we augment the Omni3DIN dataset with depth information leading to a diverse dataset for 3D object detection in indoor scenes. In order to leverage strong pretrained networks we investigate the viability of Transformer-based backbones (Swin ViT) as an alternative to the currently popular CNN-based DLA backbone. We show that these Transformer-based image models work well based on our early-fusion approach and propose a modality dropout scheme to avoid the disregard of any modality during training facilitating selective modality dropout during inference. In extensive experiments our proposed RGB-D Cube R-CNN outperforms an RGB-only Cube R-CNN baseline by a significant margin on the task of indoor object detection. Additionally we observe a slight performance boost from the RGB-D training when inferring on only one modality which could for example be valuable in robotics applications with a reduced or unreliable sensor set.
@InProceedings{RGB_D_Cube_RCNN_2024_CVPRW,
author = {Piekenbrinck, Jens and Hermans, Alexander and Vaskevicius, Narunas and Linder, Timm and Leibe, Bastian},
title = {{RGB-D Cube R-CNN: 3D Object Detection with Selective Modality Dropout}},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},
year = {2024},
}
DynaMITe: Dynamic Query Bootstrapping for Multi-object Interactive Segmentation Transformer
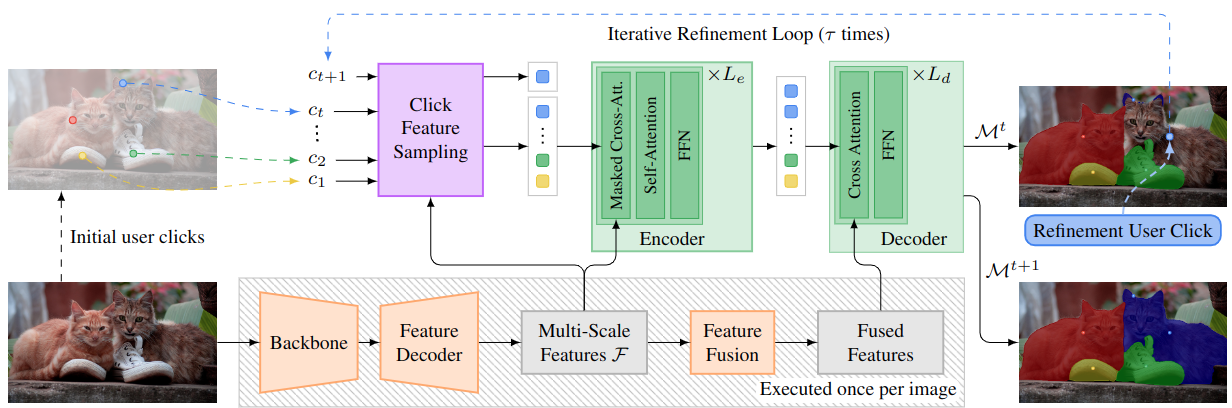
Most state-of-the-art instance segmentation methods rely on large amounts of pixel-precise ground-truth annotations for training, which are expensive to create. Interactive segmentation networks help generate such annotations based on an image and the corresponding user interactions such as clicks. Existing methods for this task can only process a single instance at a time and each user interaction requires a full forward pass through the entire deep network. We introduce a more efficient approach, called DynaMITe, in which we represent user interactions as spatio-temporal queries to a Transformer decoder with a potential to segment multiple object instances in a single iteration. Our architecture also alleviates any need to re-compute image features during refinement, and requires fewer interactions for segmenting multiple instances in a single image when compared to other methods. DynaMITe achieves state-of-the-art results on multiple existing interactive segmentation benchmarks, and also on the new multi-instance benchmark that we propose in this paper.
@article{RanaMahadevan23arxiv,
title={DynaMITe: Dynamic Query Bootstrapping for Multi-object Interactive Segmentation Transformer},
author={Rana, Amit and Mahadevan, Sabarinath and Alexander Hermans and Leibe, Bastian},
journal={arXiv preprint arXiv:2304.06668},
year={2023}
}
TarVis: A Unified Approach for Target-based Video Segmentation
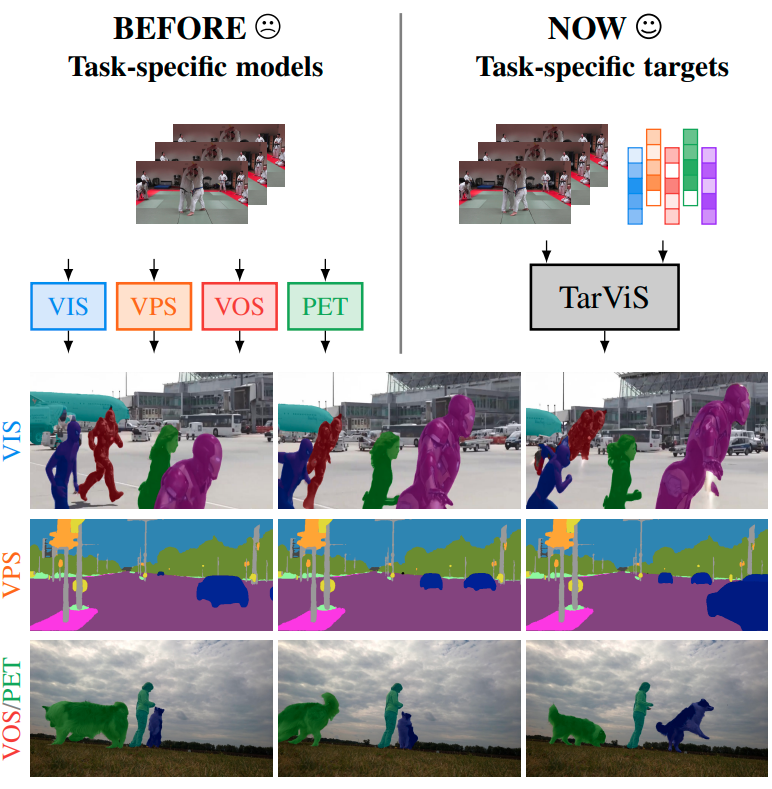
The general domain of video segmentation is currently fragmented into different tasks spanning multiple benchmarks. Despite rapid progress in the state-of-the-art, current methods are overwhelmingly task-specific and cannot conceptually generalize to other tasks. Inspired by recent approaches with multi-task capability, we propose TarViS: a novel, unified network architecture that can be applied to any task that requires segmenting a set of arbitrarily defined 'targets' in video. Our approach is flexible with respect to how tasks define these targets, since it models the latter as abstract 'queries' which are then used to predict pixel-precise target masks. A single TarViS model can be trained jointly on a collection of datasets spanning different tasks, and can hot-swap between tasks during inference without any task-specific retraining. To demonstrate its effectiveness, we apply TarViS to four different tasks, namely Video Instance Segmentation (VIS), Video Panoptic Segmentation (VPS), Video Object Segmentation (VOS) and Point Exemplar-guided Tracking (PET). Our unified, jointly trained model achieves state-of-the-art performance on 5/7 benchmarks spanning these four tasks, and competitive performance on the remaining two.
» Show BibTeX
@inproceedings{athar2023tarvis,
title={TarViS: A Unified Architecture for Target-based Video Segmentation},
author={Athar, Ali and Hermans, Alexander and Luiten, Jonathon and Ramanan, Deva and Leibe, Bastian},
booktitle={CVPR},
year={2023}
}
3D Segmentation of Humans in Point Clouds with Synthetic Data
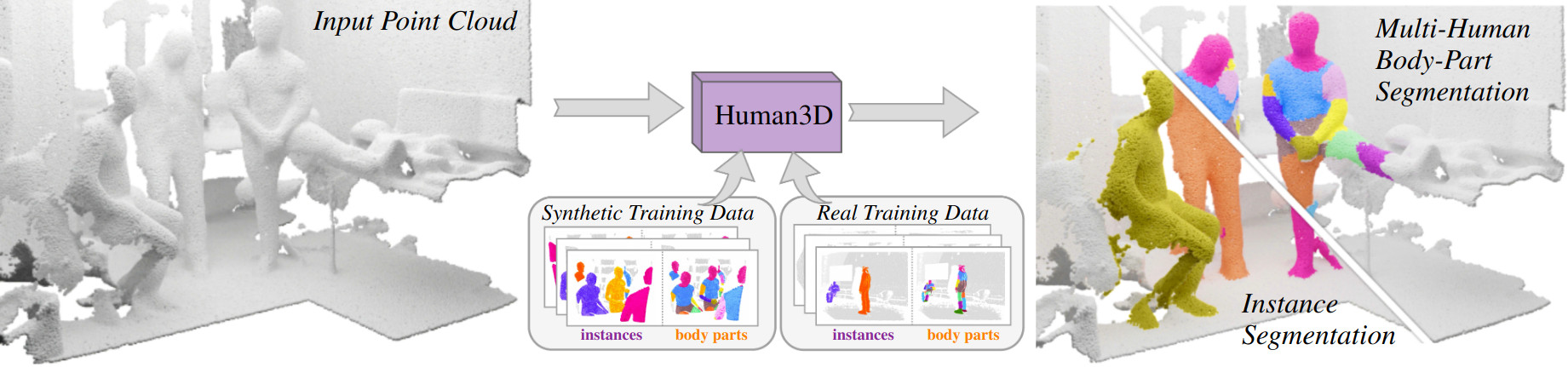
Segmenting humans in 3D indoor scenes has become increasingly important with the rise of human-centered robotics and AR/VR applications. In this direction, we explore the tasks of 3D human semantic-, instance- and multi-human body-part segmentation. Few works have attempted to directly segment humans in point clouds (or depth maps), which is largely due to the lack of training data on humans interacting with 3D scenes. We address this challenge and propose a framework for synthesizing virtual humans in realistic 3D scenes. Synthetic point cloud data is attractive since the domain gap between real and synthetic depth is small compared to images. Our analysis of different training schemes using a combination of synthetic and realistic data shows that synthetic data for pre-training improves performance in a wide variety of segmentation tasks and models. We further propose the first end-to-end model for 3D multi-human body-part segmentation, called Human3D, that performs all the above segmentation tasks in a unified manner. Remarkably, Human3D even outperforms previous task-specific state-of-the-art methods. Finally, we manually annotate humans in test scenes from EgoBody to compare the proposed training schemes and segmentation models.
@article{Takmaz23,
title = {{3D Segmentation of Humans in Point Clouds with Synthetic Data}},
author = {Takmaz, Ay\c{c}a and Schult, Jonas and Kaftan, Irem and Ak\c{c}ay, Mertcan
and Leibe, Bastian and Sumner, Robert and Engelmann, Francis and Tang, Siyu},
booktitle = {{International Conference on Computer Vision (ICCV)}},
year = {2023}
}
BURST: A Benchmark for Unifying Object Recognition, Segmentation and Tracking in Video

Multiple existing benchmarks involve tracking and segmenting objects in video e.g., Video Object Segmentation (VOS) and Multi-Object Tracking and Segmentation (MOTS), but there is little interaction between them due to the use of disparate benchmark datasets and metrics (e.g. J&F, mAP, sMOTSA). As a result, published works usually target a particular benchmark, and are not easily comparable to each another. We believe that the development of generalized methods that can tackle multiple tasks requires greater cohesion among these research sub-communities. In this paper, we aim to facilitate this by proposing BURST, a dataset which contains thousands of diverse videos with high-quality object masks, and an associated benchmark with six tasks involving object tracking and segmentation in video. All tasks are evaluated using the same data and comparable metrics, which enables researchers to consider them in unison, and hence, more effectively pool knowledge from different methods across different tasks. Additionally, we demonstrate several baselines for all tasks and show that approaches for one task can be applied to another with a quantifiable and explainable performance difference.
» Show BibTeX
@inproceedings{athar2023burst,
title={BURST: A Benchmark for Unifying Object Recognition, Segmentation and Tracking in Video},
author={Athar, Ali and Luiten, Jonathon and Voigtlaender, Paul and Khurana, Tarasha and Dave, Achal and Leibe, Bastian and Ramanan, Deva},
booktitle={WACV},
year={2023}
}
Learning 3D Human Pose Estimation from Dozens of Datasets using a Geometry-Aware Autoencoder to Bridge Between Skeleton Formats
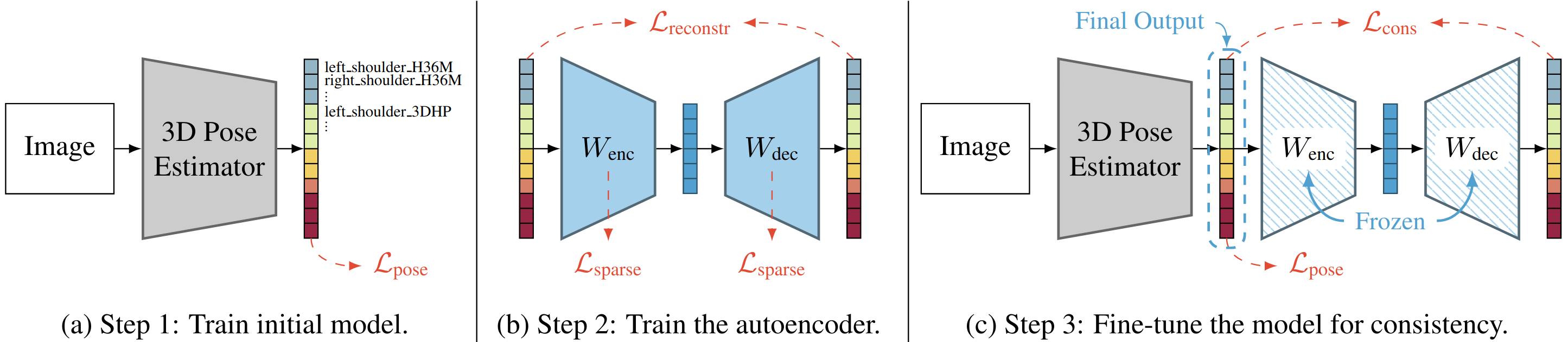
Deep learning-based 3D human pose estimation performs best when trained on large amounts of labeled data, making combined learning from many datasets an important research direction. One obstacle to this endeavor are the different skeleton formats provided by different datasets, i.e., they do not label the same set of anatomical landmarks. There is little prior research on how to best supervise one model with such discrepant labels. We show that simply using separate output heads for different skeletons results in inconsistent depth estimates and insufficient information sharing across skeletons. As a remedy, we propose a novel affine-combining autoencoder (ACAE) method to perform dimensionality reduction on the number of landmarks. The discovered latent 3D points capture the redundancy among skeletons, enabling enhanced information sharing when used for consistency regularization. Our approach scales to an extreme multi-dataset regime, where we use 28 3D human pose datasets to supervise one model, which outperforms prior work on a range of benchmarks, including the challenging 3D Poses in the Wild (3DPW) dataset. Our code and models are available for research purposes.
» Show BibTeX
@inproceedings{Sarandi23WACV,
author = {S\'ar\'andi, Istv\'an and Hermans, Alexander and Leibe, Bastian},
title = {Learning {3D} Human Pose Estimation from Dozens of Datasets using a Geometry-Aware Autoencoder to Bridge Between Skeleton Formats},
booktitle = {IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
year = {2023},
}
Mask3D for 3D Semantic Instance Segmentation

Modern 3D semantic instance segmentation approaches predominantly rely on specialized voting mechanisms followed by carefully designed geometric clustering techniques. Building on the successes of recent Transformer-based methods for object detection and image segmentation, we propose the first Transformer-based approach for 3D semantic instance segmentation. We show that we can leverage generic Transformer building blocks to directly predict instance masks from 3D point clouds. In our model called Mask3D each object instance is represented as an instance query. Using Transformer decoders, the instance queries are learned by iteratively attending to point cloud features at multiple scales. Combined with point features, the instance queries directly yield all instance masks in parallel. Mask3D has several advantages over current state-of-the-art approaches, since it neither relies on (1) voting schemes which require hand-selected geometric properties (such as centers) nor (2) geometric grouping mechanisms requiring manually-tuned hyper-parameters (e.g. radii) and (3) enables a loss that directly optimizes instance masks. Mask3D sets a new state-of-the-art on ScanNet test (+6.2 mAP), S3DIS 6-fold (+10.1 mAP), STPLS3D (+11.2 mAP) and ScanNet200 test (+12.4 mAP).
» Show BibTeX
@article{Schult23ICRA,
title = {{Mask3D for 3D Semantic Instance Segmentation}},
author = {Schult, Jonas and Engelmann, Francis and Hermans, Alexander and Litany, Or and Tang, Siyu and Leibe, Bastian},
booktitle = {{International Conference on Robotics and Automation (ICRA)}},
year = {2023}
}
Point2Vec for Self-Supervised Representation Learning on Point Clouds
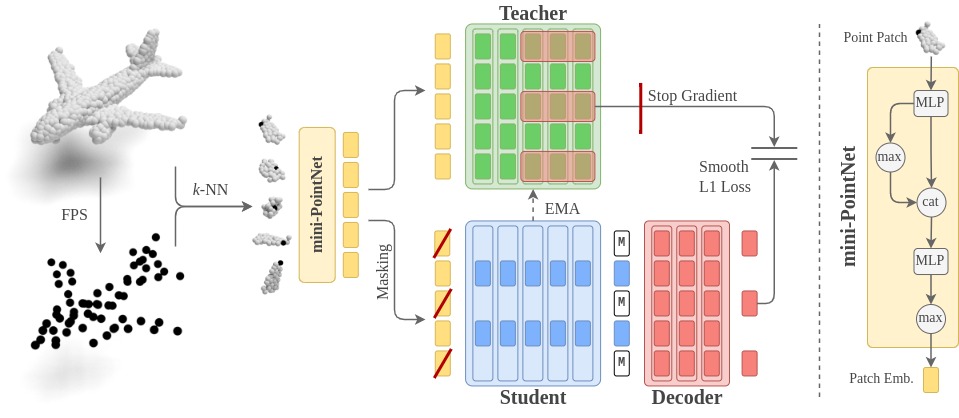
Recently, the self-supervised learning framework data2vec has shown inspiring performance for various modalities using a masked student-teacher approach. However, it remains open whether such a framework generalizes to the unique challenges of 3D point clouds.To answer this question, we extend data2vec to the point cloud domain and report encouraging results on several downstream tasks. In an in-depth analysis, we discover that the leakage of positional information reveals the overall object shape to the student even under heavy masking and thus hampers data2vec to learn strong representations for point clouds. We address this 3D-specific shortcoming by proposing point2vec, which unleashes the full potential of data2vec-like pre-training on point clouds. Our experiments show that point2vec outperforms other self-supervised methods on shape classification and few-shot learning on ModelNet40 and ScanObjectNN, while achieving competitive results on part segmentation on ShapeNetParts. These results suggest that the learned representations are strong and transferable, highlighting point2vec as a promising direction for self-supervised learning of point cloud representations.
@article{abouzeid2023point2vec,
title={Point2Vec for Self-Supervised Representation Learning on Point Clouds},
author={Abou Zeid, Karim and Schult, Jonas and Hermans, Alexander and Leibe, Bastian},
journal={DAGM German Conference on Pattern Recognition (GCPR)},
year={2023},
}
Clicks as Queries: Interactive Transformer for Multi-instance Segmentation
Transformers have percolated into a multitude of computer vision domains including dense prediction tasks such as instance segmentation and have demonstrated strong performances. Existing transformer based segmentation approaches such as Mask2Former generate pixel-precise object masks automatically given an input image. While these methods are capable of generating high quality masks in general, they have an inherent class bias and are unable to incorporate user inputs to either segment out-of-distribution classes or to correct bad predictions. Hence, we introduce a novel module called Interactive Transformer that enables transformers to predict and refine objects based on user interactions. Subsequently, we use our Interactive Transformer to develop an interactive segmentation network that can generate mask predictions based on user clicks and thereby widen the transformer application domains within computer vision. In addition, the Interactive Transformer can make such interactive segmentation tasks more efficient by (i) imparting the ability to perform multi-instances segmentation, (ii) alleviating the need to re-compute image-level backbone features as done in existing interactive segmentation networks, and (iii) reducing the required number of user interactions by modeling a common background representation. Our transformer-based architecture outperforms the state-of-the-art interactive segmentation networks on multiple benchmark datasets.
@inproceedings{RanaMahadevan23cvprw,
title={Clicks as Queries: Interactive Transformer for Multi-instance Segmentation},
author={Rana, Amit and Mahadevan, Sabarinath and Alexander Hermans and Leibe, Bastian},
booktitle={CVPRW},
year={2023}
}
UGainS: Uncertainty Guided Anomaly Segmentation

A single unexpected object on the road can cause an accident or may lead to injuries. To prevent this, we need a reliable mechanism for finding anomalous objects on the road. This task, called anomaly segmentation, can be a stepping stone to safe and reliable autonomous driving. Current approaches tackle anomaly segmentation by assigning an anomaly score to each pixel and by grouping anomalous regions using simple heuristics. However, pixel grouping is a limiting factor when it comes to evaluating the segmentation performance of individual anomalous objects. To address the issue of grouping multiple anomaly instances into one, we propose an approach that produces accurate anomaly instance masks. Our approach centers on an out-of-distribution segmentation model for identifying uncertain regions and a strong generalist segmentation model for anomaly instances segmentation. We investigate ways to use uncertain regions to guide such a segmentation model to perform segmentation of anomalous instances. By incorporating strong object priors from a generalist model we additionally improve the per-pixel anomaly segmentation performance. Our approach outperforms current pixel-level anomaly segmentation methods, achieving an AP of 80.08% and 88.98% on the Fishyscapes Lost and Found and the RoadAnomaly validation sets respectively.
```
@inproceedings{nekrasov2023ugains,
title = {{UGainS: Uncertainty Guided Anomaly Instance Segmentation}},
author = {Nekrasov, Alexey and Hermans, Alexander and Kuhnert, Lars and Leibe, Bastian},
booktitle = {GCPR},
year = {2023}
}
```
4D-StOP: Panoptic Segmentation of 4D LiDAR using Spatio-temporal Object Proposal Generation and Aggregation
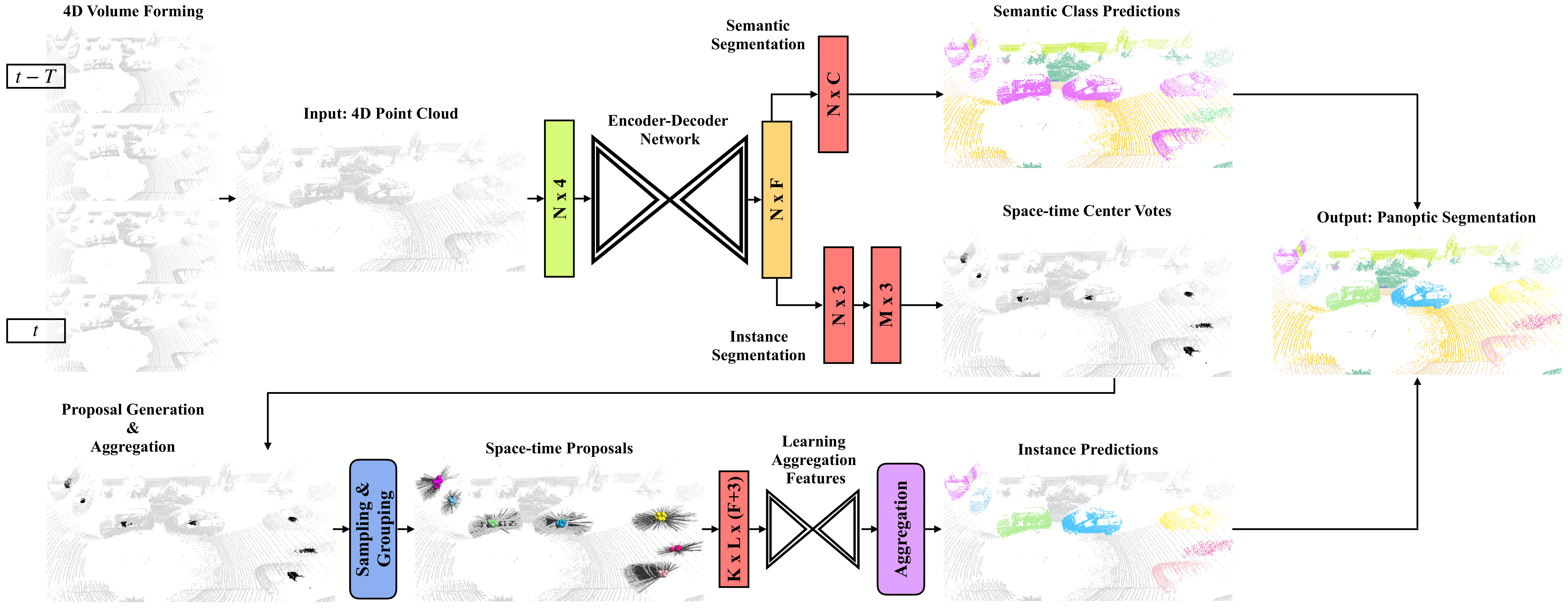
In this work, we present a new paradigm, called 4D-StOP, to tackle the task of 4D Panoptic LiDAR Segmentation. 4D-StOP first generates spatio-temporal proposals using voting-based center predictions, where each point in the 4D volume votes for a corresponding center. These tracklet proposals are further aggregated using learned geometric features. The tracklet aggregation method effectively generates a video-level 4D scene representation over the entire space-time volume. This is in contrast to existing end-to-end trainable state-of-the-art approaches which use spatio-temporal embeddings that are represented by Gaussian probability distributions. Our voting-based tracklet generation method followed by geometric feature-based aggregation generates significantly improved panoptic LiDAR segmentation quality when compared to modeling the entire 4D volume using Gaussian probability distributions. 4D-StOP achieves a new state-of-the-art when applied to the SemanticKITTI test dataset with a score of 63.9 LSTQ, which is a large (+7%) improvement compared to current best-performing end-to-end trainable methods. The code and pre-trained models are available at:https://github.com/LarsKreuzberg/4D-StOP
HODOR: High-level Object Descriptors for Object Re-segmentation in Video Learned from Static Images
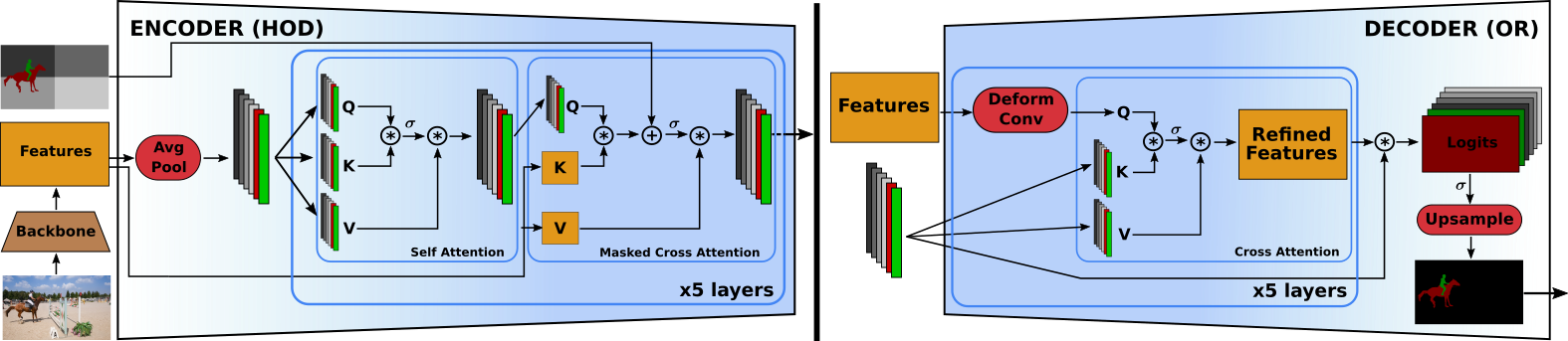
Existing state-of-the-art methods for Video Object Segmentation (VOS) learn low-level pixel-to-pixel correspondences between frames to propagate object masks across video. This requires a large amount of densely annotated video data, which is costly to annotate, and largely redundant since frames within a video are highly correlated. In light of this, we propose HODOR: a novel method that tackles VOS by effectively leveraging annotated static images for understanding object appearance and scene context. We encode object instances and scene information from an image frame into robust high-level descriptors which can then be used to re-segment those objects in different frames. As a result, HODOR achieves state-of-the-art performance on the DAVIS and YouTube-VOS benchmarks compared to existing methods trained without video annotations. Without any architectural modification, HODOR can also learn from video context around single annotated video frames by utilizing cyclic consistency, whereas other methods rely on dense, temporally consistent annotations.
@article{Athar22CVPR,
title = {{HODOR: High-level Object Descriptors for Object Re-segmentation in Video Learned from Static Images}},
author = {Athar, Ali and Luiten, Jonathon and Hermans, Alexander and Ramanan, Deva and Leibe, Bastian},
journal = {{IEEE Conference on Computer Vision and Pattern Recognition (CVPR'22)}},
year = {2022}
}
Opening up Open World Tracking

Tracking and detecting any object, including ones never-seen-before during model training, is a crucial but elusive capability of autonomous systems. An autonomous agent that is blind to never-seen-before objects poses a safety hazard when operating in the real world and yet this is how almost all current systems work. One of the main obstacles towards advancing tracking any object is that this task is notoriously difficult to evaluate. A benchmark that would allow us to perform an apples-to-apples comparison of existing efforts is a crucial first step towards advancing this important research field. This paper addresses this evaluation deficit and lays out the landscape and evaluation methodology for detecting and tracking both known and unknown objects in the open-world setting. We propose a new benchmark, TAO-OW: Tracking Any Object in an Open World}, analyze existing efforts in multi-object tracking, and construct a baseline for this task while highlighting future challenges. We hope to open a new front in multi-object tracking research that will hopefully bring us a step closer to intelligent systems that can operate safely in the real world.
@inproceedings{liu2022opening,
title={Opening up Open-World Tracking},
author={Liu, Yang and Zulfikar, Idil Esen and Luiten, Jonathon and Dave, Achal and Ramanan, Deva and Leibe, Bastian and O{\v{s}}ep, Aljo{\v{s}}a and Leal-Taix{\'e}, Laura},
journal={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2022}
}
M2F3D: Mask2Former for 3D Instance Segmentation
In this work, we show that the top performing Mask2Former approach for image-based segmentation tasks works surprisingly well when adapted to the 3D scene understanding domain. Current 3D semantic instance segmentation methods rely largely on predicting centers followed by clustering approaches and little progress has been made in applying transformer-based approaches to this task. We show that with small modifications to the Mask2Former approach for 2D, we can create a 3D instance segmentation approach, without the need for highly 3D specific components or carefully hand-engineered hyperparameters. Initial experiments with our M2F3D model on the ScanNet benchmark are very promising and sets a new state-of-the-art on ScanNet test (+0.4 mAP50).
Please see our extended work Mask3D: Mask Transformer for 3D Instance Segmentation accepted at ICRA 2023.
Global Hierarchical Attention for 3D Point Cloud Analysis
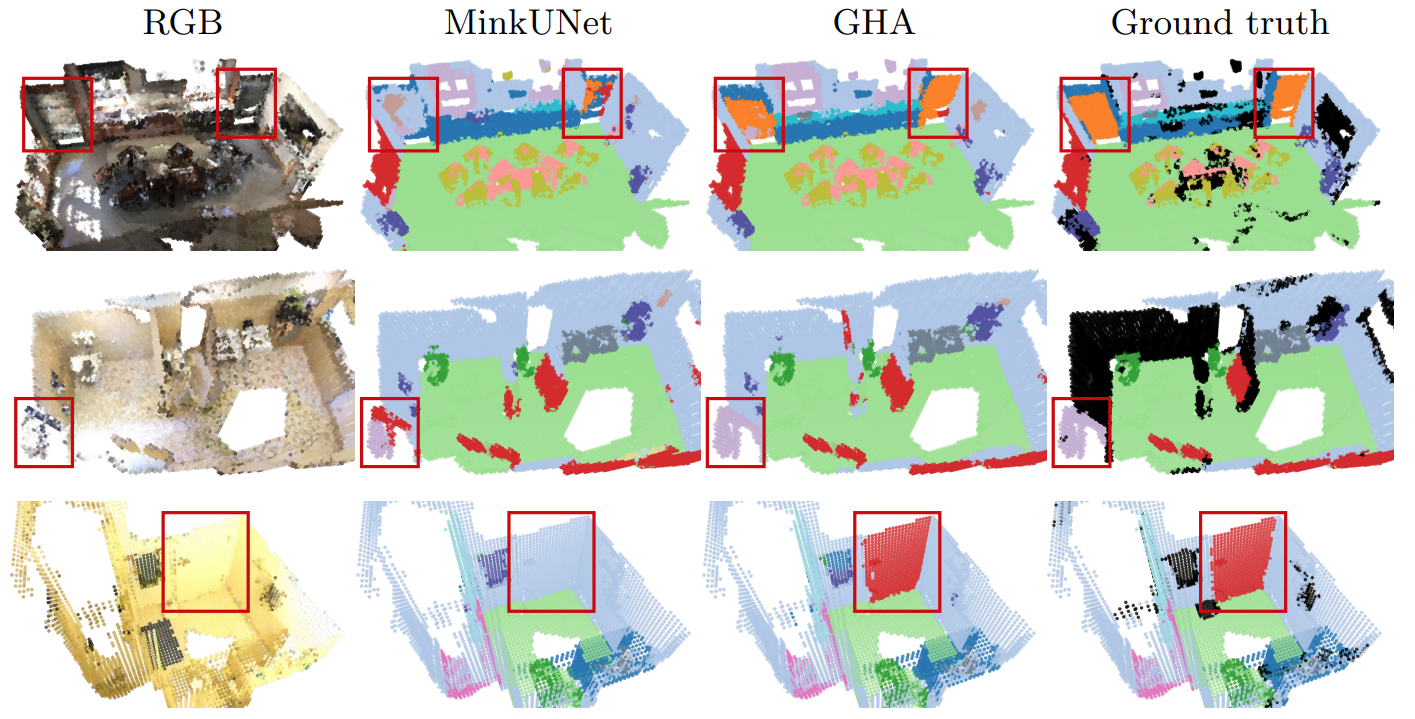
We propose a new attention mechanism, called Global Hierarchical Attention (GHA), for 3D point cloud analysis. GHA approximates the regular global dot-product attention via a series of coarsening and interpolation operations over multiple hierarchy levels. The advantage of GHA is two-fold. First, it has linear complexity with respect to the number of points, enabling the processing of large point clouds. Second, GHA inherently possesses the inductive bias to focus on spatially close points, while retaining the global connectivity among all points. Combined with a feedforward network, GHA can be inserted into many existing network architectures. We experiment with multiple baseline networks and show that adding GHA consistently improves performance across different tasks and datasets. For the task of semantic segmentation, GHA gives a +1.7% mIoU increase to the MinkowskiEngine baseline on ScanNet. For the 3D object detection task, GHA improves the CenterPoint baseline by +0.5% mAP on the nuScenes dataset, and the 3DETR baseline by +2.1% mAP25 and +1.5% mAP50 on ScanNet.
Pedestrian-Robot Interactions on Autonomous Crowd Navigation: Reactive Control Methods and Evaluation Metrics

Autonomous navigation in highly populated areas remains a challenging task for robots because of the difficulty in guaranteeing safe interactions with pedestrians in unstructured situations. In this work, we present a crowd navigation control framework that delivers continuous obstacle avoidance and post-contact control evaluated on an autonomous personal mobility vehicle. We propose evaluation metrics for accounting efficiency, controller response and crowd interactions in natural crowds. We report the results of over 110 trials in different crowd types: sparse, flows, and mixed traffic, with low- (< 0.15 ppsm), mid- (< 0.65 ppsm), and high- (< 1 ppsm) pedestrian densities. We present comparative results between two low-level obstacle avoidance methods and a baseline of shared control. Results show a 10% drop in relative time to goal on the highest density tests, and no other efficiency metric decrease. Moreover, autonomous navigation showed to be comparable to shared-control navigation with a lower relative jerk and significantly higher fluency in commands indicating high compatibility with the crowd. We conclude that the reactive controller fulfills a necessary task of fast and continuous adaptation to crowd navigation, and it should be coupled with high-level planners for environmental and situational awareness.
Differentiable Soft-Masked Attention
Transformers have become prevalent in computer vision due to their performance and flexibility in modelling complex operations. Of particular significance is the ‘cross-attention’ operation, which allows a vector representation (e.g. of an object in an image) to be learned by ‘attending’ to an arbitrarily sized set of input features. Recently, ‘Masked Attention’ was proposed in which a given object representation only attends to those image pixel features for which the segmentation mask of that object is active. This specialization of attention proved beneficial for various image and video segmentation tasks. In this paper, we propose another specialization of attention which enables attending over ‘soft-masks’ (those with continuous mask probabilities instead of binary values), and is also differentiable through these mask probabilities, thus allowing the mask used for attention to be learned within the network without requiring direct loss supervision. This can be useful for several applications. Specifically, we employ our ‘Differentiable Soft-Masked Attention’ for the task of Weakly Supervised Video Object Segmentation (VOS), where we develop a transformer-based network for VOS which only requires a single annotated image frame for training, but can also benefit from cycle consistency training on a video with just one annotated frame. Although there is no loss for masks in unlabeled frames, the network is still able to segment objects in those frames due to our novel attention formulation.
2D vs. 3D LiDAR-based Person Detection on Mobile Robots
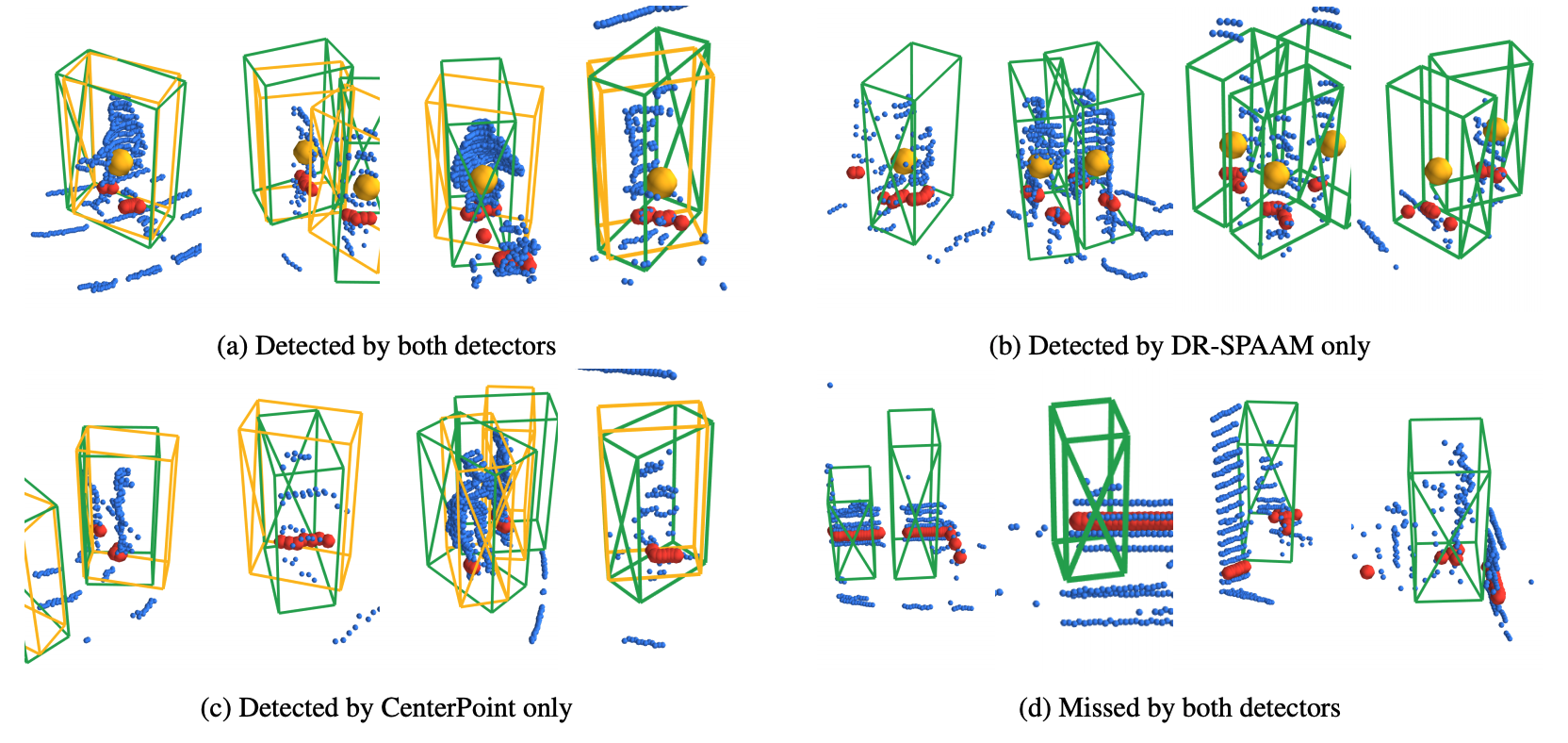
Person detection is a crucial task for mobile robots navigating in human-populated environments. LiDAR sensors are promising for this task, thanks to their accurate depth measurements and large field of view. Two types of LiDAR sensors exist: the 2D LiDAR sensors, which scan a single plane, and the 3D LiDAR sensors, which scan multiple planes, thus forming a volume. How do they compare for the task of person detection? To answer this, we conduct a series of experiments, using the public, large-scale JackRabbot dataset and the state-of-the-art 2D and 3D LiDAR-based person detectors (DR-SPAAM and CenterPoint respectively). Our experiments include multiple aspects, ranging from the basic performance and speed comparison, to more detailed analysis on localization accuracy and robustness against distance and scene clutter. The insights from these experiments highlight the strengths and weaknesses of 2D and 3D LiDAR sensors as sources for person detection, and are especially valuable for designing mobile robots that will operate in close proximity to surrounding humans (e.g. service or social robot).
Mix3D: Out-of-Context Data Augmentation for 3D Scenes

Mix3D is a data augmentation technique for segmenting large-scale 3D scenes. Since scene context helps reasoning about object semantics, current works focus on models with large capacity and receptive fields that can fully capture the global context of an input 3D scene. However, strong contextual priors can have detrimental implications like mistaking a pedestrian crossing the street for a car. In this work, we focus on the importance of balancing global scene context and local geometry, with the goal of generalizing beyond the contextual priors in the training set. In particular, we propose a "mixing" technique which creates new training samples by combining two augmented scenes. By doing so, object instances are implicitly placed into novel out-of-context environments and therefore making it harder for models to rely on scene context alone, and instead infer semantics from local structure as well.
In the paper, we perform detailed analysis to understand the importance of global context, local structures and the effect of mixing scenes. In experiments, we show that models trained with Mix3D profit from a significant performance boost on indoor (ScanNet, S3DIS) and outdoor datasets (SemanticKITTI). Mix3D can be trivially used with any existing method, e.g., trained with Mix3D, MinkowskiNet outperforms all prior state-of-the-art methods by a significant margin on the ScanNet test benchmark 78.1 mIoU.
@inproceedings{Nekrasov213DV,
title = {{Mix3D: Out-of-Context Data Augmentation for 3D Scenes}},
author = {Nekrasov, Alexey and Schult, Jonas and Or, Litany and Leibe, Bastian and Engelmann, Francis},
booktitle = {{International Conference on 3D Vision (3DV)}},
year = {2021}
}
From Points to Multi-Object 3D Reconstruction

We propose a method to detect and reconstruct multiple 3D objects from a single RGB image. The key idea is to optimize for detection, alignment and shape jointly over all objects in the RGB image, while focusing on realistic and physically plausible reconstructions. To this end, we propose a keypoint detector that localizes objects as center points and directly predicts all object properties, including 9-DoF bounding boxes and 3D shapes -- all in a single forward pass. The proposed method formulates 3D shape reconstruction as a shape selection problem, i.e. it selects among exemplar shapes from a given database. This makes it agnostic to shape representations, which enables a lightweight reconstruction of realistic and visually-pleasing shapes based on CAD-models, while the training objective is formulated around point clouds and voxel representations. A collision-loss promotes non-intersecting objects, further increasing the reconstruction realism. Given the RGB image, the presented approach performs lightweight reconstruction in a single-stage, it is real-time capable, fully differentiable and end-to-end trainable. Our experiments compare multiple approaches for 9-DoF bounding box estimation, evaluate the novel shape-selection mechanism and compare to recent methods in terms of 3D bounding box estimation and 3D shape reconstruction quality.
@inproceedings{Engelmann21CVPR,
title = {{From Points to Multi-Object 3D Reconstruction}},
author = {Engelmann, Francis and Rematas, Konstantinos and Leibe, Bastian and Ferrari, Vittorio},
booktitle = {{IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}},
year = {2021}
}
MeTRAbs: Metric-Scale Truncation-Robust Heatmaps for Absolute 3D Human Pose Estimation

Heatmap representations have formed the basis of human pose estimation systems for many years, and their extension to 3D has been a fruitful line of recent research. This includes 2.5D volumetric heatmaps, whose X and Y axes correspond to image space and Z to metric depth around the subject. To obtain metric-scale predictions, 2.5D methods need a separate post-processing step to resolve scale ambiguity. Further, they cannot localize body joints outside the image boundaries, leading to incomplete estimates for truncated images. To address these limitations, we propose metric-scale truncation-robust (MeTRo) volumetric heatmaps, whose dimensions are all defined in metric 3D space, instead of being aligned with image space. This reinterpretation of heatmap dimensions allows us to directly estimate complete, metric-scale poses without test-time knowledge of distance or relying on anthropometric heuristics, such as bone lengths. To further demonstrate the utility our representation, we present a differentiable combination of our 3D metric-scale heatmaps with 2D image-space ones to estimate absolute 3D pose (our MeTRAbs architecture). We find that supervision via absolute pose loss is crucial for accurate non-root-relative localization. Using a ResNet-50 backbone without further learned layers, we obtain state-of-the-art results on Human3.6M, MPI-INF-3DHP and MuPoTS-3D. Our code is publicly available to facilitate further research.
Winning submission at the ECCV 2020 3D Poses in the Wild Challenge
» Show BibTeX
@article{Sarandi21metrabs,
title={{MeTRAbs:} Metric-Scale Truncation-Robust Heatmaps for Absolute {3D} Human Pose Estimation},
author={S\'ar\'andi, Istv\'an and Linder, Timm and Arras, Kai O. and Leibe, Bastian},
journal={IEEE Transactions on Biometrics, Behavior, and Identity Science},
year={2021},
volume={3},
number={1},
pages={16--30}
}
Reducing the Annotation Effort for Video Object Segmentation Datasets

For further progress in video object segmentation (VOS), larger, more diverse, and more challenging datasets will be necessary. However, densely labeling every frame with pixel masks does not scale to large datasets. We use a deep convolutional network to automatically create pseudo-labels on a pixel level from much cheaper bounding box annotations and investigate how far such pseudo-labels can carry us for training state-of-the-art VOS approaches. A very encouraging result of our study is that adding a manually annotated mask in only a single video frame for each object is sufficient to generate pseudo-labels which can be used to train a VOS method to reach almost the same performance level as when training with fully segmented videos. We use this workflow to create pixel pseudo-labels for the training set of the challenging tracking dataset TAO, and we manually annotate a subset of the validation set. Together, we obtain the new TAO-VOS benchmark, which we make publicly available at http://www.vision.rwth-aachen.de/page/taovos. While the performance of state-of-the-art methods on existing datasets starts to saturate, TAO-VOS remains very challenging for current algorithms and reveals their shortcomings.
@inproceedings{Voigtlaender21WACV,
title={Reducing the Annotation Effort for Video Object Segmentation Datasets},
author={Paul Voigtlaender and Lishu Luo and Chun Yuan and Yong Jiang and Bastian Leibe},
booktitle={WACV},
year={2021}
}
Person-MinkUNet: 3D Person Detection with LiDAR Point Cloud
In this preliminary work we attempt to apply submanifold sparse convolution to the task of 3D person detection. In particular, we present Person-MinkUNet, a single-stage 3D person detection network based on Minkowski Engine with U-Net architecture. The network achieves a 76.4% average precision (AP) on the JRDB 3D detection benchmark.
Winner of JRDB 3D detection challenge in JRDB-ACT Workshop at CVPR 2021
Self-Supervised Person Detection in 2D Range Data using a Calibrated Camera
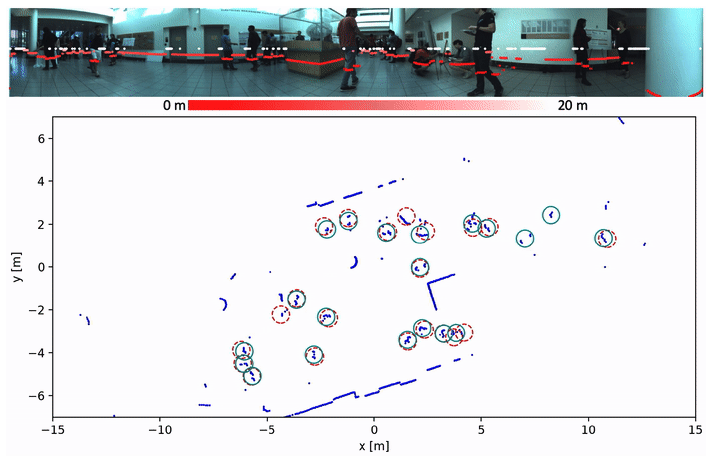
Deep learning is the essential building block of state-of-the-art person detectors in 2D range data. However, only a few annotated datasets are available for training and testing these deep networks, potentially limiting their performance when deployed in new environments or with different LiDAR models. We propose a method, which uses bounding boxes from an image-based detector (e.g. Faster R-CNN) on a calibrated camera to automatically generate training labels (called pseudo-labels) for 2D LiDAR-based person detectors. Through experiments on the JackRabbot dataset with two detector models, DROW3 and DR-SPAAM, we show that self- supervised detectors, trained or fine-tuned with pseudo-labels, outperform detectors trained using manual annotations from a different dataset. Combined with robust training techniques, the self-supervised detectors reach a performance close to the ones trained using manual annotations. Our method is an effective way to improve person detectors during deployment without any additional labeling effort, and we release our source code to support relevant robotic applications.
HOTA: A Higher Order Metric for Evaluating Multi-object Tracking
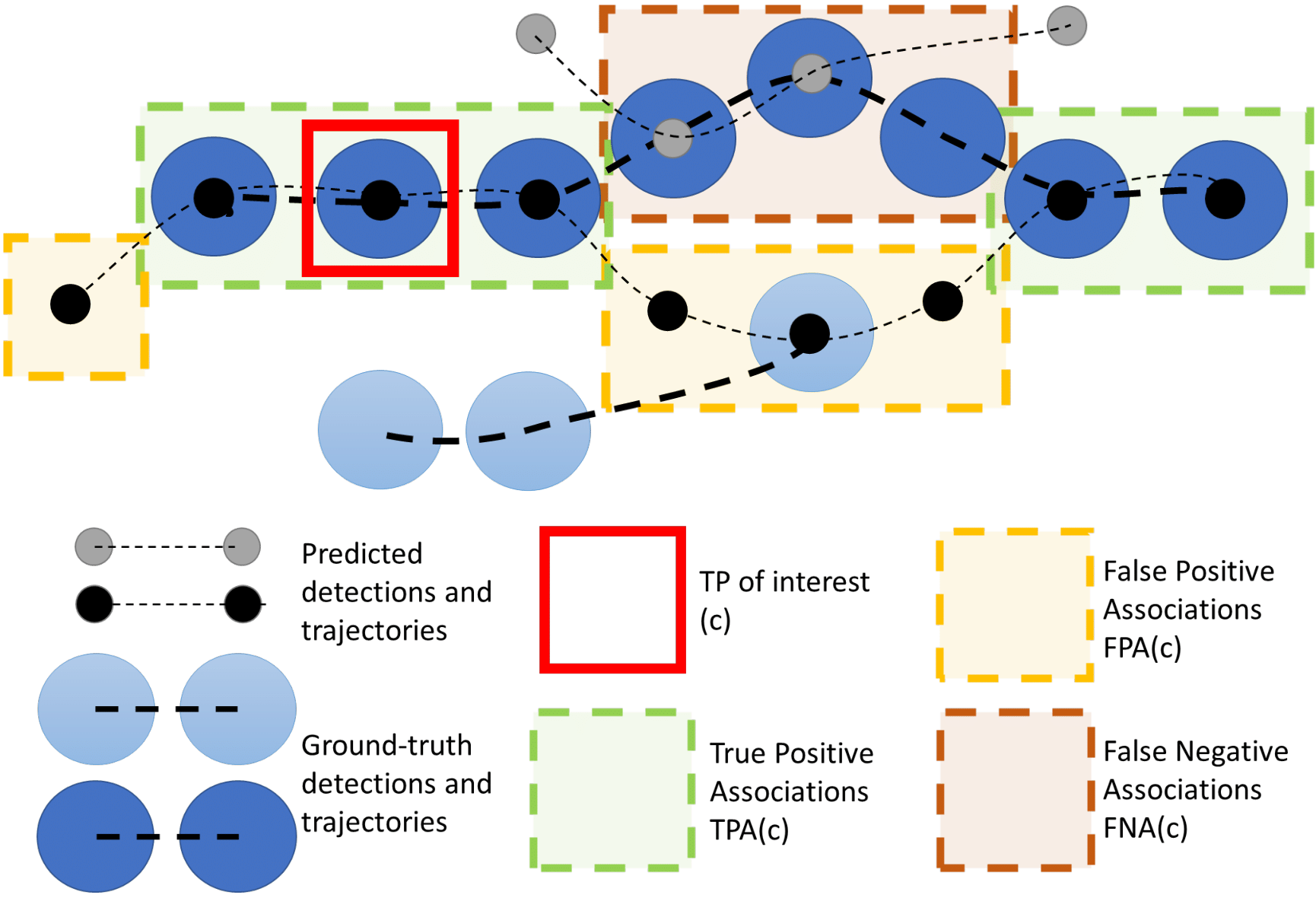
Multi-object tracking (MOT) has been notoriously difficult to evaluate. Previous metrics overemphasize the importance of either detection or association. To address this, we present a novel MOT evaluation metric, higher order tracking accuracy (HOTA), which explicitly balances the effect of performing accurate detection, association and localization into a single unified metric for comparing trackers. HOTA decomposes into a family of sub-metrics which are able to evaluate each of five basic error types separately, which enables clear analysis of tracking performance. We evaluate the effectiveness of HOTA on the MOTChallenge benchmark, and show that it is able to capture important aspects of MOT performance not previously taken into account by established metrics. Furthermore, we show HOTA scores better align with human visual evaluation of tracking performance.
@article{luiten2020IJCV,
title={HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking},
author={Luiten, Jonathon and Osep, Aljosa and Dendorfer, Patrick and Torr, Philip and Geiger, Andreas and Leal-Taix{\'e}, Laura and Leibe, Bastian},
journal={International Journal of Computer Vision},
pages={1--31},
year={2020},
publisher={Springer}
}
STEm-Seg: Spatio-temporal Embeddings for Instance Segmentation in Videos

Existing methods for instance segmentation in videos typically involve multi-stage pipelines that follow the tracking-by-detection paradigm and model a video clip as a sequence of images. Multiple networks are used to detect objects in individual frames, and then associate these detections over time. Hence, these methods are often non-end-to-end trainable and highly tailored to specific tasks. In this paper, we propose a different approach that is well-suited to a variety of tasks involving instance segmentation in videos. In particular, we model a video clip as a single 3D spatio-temporal volume, and propose a novel approach that segments and tracks instances across space and time in a single stage. Our problem formulation is centered around the idea of spatio-temporal embeddings which are trained to cluster pixels belonging to a specific object instance over an entire video clip. To this end, we introduce (i) novel mixing functions that enhance the feature representation of spatio-temporal embeddings, and (ii) a single-stage, proposal-free network that can reason about temporal context. Our network is trained end-to-end to learn spatio-temporal embeddings as well as parameters required to cluster these embeddings, thus simplifying inference. Our method achieves state-of-the-art results across multiple datasets and tasks.
» Show BibTeX
@inproceedings{AtharMahadevan20ECCV,
title={STEm-Seg: Spatio-temporal Embeddings for Instance Segmentation in Videos},
author={Athar, Ali and Mahadevan, Sabarinath and O{\v{s}}ep, Aljo{\v{s}}a and Leal-Taix{\'e}, Laura and Leibe, Bastian},
booktitle=ECCV,
year={2020}
}
3D-MPA: Multi Proposal Aggregation for 3D Semantic Instance Segmentation

We present 3D-MPA, a method for instance segmentation on 3D point clouds. Given an input point cloud, we propose an object-centric approach where each point votes for its object center. We sample object proposals from the predicted object centers. Then we learn proposal features from grouped point features that voted for the same object center. A graph convolutional network introduces inter-proposal relations, providing higher-level feature learning in addition to the lower-level point features. Each proposal comprises a semantic label, a set of associated points over which we define a foreground-background mask, an objectness score and aggregation features. Previous works usually perform non-maximum-suppression (NMS) over proposals to obtain the final object detections or semantic instances. However, NMS can discard potentially correct predictions. Instead, our approach keeps all proposals and groups them together based on the learned aggregation features. We show that grouping proposals improves over NMS and outperforms previous state-of-the-art methods on the tasks of 3D object detection and semantic instance segmentation on the ScanNetV2 benchmark and the S3DIS dataset.
@inproceedings{Engelmann20CVPR,
title = {{3D-MPA: Multi Proposal Aggregation for 3D Semantic Instance Segmentation}},
author = {Engelmann, Francis and Bokeloh, Martin and Fathi, Alireza and Leibe, Bastian and Nie{\ss}ner, Matthias},
booktitle = {{IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}},
year = {2020}
}
DualConvMesh-Net: Joint Geodesic and Euclidean Convolutions on 3D Meshes
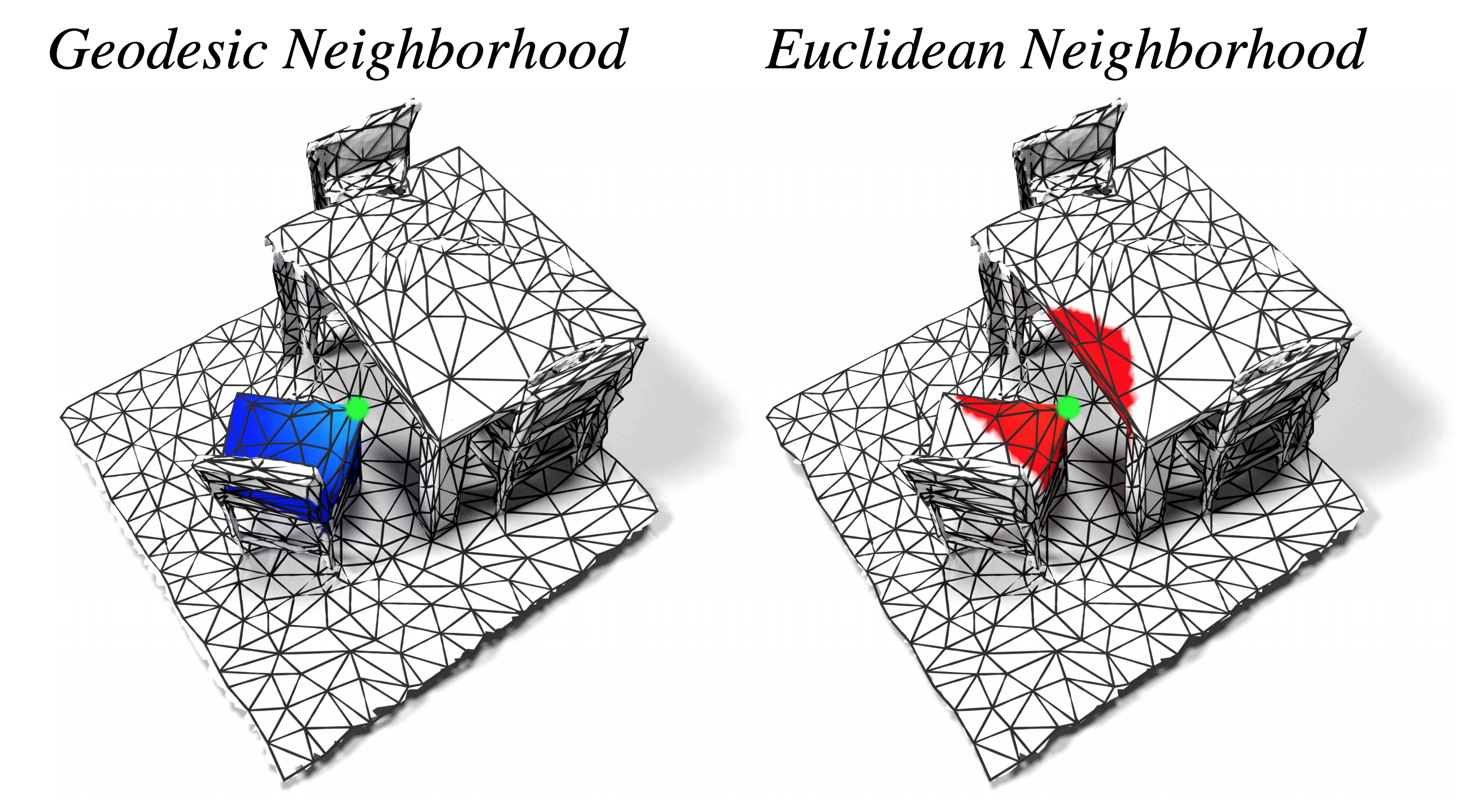
We propose DualConvMesh-Nets (DCM-Net) a family of deep hierarchical convolutional networks over 3D geometric data that combines two types of convolutions. The first type, geodesic convolutions, defines the kernel weights over mesh surfaces or graphs. That is, the convolutional kernel weights are mapped to the local surface of a given mesh. The second type, Euclidean convolutions, is independent of any underlying mesh structure. The convolutional kernel is applied on a neighborhood obtained from a local affinity representation based on the Euclidean distance between 3D points. Intuitively, geodesic convolutions can easily separate objects that are spatially close but have disconnected surfaces, while Euclidean convolutions can represent interactions between nearby objects better, as they are oblivious to object surfaces. To realize a multi-resolution architecture, we borrow well-established mesh simplification methods from the geometry processing domain and adapt them to define mesh-preserving pooling and unpooling operations. We experimentally show that combining both types of convolutions in our architecture leads to significant performance gains for 3D semantic segmentation, and we report competitive results on three scene segmentation benchmarks.
@inproceedings{Schult20CVPR,
author = {Jonas Schult* and
Francis Engelmann* and
Theodora Kontogianni and
Bastian Leibe},
title = {{DualConvMesh-Net: Joint Geodesic and Euclidean Convolutions on 3D Meshes}},
booktitle = {{IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}},
year = {2020}
}
Siam R-CNN: Visual Tracking by Re-Detection

We present Siam R-CNN, a Siamese re-detection architecture which unleashes the full power of two-stage object detection approaches for visual object tracking. We combine this with a novel tracklet-based dynamic programming algorithm, which takes advantage of re-detections of both the first-frame template and previous-frame predictions, to model the full history of both the object to be tracked and potential distractor objects. This enables our approach to make better tracking decisions, as well as to re-detect tracked objects after long occlusion. Finally, we propose a novel hard example mining strategy to improve Siam RCNN’s robustness to similar looking objects. The proposed tracker achieves the current best performance on ten tracking benchmarks, with especially strong results for long-term tracking.
@inproceedings{Voigtlaender20CVPR,
title={Siam R-CNN: Visual Tracking by Re-Detection},
author={Paul Voigtlaender and Jonathon Luiten and Philip H. S. Torr and Bastian Leibe},
year={2020},
booktitle={CVPR},
}
Making a Case for 3D Convolutions for Object Segmentation in Videos

The task of object segmentation in videos is usually accomplished by processing appearance and motion information separately using standard 2D convolutional networks, followed by a learned fusion of the two sources of information. On the other hand, 3D convolutional networks have been successfully applied for video classification tasks, but have not been leveraged as effectively to problems involving dense per-pixel interpretation of videos compared to their 2D convolutional counterparts and lag behind the aforementioned networks in terms of performance. In this work, we show that 3D CNNs can be effectively applied to dense video prediction tasks such as salient object segmentation. We propose a simple yet effective encoder-decoder network architecture consisting entirely of 3D convolutions that can be trained end-to-end using a standard cross-entropy loss. To this end, we leverage an efficient 3D encoder, and propose a 3D decoder architecture, that comprises novel 3D Global Convolution layers and 3D Refinement modules. Our approach outperforms existing state-of-the-arts by a large margin on the DAVIS'16 Unsupervised, FBMS and ViSal dataset benchmarks in addition to being faster, thus showing that our architecture can efficiently learn expressive spatio-temporal features and produce high quality video segmentation masks.
» Show BibTeX
@inproceedings{Mahadevan20BMVC,
title={Making a Case for 3D Convolutions for Object Segmentation in Videos},
author={Mahadevan, Sabarinath and Athar, Ali and O{\v{s}}ep, Aljo{\v{s}}a and Hennen, Sebastian and Leal-Taix{\'e}, Laura and Leibe, Bastian},
booktitle={BMVC},
year={2020}
}
Dilated Point Convolutions: On the Receptive Field Size of Point Convolutions on 3D Point Clouds
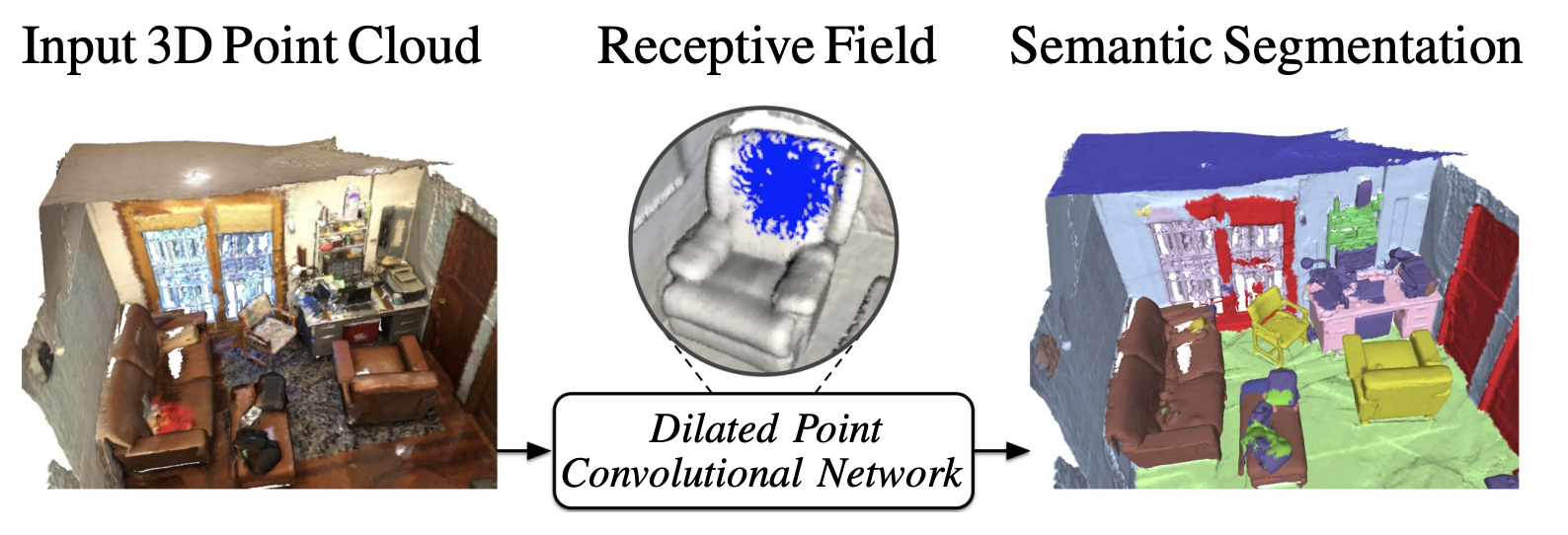
In this work, we propose Dilated Point Convolutions (DPC). In a thorough ablation study, we show that the receptive field size is directly related to the performance of 3D point cloud processing tasks, including semantic segmentation and object classification. Point convolutions are widely used to efficiently process 3D data representations such as point clouds or graphs. However, we observe that the receptive field size of recent point convolutional networks is inherently limited. Our dilated point convolutions alleviate this issue, they significantly increase the receptive field size of point convolutions. Importantly, our dilation mechanism can easily be integrated into most existing point convolutional networks. To evaluate the resulting network architectures, we visualize the receptive field and report competitive scores on popular point cloud benchmarks.
@inproceedings{Engelmann20ICRA,
author = {Engelmann, Francis and Kontogianni, Theodora and Leibe, Bastian},
title = {{Dilated Point Convolutions: On the Receptive Field Size of Point Convolutions on 3D Point Clouds}},
booktitle = {{International Conference on Robotics and Automation (ICRA)}},
year = {2020}
}
Track to Reconstruct and Reconstruct to Track

Object tracking and 3D reconstruction are often performed together, with tracking used as input for reconstruction. However, the obtained reconstructions also provide useful information for improving tracking. We propose a novel method that closes this loop, first tracking to reconstruct, and then reconstructing to track. Our approach, MOTSFusion (Multi-Object Tracking, Segmentation and dynamic object Fusion), exploits the 3D motion extracted from dynamic object reconstructions to track objects through long periods of complete occlusion and to recover missing detections. Our approach first builds up short tracklets using 2D optical flow, and then fuses these into dynamic 3D object reconstructions. The precise 3D object motion of these reconstructions is used to merge tracklets through occlusion into long-term tracks, and to locate objects when detections are missing. On KITTI, our reconstruction-based tracking reduces the number of ID switches of the initial tracklets by more than 50%, and outperforms all previous approaches for both bounding box and segmentation tracking.
@article{luiten2020track,
title={Track to Reconstruct and Reconstruct to Track},
author={Luiten, Jonathon and Fischer, Tobias and Leibe, Bastian},
journal={IEEE Robotics and Automation Letters},
volume={5},
number={2},
pages={1803--1810},
year={2020},
publisher={IEEE}
}
UnOVOST: Unsupervised Offline Video Object Segmentation and Tracking

We address Unsupervised Video Object Segmentation (UVOS), the task of automatically generating accurate pixel masks for salient objects in a video sequence and of tracking these objects consistently through time, without any input about which objects should be tracked. Towards solving this task, we present UnOVOST (Unsupervised Offline Video Object Segmentation and Tracking) as a simple and generic algorithm which is able to track and segment a large variety of objects. This algorithm builds up tracks in a number stages, first grouping segments into short tracklets that are spatio-temporally consistent, before merging these tracklets into long-term consistent object tracks based on their visual similarity. In order to achieve this we introduce a novel tracklet-based Forest Path Cutting data association algorithm which builds up a decision forest of track hypotheses before cutting this forest into paths that form long-term consistent object tracks. When evaluating our approach on the DAVIS 2017 Unsupervised dataset we obtain state-of-the-art performance with a mean J &F score of 67.9% on the val, 58% on the test-dev and 56.4% on the test-challenge benchmarks, obtaining first place in the DAVIS 2019 Unsupervised Video Object Segmentation Challenge. UnOVOST even performs competitively with many semi-supervised video object segmentation algorithms even though it is not given any input as to which objects should be tracked and segmented.
@inproceedings{luiten2020unovost,
title={UnOVOST: Unsupervised Offline Video Object Segmentation and Tracking},
author={Luiten, Jonathon and Zulfikar, Idil Esen and Leibe, Bastian},
booktitle={Proceedings of the IEEE Winter Conference on Applications in Computer Vision},
year={2020}
}
Metric-Scale Truncation-Robust Heatmaps for 3D Human Pose Estimation
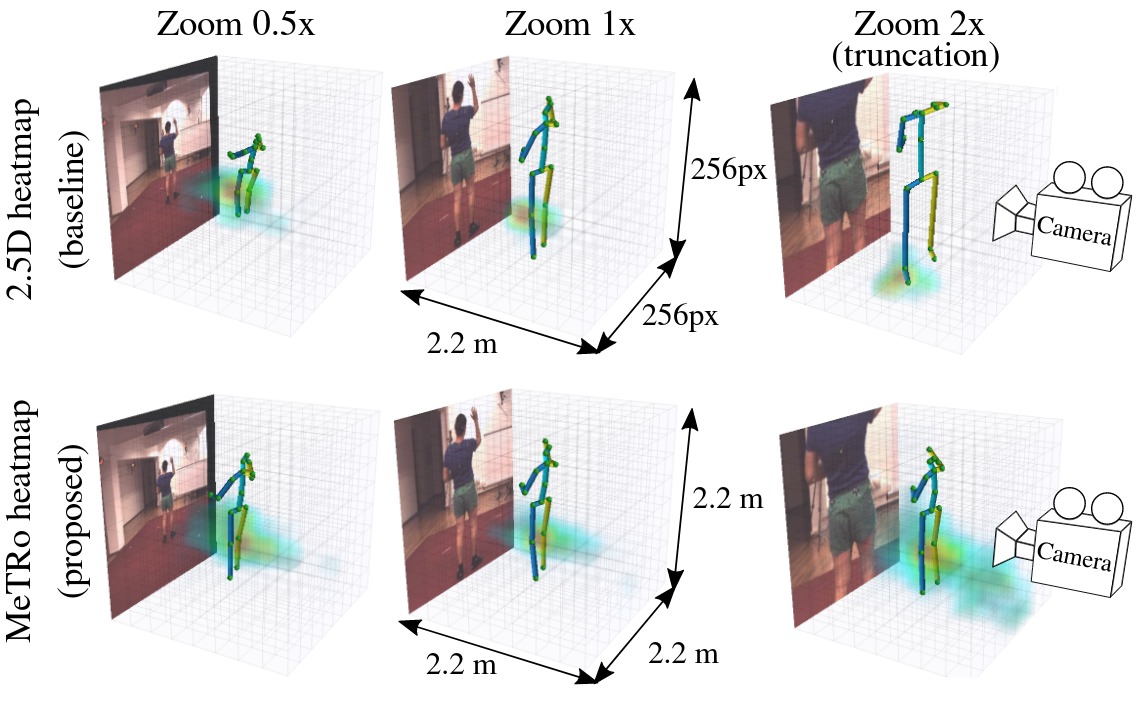
Heatmap representations have formed the basis of 2D human pose estimation systems for many years, but their generalizations for 3D pose have only recently been considered. This includes 2.5D volumetric heatmaps, whose X and Y axes correspond to image space and the Z axis to metric depth around the subject. To obtain metric-scale predictions, these methods must include a separate, explicit post-processing step to resolve scale ambiguity. Further, they cannot encode body joint positions outside of the image boundaries, leading to incomplete pose estimates in case of image truncation. We address these limitations by proposing metric-scale truncation-robust (MeTRo) volumetric heatmaps, whose dimensions are defined in metric 3D space near the subject, instead of being aligned with image space. We train a fully-convolutional network to estimate such heatmaps from monocular RGB in an end-to-end manner. This reinterpretation of the heatmap dimensions allows us to estimate complete metric-scale poses without test-time knowledge of the focal length or person distance and without relying on anthropometric heuristics in post-processing. Furthermore, as the image space is decoupled from the heatmap space, the network can learn to reason about joints beyond the image boundary. Using ResNet-50 without any additional learned layers, we obtain state-of-the-art results on the Human3.6M and MPI-INF-3DHP benchmarks. As our method is simple and fast, it can become a useful component for real-time top-down multi-person pose estimation systems. We make our code publicly available to facilitate further research.
See also the extended journal version of this paper at https://vision.rwth-aachen.de/publication/00203 (journal version preferred for citation).
» Show BibTeX
@inproceedings{Sarandi20metro,
title={Metric-Scale Truncation-Robust Heatmaps for {3D} Human Pose Estimation},
author={S\'ar\'andi, Istv\'an and Linder, Timm and Arras, Kai O. and Leibe, Bastian},
booktitle={IEEE International Conference on Automatic Face and Gesture Recognition (FG)},
year={2020}
}
Reposing Humans by Warping 3D Features
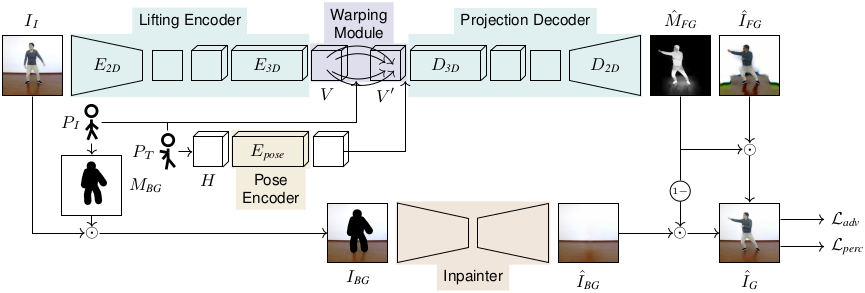
We address the problem of reposing an image of a human into any desired novel pose. This conditional image-generation task requires reasoning about the 3D structure of the human, including self-occluded body parts. Most prior works are either based on 2D representations or require fitting and manipulating an explicit 3D body mesh. Based on the recent success in deep learning-based volumetric representations, we propose to implicitly learn a dense feature volume from human images, which lends itself to simple and intuitive manipulation through explicit geometric warping. Once the latent feature volume is warped according to the desired pose change, the volume is mapped back to RGB space by a convolutional decoder. Our state-of-the-art results on the DeepFashion and the iPER benchmarks indicate that dense volumetric human representations are worth investigating in more detail.
» Show BibTeX
@inproceedings{Knoche20reposing,
author = {Markus Knoche and Istv\'an S\'ar\'andi and Bastian Leibe},
title = {Reposing Humans by Warping {3D} Features},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)},
year = {2020}
}
Single-Shot Panoptic Segmentation
We present a novel end-to-end single-shot method that segments countable object instances (things) as well as background regions (stuff) into a non-overlapping panoptic segmentation at almost video frame rate. Current state-of-the-art methods are far from reaching video frame rate and mostly rely on merging instance segmentation with semantic background segmentation. Our approach relaxes this requirement by using an object detector but is still able to resolve inter- and intra-class overlaps to achieve a non-overlapping segmentation. On top of a shared encoder-decoder backbone, we utilize multiple branches for semantic segmentation, object detection, and instance center prediction. Finally, our panoptic head combines all outputs into a panoptic segmentation and can even handle conflicting predictions between branches as well as certain false predictions. Our network achieves 32.6% PQ on MS-COCO at 21.8 FPS, opening up panoptic segmentation to a broader field of applications.
@article{weber2019single,
title={Single-Shot Panoptic Segmentation},
author={Weber, Mark and Luiten, Jonathon and Leibe, Bastian},
journal={arXiv preprint arXiv:1911.00764},
year={2019}
}
DR-SPAAM: A Spatial-Attention and Auto-regressive Model for Person Detection in 2D Range Data

Detecting persons using a 2D LiDAR is a challenging task due to the low information content of 2D range data. To alleviate the problem caused by the sparsity of the LiDAR points, current state-of-the-art methods fuse multiple previous scans and perform detection using the combined scans. The downside of such a backward looking fusion is that all the scans need to be aligned explicitly, and the necessary alignment operation makes the whole pipeline more expensive -- often too expensive for real-world applications. In this paper, we propose a person detection network which uses an alternative strategy to combine scans obtained at different times. Our method, Distance Robust SPatial Attention and Auto-regressive Model (DR-SPAAM), follows a forward looking paradigm. It keeps the intermediate features from the backbone network as a template and recurrently updates the template when a new scan becomes available. The updated feature template is in turn used for detecting persons currently in the scene. On the DROW dataset, our method outperforms the existing state-of-the-art, while being approximately four times faster, running at 87.2 FPS on a laptop with a dedicated GPU and at 22.6 FPS on an NVIDIA Jetson AGX embedded GPU. We release our code in PyTorch and a ROS node including pre-trained models.
Jetson project of the month for September 2020
FEELVOS: Fast End-to-End Embedding Learning for Video Object Segmentation
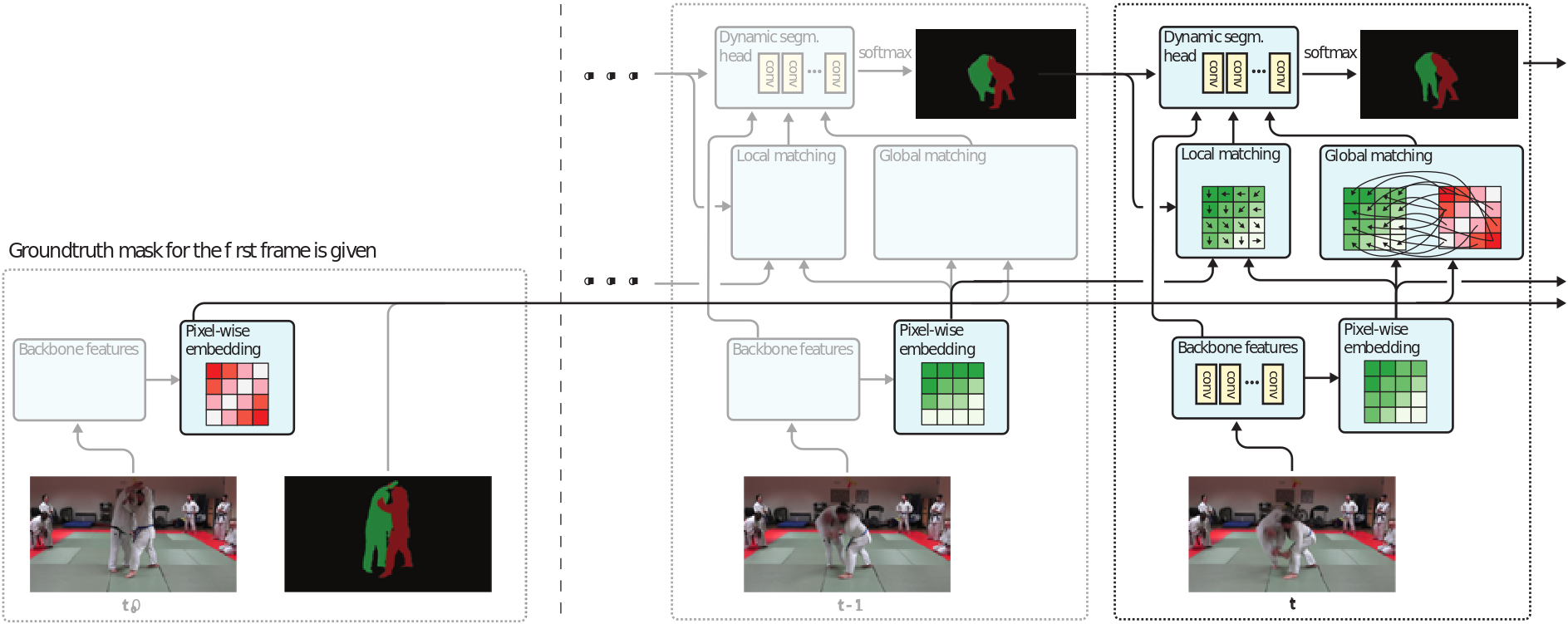
Many of the recent successful methods for video object segmentation (VOS) are overly complicated, heavily rely on fine-tuning on the first frame, and/or are slow, and are hence of limited practical use. In this work, we propose FEELVOS as a simple and fast method which does not rely on fine-tuning. In order to segment a video, for each frame FEELVOS uses a semantic pixel-wise embedding together with a global and a local matching mechanism to transfer information from the first frame and from the previous frame of the video to the current frame. In contrast to previous work, our embedding is only used as an internal guidance of a convolutional network. Our novel dynamic segmentation head allows us to train the network, including the embedding, end-to-end for the multiple object segmentation task with a cross entropy loss. We achieve a new state of the art in video object segmentation without fine-tuning with a J&F measure of 71.5% on the DAVIS 2017 validation set. We make our code and models available at https://github.com/tensorflow/models/tree/master/research/feelvos.
@inproceedings{Voigtlaender19CVPR,
title={{FEELVOS}: Fast End-to-End Embedding Learning for Video Object Segmentation},
author={Paul Voigtlaender and Yuning Chai and Florian Schroff and Hartwig Adam and Bastian Leibe and Liang-Chieh Chen},
booktitle={CVPR},
year={2019}
}
MOTS: Multi-Object Tracking and Segmentation

This paper extends the popular task of multi-object tracking to multi-object tracking and segmentation (MOTS). Towards this goal, we create dense pixel-level annotations for two existing tracking datasets using a semi-automatic annotation procedure. Our new annotations comprise 65,213 pixel masks for 977 distinct objects (cars and pedestrians) in 10,870 video frames. For evaluation, we extend existing multi-object tracking metrics to this new task. Moreover, we propose a new baseline method which jointly addresses detection, tracking, and segmentation with a single convolutional network. We demonstrate the value of our datasets by achieving improvements in performance when training on MOTS annotations. We believe that our datasets, metrics and baseline will become a valuable resource towards developing multi-object tracking approaches that go beyond 2D bounding boxes. We make our annotations, code, and models available at https://www.vision.rwth-aachen.de/page/mots.
» Show BibTeX
@inproceedings{Voigtlaender19CVPR_MOTS,
author = {Paul Voigtlaender and Michael Krause and Aljo\u{s}a O\u{s}ep and Jonathon Luiten and Berin Balachandar Gnana Sekar and Andreas Geiger and Bastian Leibe},
title = {{MOTS}: Multi-Object Tracking and Segmentation},
booktitle = {CVPR},
year = {2019},
}
AlignNet-3D: Fast Point Cloud Registration of Partially Observed Objects

Methods tackling multi-object tracking need to estimate the number of targets in the sensing area as well as to estimate their continuous state. While the majority of existing methods focus on data association, precise state (3D pose) estimation is often only coarsely estimated by approximating targets with centroids or (3D) bounding boxes. However, in automotive scenarios, motion perception of surrounding agents is critical and inaccuracies in the vehicle close-range can have catastrophic consequences. In this work, we focus on precise 3D track state estimation and propose a learning-based approach for object-centric relative motion estimation of partially observed objects. Instead of approximating targets with their centroids, our approach is capable of utilizing noisy 3D point segments of objects to estimate their motion. To that end, we propose a simple, yet effective and efficient network, AlignNet-3D, that learns to align point clouds. Our evaluation on two different datasets demonstrates that our method outperforms computationally expensive, global 3D registration methods while being significantly more efficient.
@inproceedings{Gross193DV,
title = {AlignNet-3D: Fast Point Cloud Registration of Partially Observed Objects},
author = {Johannes Gro\ss and Aljo\v{s}a O\v{s}ep and Bastian Leibe},
booktitle = {International Conference on 3D Vision {(3DV)}},
year = {2019}
}
Large-Scale Object Mining for Object Discovery from Unlabeled Video
This paper addresses the problem of object discovery from unlabeled driving videos captured in a realistic automotive setting. Identifying recurring object categories in such raw video streams is a very challenging problem. Not only do object candidates first have to be localized in the input images, but many interesting object categories occur relatively infrequently. Object discovery will therefore have to deal with the difficulties of operating in the long tail of the object distribution. We demonstrate the feasibility of performing fully automatic object discovery in such a setting by mining object tracks using a generic object tracker. In order to facilitate further research in object discovery, we will release a collection of more than 360'000 automatically mined object tracks from 10+ hours of video data (560'000 frames). We use this dataset to evaluate the suitability of different feature representations and clustering strategies for object discovery.
@article{Osep19ICRA,
author = {O\v{s}ep, Aljo\v{s}a and Voigtlaender, Paul and Luiten, Jonathon and Breuers, Stefan and Leibe, Bastian},
title = {Large-Scale Object Mining for Object Discovery from Unlabeled Video},
journal = {ICRA},
year = {2019}
}
4D Generic Video Object Proposals

Many high-level video understanding methods require input in the form of object proposals. Currently, such proposals are predominantly generated with the help of networks that were trained for detecting and segmenting a set of known object classes, which limits their applicability to cases where all objects of interest are represented in the training set. This is a restriction for automotive scenarios, where unknown objects can frequently occur. We propose an approach that can reliably extract spatio-temporal object proposals for both known and unknown object categories from stereo video. Our 4D Generic Video Tubes (4D-GVT) method leverages motion cues, stereo data, and object instance segmentation to compute a compact set of video-object proposals that precisely localizes object candidates and their contours in 3D space and time. We show that given only a small amount of labeled data, our 4D-GVT proposal generator generalizes well to real-world scenarios, in which unknown categories appear. It outperforms other approaches that try to detect as many objects as possible by increasing the number of classes in the training set to several thousand.
@inproceedings{Osep19ICRA,
author = {O\v{s}ep, Aljo\v{s}a and Voigtlaender, Paul and Weber, Mark and Luiten, Jonathon and Leibe, Bastian},
title = {4D Generic Video Object Proposals},
booktitle = {ICRA},
year = {2020}
}
Combining PReMVOS with Box-Level Tracking for the 2019 DAVIS Challenge
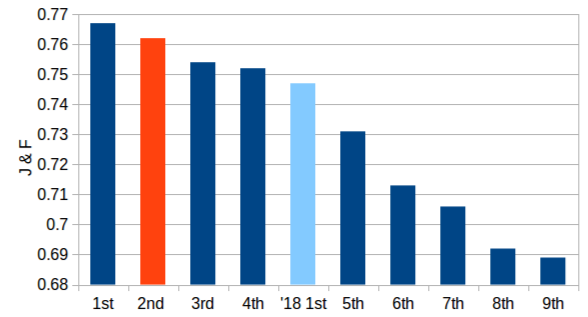
Recently a number of different approaches have beenproposed for tackling the task of Video Object Segmentation(VOS). In this paper we compare and contrast two particu-larly powerful methods, PReMVOS (Proposal-generation,Refinement and Merging for VOS), and BoLTVOS (Box-Level Tracking for VOS). PReMVOS follows a tracking-by-detection framework in which a set of object proposals aregenerated per frame and are then linked into tracks overtime by optical flow and appearance similarity cues. In con-trast, BoLTVOS uses a Siamese architecture to directly de-tect the object to be tracked based on its similarity to thegiven first-frame object. Although BoLTVOS can outper-form PReMVOS when the number of objects to be trackedis small, it does not scale as well to tracking multiple ob-jects. Finally we develop a model which combines bothBoLTVOS and PReMVOS and achieves aJ&Fscore of76.2% on the DAVIS 2017 test-challenge benchmark, re-sulting in a 2nd place finish in the 2019 DAVIS challengeon semi-supervised VOS.
@article{LuitenDAVIS2019,
title={Combining PReMVOS with Box-Level Tracking for the 2019 DAVIS Challenge},
author={Luiten, Jonathon and Voigtlaender, Paul and Leibe, Bastian},
booktitle = {The 2019 DAVIS Challenge on Video Object Segmentation - CVPR Workshops},
year = {2019}
}
Visual Person Understanding through Multi-Task and Multi-Dataset Learning
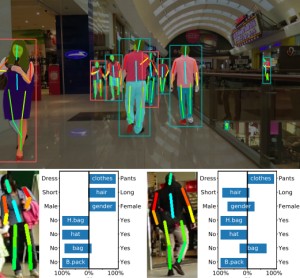
We address the problem of learning a single model for person re-identification, attribute classification, body part segmentation, and pose estimation. With predictions for these tasks we gain a more holistic understanding of persons, which is valuable for many applications. This is a classical multi-task learning problem. However, no dataset exists that these tasks could be jointly learned from. Hence several datasets need to be combined during training, which in other contexts has often led to reduced performance in the past. We extensively evaluate how the different task and datasets influence each other and how different degrees of parameter sharing between the tasks affect performance. Our final model matches or outperforms its single-task counterparts without creating significant computational overhead, rendering it highly interesting for resource-constrained scenarios such as mobile robotics.
@inproceedings{Pfeiffer19GCPR,
title = {Visual Person Understanding Through Multi-task and Multi-dataset Learning},
author = {Kilian Pfeiffer and Alexander Hermans and Istv\'{a}n S\'{a}r\'{a}ndi and Mark Weber and Bastian Leibe},
booktitle = {German Conference on Pattern Recognition (GCPR)},
date = {2019}
}
Video Instance Segmentation 2019: A winning approach for combined Detection, Segmentation, Classification and Tracking.
Video Instance Segmentation (VIS) is the task of localizing all objects in a video, segmenting them, tracking them throughout the video and classifying them into a set of predefined classes. In this work, divide VIS into these four parts: detection, segmentation, tracking and classification. We then develop algorithms for performing each of these four sub tasks individually, and combine these into a complete solution for VIS. Our solution is an adaptation of UnOVOST, the current best performing algorithm for Unsupervised Video Object Segmentation, to this VIS task. We benchmark our algorithm on the 2019 YouTube-VIS Challenge, where we obtain first place with an mAP score of 46.7%.
@inproceedings{Luiten19ICCVW_Video,
author = {Jonathon Luiten and Philip Torr and Bastian Leibe},
title = {{Video Instance Segmentation 2019: A winning approach for combined Detection, Segmentation, Classification and Tracking.}},
booktitle = {The 2nd Large-scale Video Object Segmentation Challenge: International Conference on Computer Vision Workshop (ICCVW)},
year = {2019},
}
UnOVOST: Unsupervised Offline Video Object Segmentation and Tracking for the 2019 Unsupervised DAVIS Challenge

We address Unsupervised Video Object Segmentation (UVOS), the task of automatically generating accurate pixelmasks for salient objects in a video sequence and of track-ing these objects consistently through time, without any in-formation about which objects should be tracked. Towardssolving this task, we present UnOVOST (Unsupervised Of-fline Video Object Segmentation and Tracking) as a simpleand generic algorithm which is able to track a large varietyof objects. This algorithm hierarchically builds up tracksin five stages. First, object proposal masks are generatedusing Mask R-CNN. Second, masks are sub-selected andclipped so that they do not overlap in the image domain.Third, tracklets are generated by grouping object propos-als that are strongly temporally consistent with each otherunder optical flow warping. Fourth, tracklets are mergedinto long-term consistent object tracks using their temporalconsistency and an appearance similarity metric calculatedusing an object re-identification network. Finally, the mostsalient object tracks are selected based on temporal tracklength and detection confidence scores. We evaluate ourapproach on the DAVIS 2017 Unsupervised dataset and ob-tain state-of-the-art performance with a meanJ&Fscoreof 58% on the test-dev benchmark. Our approach furtherachieves first place in the DAVIS 2019 Unsupervised VideoObject Segmentation Challenge with a mean ofJ&Fscoreof 56.4% on the test-challenge benchmark.
@article{ZulfikarLuitenUnOVOST,
title={UnOVOST: Unsupervised Offline Video Object Segmentation and Tracking for the 2019 Unsupervised DAVIS Challenge},
author={Zulfikar, Idil Esen and Luiten, Jonathon and Leibe, Bastian}
booktitle = {The 2019 DAVIS Challenge on Video Object Segmentation - CVPR Workshops},
year = {2019}
}
Exploring the Combination of PReMVOS, BoLTVOS and UnOVOST for the 2019 YouTube-VOS Challenge
Video Object Segmentation is the task of tracking and segmenting objects in a video given the first-frame mask of objects to be tracked. There have been a number of different successful paradigms for tackling this task, from creating object proposals and linking them in time as in PReMVOS, to detecting objects to be tracked conditioned on the given first-frame as in BoLTVOS, and creating tracklets based on motion consistency before merging these into long-term tracks as in UnOVOST. In this paper we explore how these three different approaches can be combined into a novel Video Object Segmentation algorithm. We evaluate our approach on the 2019 Youtube-VOS challenge where we obtain 6th place with an overall score of 71.5%.
@inproceedings{Luiten19ICCVW_Video,
author = {Jonathon Luiten and Paul Voigtlaender and Bastian Leibe},
title = {{Exploring the Combination of PReMVOS, BoLTVOS and UnOVOST for the 2019 YouTube-VOS Challenge}},
booktitle = {The 2nd Large-scale Video Object Segmentation Challenge: International Conference on Computer Vision Workshop (ICCVW)},
year = {2019},
}
BoLTVOS: Box-Level Tracking for Video Object Segmentation

We approach video object segmentation (VOS) by splitting the task into two sub-tasks: bounding box level tracking, followed by bounding box segmentation. Following this paradigm, we present BoLTVOS (Box Level Tracking for VOS), which consists of an R-CNN detector conditioned on the first-frame bounding box to detect the object of interest, a temporal consistency rescoring algorithm, and a Box2Seg network that converts bounding boxes to segmentation masks. BoLTVOS performs VOS using only the first-frame bounding box without the mask. We evaluate our approach on DAVIS 2017 and YouTube-VOS, and show that it outperforms all methods that do not perform first-frame fine-tuning. We further present BoLTVOS-ft, which learns to segment the object in question using the first-frame mask while it is being tracked, without increasing the runtime. BoLTVOS-ft outperforms PReMVOS, the previously best performing VOS method on DAVIS 2016 and YouTube-VOS, while running up to 45 times faster. Our bounding box tracker also outperforms all previous short-term and longterm trackers on the bounding box level tracking datasets OTB 2015 and LTB35.
@article{VoigtlaenderLuiten19arxiv,
author = {Paul Voigtlaender and Jonathon Luiten and Bastian Leibe},
title = {{BoLTVOS: Box-Level Tracking for Video Object Segmentation}},
journal = {arXiv:1904.04552},
year = {2019}
}
3D-BEVIS: Birds-Eye-View Instance Segmentation
Recent deep learning models achieve impressive results on 3D scene analysis tasks by operating directly on unstructured point clouds. A lot of progress was made in the field of object classification and semantic segmentation. However, the task of instance segmentation is less explored. In this work, we present 3D-BEVIS, a deep learning framework for 3D semantic instance segmentation on point clouds. Following the idea of previous proposal-free instance segmentation approaches, our model learns a feature embedding and groups the obtained feature space into semantic instances. Current point-based methods scale linearly with the number of points by processing local sub-parts of a scene individually. However, to perform instance segmentation by clustering, globally consistent features are required. Therefore, we propose to combine local point geometry with global context information from an intermediate bird's-eye view representation.
@inproceedings{ElichGCPR19,
title = {{3D-BEVIS: Birds-Eye-View Instance Segmentation}},
author = {Elich, Cathrin and Engelmann, Francis and Schult, Jonas and Kontogianni, Theodora and Leibe, Bastian},
booktitle = {{German Conference on Pattern Recognition (GCPR)}},
year = {2019}
}
PReMVOS: Proposal-generation, Refinement and Merging for Video Object Segmentation
We address semi-supervised video object segmentation, the task of automatically generating accurate and consistent pixel masks for objects in a video sequence, given the first-frame ground truth annotations. Towards this goal, we present the PReMVOS algorithm (Proposalgeneration, Refinement and Merging for Video Object Segmentation). Our method separates this problem into two steps, first generating a set of accurate object segmentation mask proposals for each video frame and then selecting and merging these proposals into accurate and temporally consistent pixel-wise object tracks over a video sequence in a way which is designed to specifically tackle the difficult challenges involved with segmenting multiple objects across a video sequence. Our approach surpasses all previous state-of-the-art results on the DAVIS 2017 video object egmentation benchmark with a J & F mean score of 71.6 on the test-dev dataset, and achieves first place in both the DAVIS 2018 Video Object Segmentation Challenge and the YouTube-VOS 1st Large-scale Video Object Segmentation Challenge.
@inproceedings{luiten2018premvos,
title={PReMVOS: Proposal-generation, Refinement and Merging for Video Object Segmentation},
author={Jonathon Luiten and Paul Voigtlaender and Bastian Leibe},
booktitle={Asian Conference on Computer Vision},
year={2018}
}
Track, then Decide: Category-Agnostic Vision-based Multi-Object Tracking

The most common paradigm for vision-based multi-object tracking is tracking-by-detection, due to the availability of reliable detectors for several important object categories such as cars and pedestrians. However, future mobile systems will need a capability to cope with rich human-made environments, in which obtaining detectors for every possible object category would be infeasible. In this paper, we propose a model-free multi-object tracking approach that uses a category-agnostic image segmentation method to track objects. We present an efficient segmentation mask-based tracker which associates pixel-precise masks reported by the segmentation. Our approach can utilize semantic information whenever it is available for classifying objects at the track level, while retaining the capability to track generic unknown objects in the absence of such information. We demonstrate experimentally that our approach achieves performance comparable to state-of-the-art tracking-by-detection methods for popular object categories such as cars and pedestrians. Additionally, we show that the proposed method can discover and robustly track a large variety of other objects.
@article{Osep18ICRA,
author = {O\v{s}ep, Aljo\v{s}a and Mehner, Wolfgang and Voigtlaender, Paul and Leibe, Bastian},
title = {Track, then Decide: Category-Agnostic Vision-based Multi-Object Tracking},
journal = {ICRA},
year = {2018}
}
Know What Your Neighbors Do: 3D Semantic Segmentation of Point Clouds
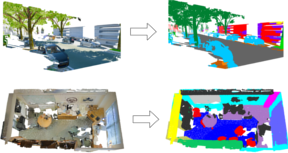
In this paper, we present a deep learning architecture which addresses the problem of 3D semantic segmentation of unstructured point clouds. Compared to previous work, we introduce grouping techniques which define point neighborhoods in the initial world space and the learned feature space. Neighborhoods are important as they allow to compute local or global point features depending on the spatial extend of the neighborhood. Additionally, we incorporate dedicated loss functions to further structure the learned point feature space: the pairwise distance loss and the centroid loss. We show how to apply these mechanisms to the task of 3D semantic segmentation of point clouds and report state-of-the-art performance on indoor and outdoor datasets.
@inproceedings{3dsemseg_ECCVW18,
author = {Francis Engelmann and
Theodora Kontogianni and
Jonas Schult and
Bastian Leibe},
title = {Know What Your Neighbors Do: 3D Semantic Segmentation of Point Clouds},
booktitle = {{IEEE} European Conference on Computer Vision, GMDL Workshop, {ECCV}},
year = {2018}
}
PReMVOS: Proposal-generation, Refinement and Merging for the DAVIS Challenge on Video Object Segmentation 2018
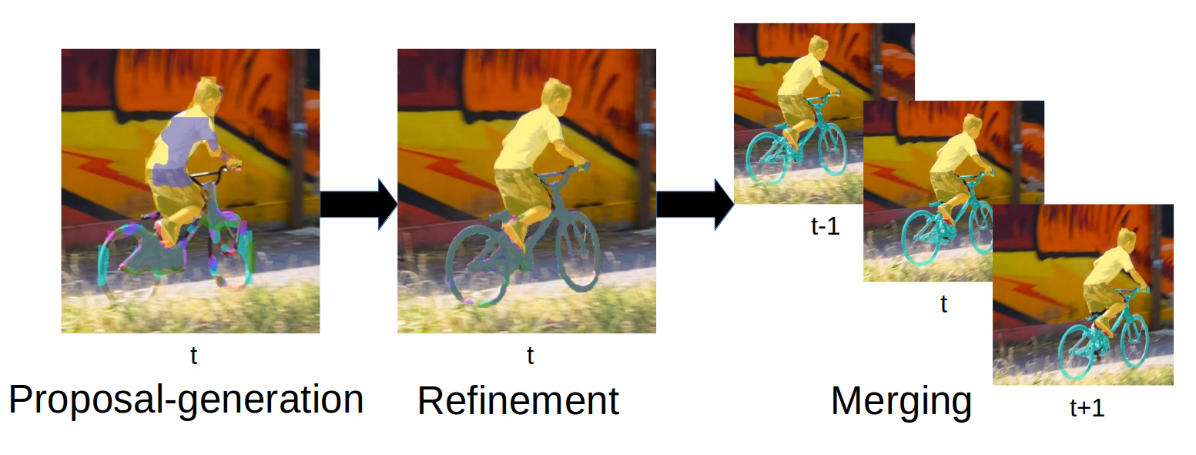
We address semi-supervised video object segmentation, the task of automatically generating accurate and consistent pixel masks for objects in a video sequence, given the first-frame ground truth annotations. Towards this goal, we present the PReMVOS algorithm (Proposal-generation, Refinement and Merging for Video Object Segmentation). This method involves generating coarse object proposals using a Mask R-CNN like object detector, followed by a refinement network that produces accurate pixel masks for each proposal. We then select and link these proposals over time using a merging algorithm that takes into account an objectness score, the optical flow warping, and a Re-ID feature embedding vector for each proposal. We adapt our networks to the target video domain by fine-tuning on a large set of augmented images generated from the first-frame ground truth. Our approach surpasses all previous state-of-the-art results on the DAVIS 2017 video object segmentation benchmark and achieves first place in the DAVIS 2018 Video Object Segmentation Challenge with a mean of J & F score of 74.7.
@article{Luiten18CVPRW,
author = {Jonathon Luiten and Paul Voigtlaender and Bastian Leibe},
title = {{PReMVOS: Proposal-generation, Refinement and Merging for the DAVIS Challenge on Video Object Segmentation 2018}},
journal = {The 2018 DAVIS Challenge on Video Object Segmentation - CVPR Workshops},
year = {2018}
}
How Robust is 3D Human Pose Estimation to Occlusion?
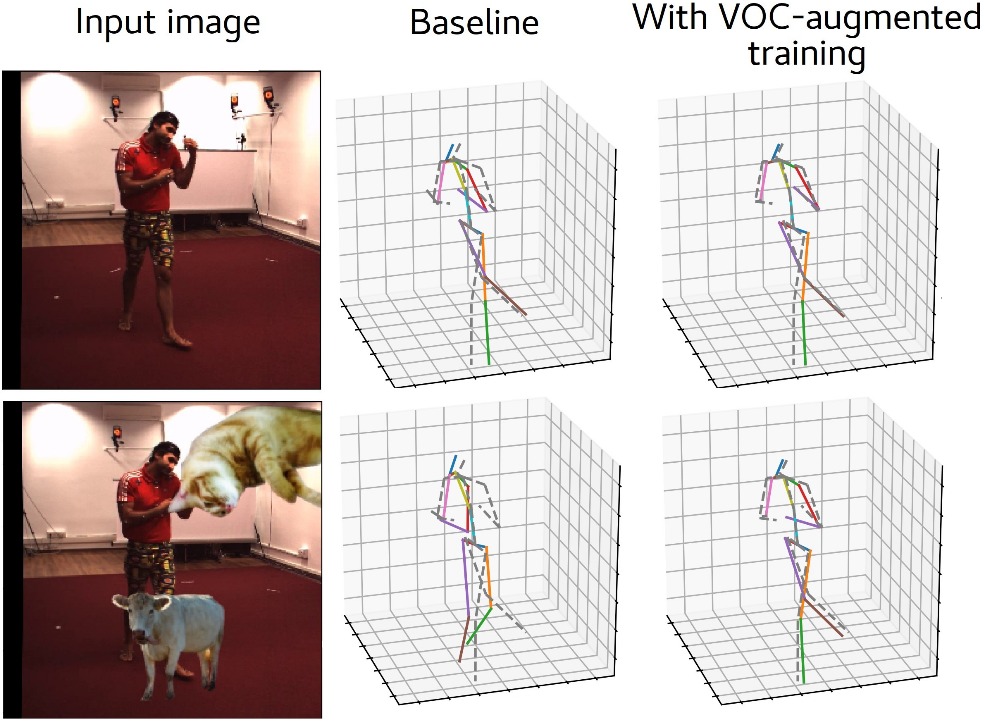
Occlusion is commonplace in realistic human-robot shared environments, yet its effects are not considered in standard 3D human pose estimation benchmarks. This leaves the question open: how robust are state-of-the-art 3D pose estimation methods against partial occlusions? We study several types of synthetic occlusions over the Human3.6M dataset and find a method with state-of-the-art benchmark performance to be sensitive even to low amounts of occlusion. Addressing this issue is key to progress in applications such as collaborative and service robotics. We take a first step in this direction by improving occlusion-robustness through training data augmentation with synthetic occlusions. This also turns out to be an effective regularizer that is beneficial even for non-occluded test cases.
@inproceedings{Sarandi18IROSW,
title={How Robust is {3D} Human Pose Estimation to Occlusion?},
author={S\'ar\'andi, Istv\'an and Linder, Timm and Arras, Kai O. and Leibe, Bastian},
booktitle={IEEE/RSJ International Conference on Intelligent Robots and Systems Workshops (IROSW)},
year={2018}
}
PReMVOS: Proposal-generation, Refinement and Merging for the YouTube-VOS Challenge on Video Object Segmentation 2018
We evaluate our PReMVOS algorithm [1]2 on the new YouTube-VOS dataset [3] for the task of semi-supervised video object segmentation (VOS). This task consists of automatically generating accurate and consistent pixel masks for multiple objects in a video sequence, given the object’s first-frame ground truth annotations. The new YouTube-VOS dataset and the corresponding challenge, the 1st Large-scale Video Object Segmentation Challenge, provide a much larger scale evaluation than any previous VOS benchmarks. Our method achieves the best results in the 2018 Large-scale Video Object Segmentation Challenge with a J &F overall mean score over both known and unknown categories of 72.2.
@article{Luiten18ECCVW,
author = {Jonathon Luiten and Paul Voigtlaender and Bastian Leibe},
title = {{PReMVOS: Proposal-generation, Refinement and Merging for the YouTube-VOS Challenge on Video Object Segmentation 2018}},
journal = {The 1st Large-scale Video Object Segmentation Challenge - ECCV Workshops},
year = {2018}
}
Synthetic Occlusion Augmentation with Volumetric Heatmaps for the 2018 ECCV PoseTrack Challenge on 3D Human Pose Estimation
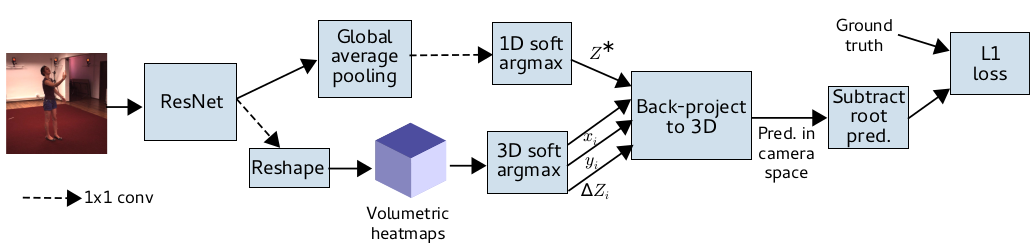
In this paper we present our winning entry at the 2018 ECCV PoseTrack Challenge on 3D human pose estimation. Using a fully-convolutional backbone architecture, we obtain volumetric heatmaps per body joint, which we convert to coordinates using soft-argmax. Absolute person center depth is estimated by a 1D heatmap prediction head. The coordinates are back-projected to 3D camera space, where we minimize the L1 loss. Key to our good results is the training data augmentation with randomly placed occluders from the Pascal VOC dataset. In addition to reaching first place in the Challenge, our method also surpasses the state-of-the-art on the full Human3.6M benchmark when considering methods that use no extra pose datasets in training. Code for applying synthetic occlusions is availabe at https://github.com/isarandi/synthetic-occlusion.
» Show BibTeX
@article{Sarandi18synthocc,
author = {S\'ar\'andi, Istv\'an and Linder, Timm and Arras, Kai O. and Leibe, Bastian},
title = {Synthetic Occlusion Augmentation with Volumetric Heatmaps for the 2018 {ECCV PoseTrack Challenge} on {3D} Human Pose Estimation},
journal={arXiv preprint arXiv:1809.04987},
year = {2018}
}
Deep Person Detection in 2D Range Data
TL;DR: Extend the DROW dataset to persons, extend the method to include short temporal context, and extensively benchmark all available methods.
Detecting humans is a key skill for mobile robots and intelligent vehicles in a large variety of applications. While the problem is well studied for certain sensory modalities such as image data, few works exist that address this detection task using 2D range data. However, a widespread sensory setup for many mobile robots in service and domestic applications contains a horizontally mounted 2D laser scanner. Detecting people from 2D range data is challenging due to the speed and dynamics of human leg motion and the high levels of occlusion and self-occlusion particularly in crowds of people. While previous approaches mostly relied on handcrafted features, we recently developed the deep learning based wheelchair and walker detector DROW. In this paper, we show the generalization to people, including small modifications that significantly boost DROW's performance. Additionally, by providing a small, fully online temporal window in our network, we further boost our score. We extend the DROW dataset with person annotations, making this the largest dataset of person annotations in 2D range data, recorded during several days in a real-world environment with high diversity. Extensive experiments with three current baseline methods indicate it is a challenging dataset, on which our improved DROW detector beats the current state-of-the-art.
@article{Beyer2018RAL,
title = {{Deep Person Detection in 2D Range Data}},
author = {Beyer, Lucas and Hermans, Alexander and Linder, Timm and Arras, Kai Oliver and Leibe, Bastian},
journal = {IEEE Robotics and Automation Letters},
volume = {3},
number = {3},
pages = {2726--2733}
year = {2018}
}
Towards Large-Scale Video Video Object Mining
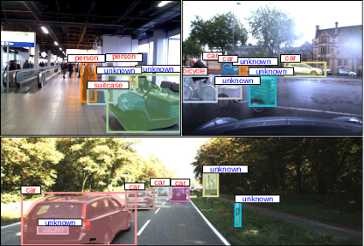
We propose to leverage a generic object tracker in order to perform object mining in large-scale unlabeled videos, captured in a realistic automotive setting. We present a dataset of more than 360'000 automatically mined object tracks from 10+ hours of video data (560'000 frames) and propose a method for automated novel category discovery and detector learning. In addition, we show preliminary results on using the mined tracks for object detector adaptation.
@article{OsepVoigtlaender18ECCVW,
title={Towards Large-Scale Video Object Mining},
author={Aljo\v{s}a O\v{s}ep and Paul Voigtlaender and Jonathon Luiten and Stefan Breuers and Bastian Leibe},
journal={ECCV 2018 Workshop on Interactive and Adaptive Learning in an Open World},
year={2018}
}
Direct Shot Correspondence Matching
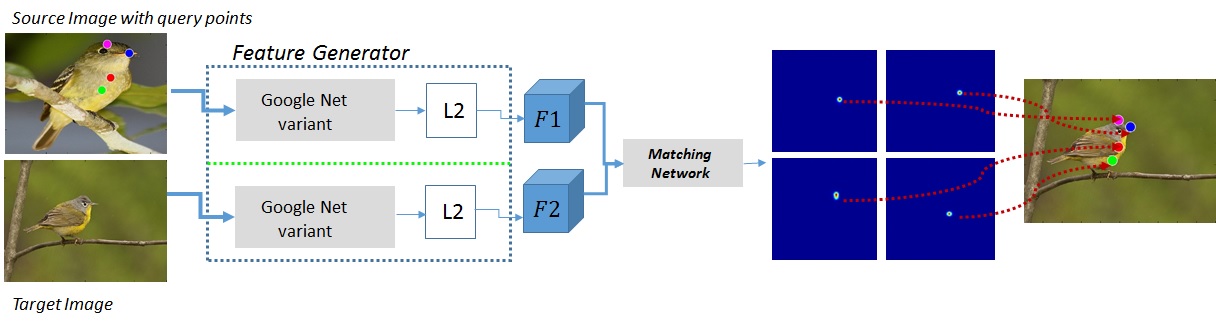
We propose a direct shot method for the task of correspondence matching. Instead of minimizing a loss based on positive and negative pairs, which requires hard-negative mining step for training and nearest neighbor search step for inference, we propose a novel similarity heatmap generator that makes these additional steps obsolete. The similarity heatmap generator efficiently generates peaked similarity heatmaps over the target image for all the query keypoints in a single pass. The matching network can be appended to any standard deep network architecture to make it end-to-end trainable with N-pairs based metric learning and achieves superior performance. We evaluate the proposed method on various correspondence matching datasets and achieve state-of-the-art performance.
Iteratively Trained Interactive Segmentation
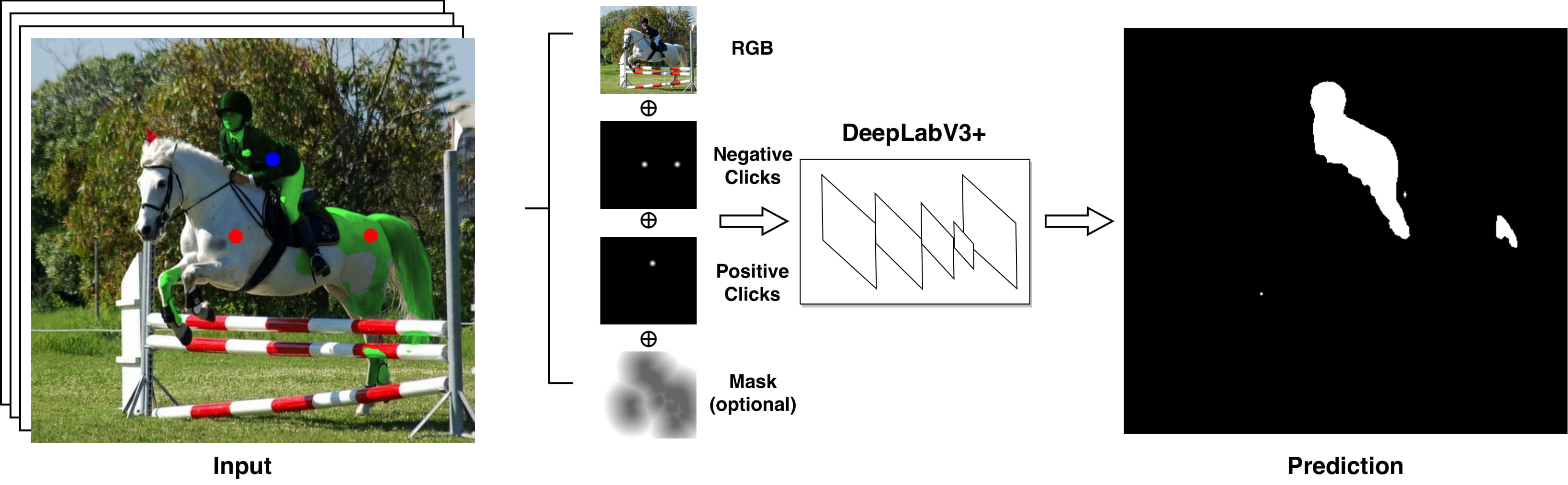
Deep learning requires large amounts of training data to be effective. For the task of object segmentation, manually labeling data is very expensive, and hence interactive methods are needed. Following recent approaches, we develop an interactive object segmentation system which uses user input in the form of clicks as the input to a convolutional network. While previous methods use heuristic click sampling strategies to emulate user clicks during training, we propose a new iterative training strategy. During training, we iteratively add clicks based on the errors of the currently predicted segmentation. We show that our iterative training strategy together with additional improvements to the network architecture results in improved results over the state-of-the-art.
Detection-Tracking for Efficient Person Analysis: The DetTA Pipeline

TL;DR: Detection+Tracking+{head orientation,skeleton} analysis. Smooth per-track enables filtering outliers as well as a "free flight" mode where expensive analysis modules are run with a stride, dramatically increasing runtime performance at almost no loss of prediction quality.
In the past decade many robots were deployed in the wild, and people detection and tracking is an important component of such deployments. On top of that, one often needs to run modules which analyze persons and extract higher level attributes such as age and gender, or dynamic information like gaze and pose. The latter ones are especially necessary for building a reactive, social robot-person interaction.
In this paper, we combine those components in a fully modular detection-tracking-analysis pipeline, called DetTA. We investigate the benefits of such an integration on the example of head and skeleton pose, by using the consistent track ID for a temporal filtering of the analysis modules’ observations, showing a slight improvement in a challenging real-world scenario. We also study the potential of a so-called “free-flight” mode, where the analysis of a person attribute only relies on the filter’s predictions for certain frames. Here, our study shows that this boosts the runtime dramatically, while the prediction quality remains stable. This insight is especially important for reducing power consumption and sharing precious (GPU-)memory when running many analysis components on a mobile platform, especially so in the era of expensive deep learning methods.
@article{BreuersBeyer2018Arxiv,
title = {{Detection-Tracking for Efficient Person Analysis: The DetTA Pipeline}},
author = {Breuers*, Stefan and Beyer*, Lucas and Rafi, Umer and Leibe, Bastian},
journal = {arXiv preprint arXiv:TBD},
year = {2018}
}
Large-Scale Object Discovery and Detector Adaptation from Unlabeled Video
We explore object discovery and detector adaptation based on unlabeled video sequences captured from a mobile platform. We propose a fully automatic approach for object mining from video which builds upon a generic object tracking approach. By applying this method to three large video datasets from autonomous driving and mobile robotics scenarios, we demonstrate its robustness and generality. Based on the object mining results, we propose a novel approach for unsupervised object discovery by appearance-based clustering. We show that this approach successfully discovers interesting objects relevant to driving scenarios. In addition, we perform self-supervised detector adaptation in order to improve detection performance on the KITTI dataset for existing categories. Our approach has direct relevance for enabling large-scale object learning for autonomous driving.
@article{OsepVoigtlaender18arxiv,
title={Large-Scale Object Discovery and Detector Adaptation from Unlabeled Video},
author={Aljo\v{s}a O\v{s}ep and Paul Voigtlaender and Jonathon Luiten and Stefan Breuers and Bastian Leibe},
journal={arXiv preprint arXiv:1712.08832},
year={2018}
}
Exploring Spatial Context for 3D Semantic Segmentation of Point Clouds
Deep learning approaches have made tremendous progress in the field of semantic segmentation over the past few years. However, most current approaches operate in the 2D image space. Direct semantic segmentation of unstructured 3D point clouds is still an open research problem. The recently proposed PointNet architecture presents an interesting step ahead in that it can operate on unstructured point clouds, achieving decent segmentation results. However, it subdivides the input points into a grid of blocks and processes each such block individually. In this paper, we investigate the question how such an architecture can be extended to incorporate larger-scale spatial context. We build upon PointNet and propose two extensions that enlarge the receptive field over the 3D scene. We evaluate the proposed strategies on challenging indoor and outdoor datasets and show improved results in both scenarios.
» Show BibTeX
@inproceedings{3dsemseg_ICCVW17,
author = {Francis Engelmann and
Theodora Kontogianni and
Alexander Hermans and
Bastian Leibe},
title = {Exploring Spatial Context for 3D Semantic Segmentation of Point Clouds},
booktitle = {{IEEE} International Conference on Computer Vision, 3DRMS Workshop, {ICCV}},
year = {2017}
}
Online Adaptation of Convolutional Neural Networks for Video Object Segmentation

We tackle the task of semi-supervised video object segmentation, i.e. segmenting the pixels belonging to an object in the video using the ground truth pixel mask for the first frame. We build on the recently introduced one-shot video object segmentation (OSVOS) approach which uses a pretrained network and fine-tunes it on the first frame. While achieving impressive performance, at test time OSVOS uses the fine-tuned network in unchanged form and is not able to adapt to large changes in object appearance. To overcome this limitation, we propose Online Adaptive Video Object Segmentation (OnAVOS) which updates the network online using training examples selected based on the confidence of the network and the spatial configuration. Additionally, we add a pretraining step based on objectness, which is learned on PASCAL. Our experiments show that both extensions are highly effective and improve the state of the art on DAVIS to an intersection-over-union score of 85.7%.
@inproceedings{voigtlaender17BMVC,
author = {Paul Voigtlaender and Bastian Leibe},
title = {Online Adaptation of Convolutional Neural Networks for Video Object Segmentation},
booktitle = {BMVC},
year = {2017}
}
Full-Resolution Residual Networks for Semantic Segmentation in Street Scenes
Semantic image segmentation is an essential component of modern autonomous driving systems, as an accurate understanding of the surrounding scene is crucial to navigation and action planning. Current state-of-the-art approaches in semantic image segmentation rely on pre-trained networks that were initially developed for classifying images as a whole. While these networks exhibit outstanding recognition performance (i.e., what is visible?), they lack localization accuracy (i.e., where precisely is something located?). Therefore, additional processing steps have to be performed in order to obtain pixel-accurate segmentation masks at the full image resolution. To alleviate this problem we propose a novel ResNet-like architecture that exhibits strong localization and recognition performance. We combine multi-scale context with pixel-level accuracy by using two processing streams within our network: One stream carries information at the full image resolution, enabling precise adherence to segment boundaries. The other stream undergoes a sequence of pooling operations to obtain robust features for recognition. The two streams are coupled at the full image resolution using residuals. Without additional processing steps and without pre-training, our approach achieves an intersection-over-union score of 71.8% on the Cityscapes dataset.
» Show BibTeX
@inproceedings{Pohlen2017CVPR,
title = {{Full-Resolution Residual Networks for Semantic Segmentation in Street Scenes}},
author = {Pohlen, Tobias and Hermans, Alexander and Mathias, Markus and Leibe, Bastian},
booktitle = {{IEEE Conference on Computer Vision and Pattern Recognition (CVPR'17)}},
year = {2017}
}
Semi-Supervised Deep Learning for Monocular Depth Map Prediction
Supervised deep learning often suffers from the lack of sufficient training data. Specifically in the context of monocular depth map prediction, it is barely possible to determine dense ground truth depth images in realistic dynamic outdoor environments. When using LiDAR sensors, for instance, noise is present in the distance measurements, the calibration between sensors cannot be perfect, and the measurements are typically much sparser than the camera images. In this paper, we propose a novel approach to depth map prediction from monocular images that learns in a semi-supervised way. While we use sparse ground-truth depth for supervised learning, we also enforce our deep network to produce photoconsistent dense depth maps in a stereo setup using a direct image alignment loss. In experiments we demonstrate superior performance in depth map prediction from single images compared to the state-of-the-art methods.
» Show BibTeX
@inproceedings{kuznietsov2017_semsupdepth,
title = {Semi-Supervised Deep Learning for Monocular Depth Map Prediction},
author = {Kuznietsov, Yevhen and St\"uckler, J\"org and Leibe, Bastian},
booktitle = {IEEE International Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2017}
}
Combined Image- and World-Space Tracking in Traffic Scenes

Tracking in urban street scenes plays a central role in autonomous systems such as self-driving cars. Most of the current vision-based tracking methods perform tracking in the image domain. Other approaches, e.g. based on LIDAR and radar, track purely in 3D. While some vision-based tracking methods invoke 3D information in parts of their pipeline, and some 3D-based methods utilize image-based information in components of their approach, we propose to use image- and world-space information jointly throughout our method. We present our tracking pipeline as a 3D extension of image-based tracking. From enhancing the detections with 3D measurements to the reported positions of every tracked object, we use world- space 3D information at every stage of processing. We accomplish this by our novel coupled 2D-3D Kalman filter, combined with a conceptually clean and extendable hypothesize-and-select framework. Our approach matches the current state-of-the-art on the official KITTI benchmark, which performs evaluation in the 2D image domain only. Further experiments show significant improvements in 3D localization precision by enabling our coupled 2D-3D tracking.
@inproceedings{Osep17ICRA,
title={Combined Image- and World-Space Tracking in Traffic Scenes},
author={O\v{s}ep, Aljo\v{s}a and Mehner, Wolfgang and Mathias, Markus and Leibe, Bastian},
booktitle={ICRA},
year={2017}
}
Keyframe-Based Visual-Inertial Online SLAM with Relocalization
Complementing images with inertial measurements has become one of the most popular approaches to achieve highly accurate and robust real-time camera pose tracking. In this paper, we present a keyframe-based approach to visual-inertial simultaneous localization and mapping (SLAM) for monocular and stereo cameras. Our method is based on a real-time capable visual-inertial odometry method that provides locally consistent trajectory and map estimates. We achieve global consistency in the estimate through online loop-closing and non-linear optimization. Furthermore, our approach supports relocalization in a map that has been previously obtained and allows for continued SLAM operation. We evaluate our approach in terms of accuracy, relocalization capability and run-time efficiency on public benchmark datasets and on newly recorded sequences. We demonstrate state-of-the-art performance of our approach towards a visual-inertial odometry method in recovering the trajectory of the camera.
@article{Kasyanov2017_VISLAM,
title={{Keyframe-Based Visual-Inertial Online SLAM with Relocalization}},
author={Anton Kasyanov and Francis Engelmann and J\"org St\"uckler and Bastian Leibe},
booktitle={{IEEE/RSJ} International Conference on Intelligent Robots and Systems {(IROS)}},
year={2017}
}
SAMP: Shape and Motion Priors for 4D Vehicle Reconstruction

Inferring the pose and shape of vehicles in 3D from a movable platform still remains a challenging task due to the projective sensing principle of cameras, difficult surface properties, e.g. reflections or transparency, and illumination changes between images. In this paper, we propose to use 3D shape and motion priors to regularize the estimation of the trajectory and the shape of vehicles in sequences of stereo images. We represent shapes by 3D signed distance functions and embed them in a low-dimensional manifold. Our optimization method allows for imposing a common shape across all image observations along an object track. We employ a motion model to regularize the trajectory to plausible object motions. We evaluate our method on the KITTI dataset and show state-of-the-art results in terms of shape reconstruction and pose estimation accuracy.
@inproceedings{EngelmannWACV17_samp,
author = {Francis Engelmann and J{\"{o}}rg St{\"{u}}ckler and Bastian Leibe},
title = {{SAMP:} Shape and Motion Priors for 4D Vehicle Reconstruction},
booktitle = {{IEEE} Winter Conference on Applications of Computer Vision,
{WACV}},
year = {2017}
}
DROW: Real-Time Deep Learning based Wheelchair Detection in 2D Range Data
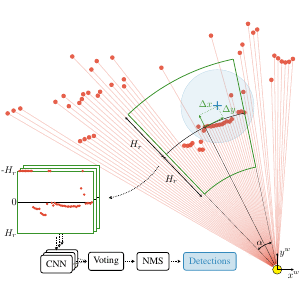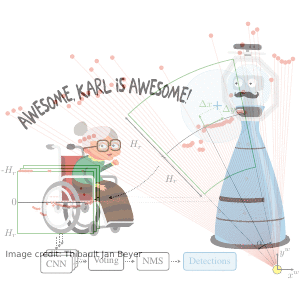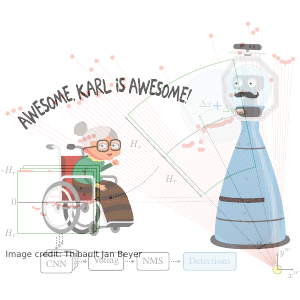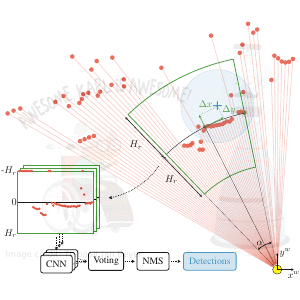
TL;DR: Collected & annotated laser detection dataset. Use window around each point to cast vote on detection center.
We introduce the DROW detector, a deep learning based detector for 2D range data. Laser scanners are lighting invariant, provide accurate range data, and typically cover a large field of view, making them interesting sensors for robotics applications. So far, research on detection in laser range data has been dominated by hand-crafted features and boosted classifiers, potentially losing performance due to suboptimal design choices. We propose a Convolutional Neural Network (CNN) based detector for this task. We show how to effectively apply CNNs for detection in 2D range data, and propose a depth preprocessing step and voting scheme that significantly improve CNN performance. We demonstrate our approach on wheelchairs and walkers, obtaining state of the art detection results. Apart from the training data, none of our design choices limits the detector to these two classes, though. We provide a ROS node for our detector and release our dataset containing 464k laser scans, out of which 24k were annotated.
» Show BibTeX
@article{BeyerHermans2016RAL,
title = {{DROW: Real-Time Deep Learning based Wheelchair Detection in 2D Range Data}},
author = {Beyer*, Lucas and Hermans*, Alexander and Leibe, Bastian},
journal = {{IEEE Robotics and Automation Letters (RA-L)}},
year = {2016}
}
Online Adaptation of Convolutional Neural Networks for the 2017 DAVIS Challenge on Video Object Segmentation
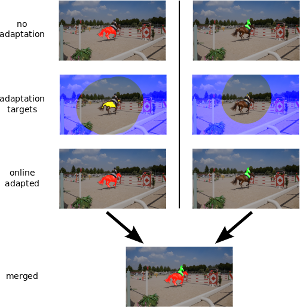
This paper describes our method used for the 2017 DAVIS Challenge on Video Object Segmentation [26]. The challenge’s task is to segment the pixels belonging to multiple objects in a video using the ground truth pixel masks, which are given for the first frame. We build on our recently proposed Online Adaptive Video Object Segmentation (OnAVOS) method which pretrains a convolutional neural network for objectness, fine-tunes it on the first frame, and further updates the network online while processing the video. OnAVOS selects confidently predicted foreground pixels as positive training examples and pixels, which are far away from the last assumed object position as negative examples. While OnAVOS was designed to work with a single object, we extend it to handle multiple objects by combining the predictions of multiple single-object runs. We introduce further extensions including upsampling layers which increase the output resolution. We achieved the fifth place out of 22 submissions to the competition.
@article{voigtlaender17DAVIS,
author = {Paul Voigtlaender and Bastian Leibe},
title = {Online Adaptation of Convolutional Neural Networks for the 2017 DAVIS Challenge on Video Object Segmentation},
journal = {The 2017 DAVIS Challenge on Video Object Segmentation - CVPR Workshops},
year = {2017}
}
3D Semantic Segmentation of Modular Furniture using rjMCMC
In this paper we propose a novel approach to identify and label the structural elements of furniture e.g. wardrobes, cabinets etc. Given a furniture item, the subdivision into its structural components like doors, drawers and shelves is difficult as the number of components and their spatial arrangements varies severely. Furthermore, structural elements are primarily distinguished by their function rather than by unique color or texture based appearance features. It is therefore difficult to classify them, even if their correct spatial extent were known. In our approach we jointly estimate the number of functional units, their spatial structure, and their corresponding labels by using reversible jump MCMC (rjMCMC), a method well suited for optimization on spaces of varying dimensions (the number of structural elements). Optionally, our system permits to invoke depth information e.g. from RGB-D cameras, which are already frequently mounted on mobile robot platforms. We show a considerable improvement over a baseline method even without using depth data, and an additional performance gain when depth input is enabled.
@inproceedings{badamiWACV17,
title={3D Semantic Segmentation of Modular Furniture using rjMCMC
},
author={Badami, Ishrat and Tom, Manu and Mathias, Markus and Leibe, Bastian},
booktitle={WACV},
year={2017}
}
Towards a Principled Integration of Multi-Camera Re-Identification and Tracking through Optimal Bayes Filters
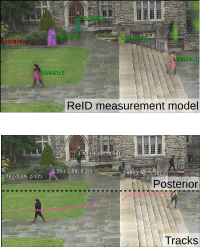
TL;DR: Explorative paper. Learn a Triplet-ReID net, embed the full image. Keep embeddings of known tracks, correlate them with image embeddings and use that as measurement model in a Bayesian filtering tracker. MOT score is mediocre, but framework is theoretically pleasing.
With the rise of end-to-end learning through deep learning, person detectors and re-identification (ReID) models have recently become very strong. Multi-camera multi-target (MCMT) tracking has not fully gone through this transformation yet. We intend to take another step in this direction by presenting a theoretically principled way of integrating ReID with tracking formulated as an optimal Bayes filter. This conveniently side-steps the need for data-association and opens up a direct path from full images to the core of the tracker. While the results are still sub-par, we believe that this new, tight integration opens many interesting research opportunities and leads the way towards full end-to-end tracking from raw pixels.
@article{BeyerBreuers2017Arxiv,
author = {Lucas Beyer and
Stefan Breuers and
Vitaly Kurin and
Bastian Leibe},
title = {{Towards a Principled Integration of Multi-Camera Re-Identification
and Tracking through Optimal Bayes Filters}},
journal = {{2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)}},
year = {2017},
pages ={1444-1453},
}
In Defense of the Triplet Loss for Person Re-Identification

TL;DR: Use triplet loss, hard-mining inside mini-batch performs great, is similar to offline semi-hard mining but much more efficient.
In the past few years, the field of computer vision has gone through a revolution fueled mainly by the advent of large datasets and the adoption of deep convolutional neural networks for end-to-end learning. The person re-identification subfield is no exception to this, thanks to the notable publication of the Market-1501 and MARS datasets and several strong deep learning approaches. Unfortunately, a prevailing belief in the community seems to be that the triplet loss is inferior to using surrogate losses (classification, verification) followed by a separate metric learning step. We show that, for models trained from scratch as well as pretrained ones, using a variant of the triplet loss to perform end-to-end deep metric learning outperforms any other published method by a large margin.
@article{HermansBeyer2017Arxiv,
title = {{In Defense of the Triplet Loss for Person Re-Identification}},
author = {Hermans*, Alexander and Beyer*, Lucas and Leibe, Bastian},
journal = {arXiv preprint arXiv:1703.07737},
year = {2017}
}
Incremental Object Discovery in Time-Varying Image Collections
In this paper, we address the problem of object discovery in time-varying, large-scale image collections. A core part of our approach is a novel Limited Horizon Minimum Spanning Tree (LH-MST) structure that closely approximates the Minimum Spanning Tree at a small fraction of the latter’s computational cost. Our proposed tree structure can be created in a local neighborhood of the matching graph during image retrieval and can be efficiently updated whenever the image database is extended. We show how the LH-MST can be used within both single-link hierarchical agglomerative clustering and the Iconoid Shift framework for object discovery in image collections, resulting in significant efficiency gains and making both approaches capable of incremental clustering with online updates. We evaluate our approach on a dataset of 500k images from the city of Paris and compare its results to the batch version of both clustering algorithms.
PatchIt: Self-supervised Network Weight Initialization for Fine-grained Recognition
ConvNet training is highly sensitive to initialization of the weights. A widespread approach is to initialize the network with weights trained for a different task, an auxiliary task. The ImageNet-based ILSVRC classification task is a very popular choice for this, as it has shown to produce powerful feature representations applicable to a wide variety of tasks. However, this creates a significant entry barrier to exploring non-standard architectures. In this paper, we propose a self-supervised pretraining, the PatchTask, to obtain weight initializations for fine-grained recognition problems, such as person attribute recognition, pose estimation, or action recognition. Our pretraining allows us to leverage additional unlabeled data from the same source, which is often readily available, such as detection bounding boxes. We experimentally show that our method outperforms a standard random initialization by a considerable margin and closely matches the ImageNet-based initialization.
@InProceedings{Sudowe16BMVC,
author = {Patrick Sudowe and Bastian Leibe},
title = {{PatchIt: Self-Supervised Network Weight Initialization for Fine-grained Recognition}},
booktitle = BMVC,
year = {2016}
}
Unsupervised Learning of Shape-Motion Patterns for Objects in Urban Street Scenes
Tracking in urban street scenes is predominantly based on pretrained object-specific detectors and Kalman filter based tracking. More recently, methods have been proposed that track objects by modelling their shape, as well as ones that predict the motion of ob- jects using learned trajectory models. In this paper, we combine these ideas and propose shape-motion patterns (SMPs) that incorporate shape as well as motion to model a vari- ety of objects in an unsupervised way. By using shape, our method can learn trajectory models that distinguish object categories with distinct behaviour. We develop methods to classify objects into SMPs and to predict future motion. In experiments, we analyze our learned categorization and demonstrate superior performance of our motion predictions compared to a Kalman filter and a learned pure trajectory model. We also demonstrate how SMPs can indicate potentially harmful situations in traffic scenarios.
» Show BibTeX
@inproceedings{klostermann2016_smps,
title = {Unsupervised Learning of Shape-Motion Patterns for Objects in Urban Street Scenes},
author = {Dirk Klostermann and Aljosa Osep and J\"org St\"uckler and Bastian Leibe},
booktitle = {Proc. of the British Machine Vision Conference (BMVC)},
year = {2016}, note = {to appear}
}
Scene Flow Propagation for Semantic Mapping and Object Discovery in Dynamic Street Scenes

Scene understanding is an important prerequisite for vehicles and robots that operate autonomously in dynamic urban street scenes. For navigation and high-level behavior planning, the robots not only require a persistent 3D model of the static surroundings - equally important, they need to perceive and keep track of dynamic objects. In this paper, we propose a method that incrementally fuses stereo frame observations into temporally consistent semantic 3D maps. In contrast to previous work, our approach uses scene flow to propagate dynamic objects within the map. Our method provides a persistent 3D occupancy as well as semantic belief on static as well as moving objects. This allows for advanced reasoning on objects despite noisy single-frame observations and occlusions. We develop a novel approach to discover object instances based on the temporally consistent shape, appearance, motion, and semantic cues in our maps. We evaluate our approaches to dynamic semantic mapping and object discovery on the popular KITTI benchmark and demonstrate improved results compared to single-frame methods.
» Show BibTeX
@inproceedings{kochanov2016_sceneflowprop,
title = {Scene Flow Propagation for Semantic Mapping and Object Discovery in Dynamic Street Scenes},
author = {Deyvid Kochanov and Aljosa Osep and J\"org St\"uckler and Bastian Leibe},
booktitle = {Proc. of the IEEE Int. Conf. on Intelligent Robots and Systems (IROS)}, year = {2016},
note = {to appear}
}
Joint Object Pose Estimation and Shape Reconstruction in Urban Street Scenes Using 3D Shape Priors

Estimating the pose and 3D shape of a large variety of instances within an object class from stereo images is a challenging problem, especially in realistic conditions such as urban street scenes. We propose a novel approach for using compact shape manifolds of the shape within an object class for object segmentation, pose and shape estimation. Our method first detects objects and estimates their pose coarsely in the stereo images using a state-of-the-art 3D object detection method. An energy minimization method then aligns shape and pose concurrently with the stereo reconstruction of the object. In experiments, we evaluate our approach for detection, pose and shape estimation of cars in real stereo images of urban street scenes. We demonstrate that our shape manifold alignment method yields improved results over the initial stereo reconstruction and object detection method in depth and pose accuracy.
» Show BibTeX
@inproceedings{EngelmannGCPR16_shapepriors,
title = {Joint Object Pose Estimation and Shape Reconstruction in Urban Street Scenes Using {3D} Shape Priors},
author = {Francis Engelmann and J\"org St\"uckler and Bastian Leibe},
booktitle = {Proc. of the German Conference on Pattern Recognition (GCPR)},
year = {2016}}
Multi-Scale Object Candidates for Generic Object Tracking in Street Scenes

Most vision based systems for object tracking in urban environments focus on a limited number of important object categories such as cars or pedestrians, for which powerful detectors are available. However, practical driving scenarios contain many additional objects of interest, for which suitable detectors either do not yet exist or would be cumbersome to obtain. In this paper we propose a more general tracking approach which does not follow the often used tracking-by- detection principle. Instead, we investigate how far we can get by tracking unknown, generic objects in challenging street scenes. As such, we do not restrict ourselves to only tracking the most common categories, but are able to handle a large variety of static and moving objects. We evaluate our approach on the KITTI dataset and show competitive results for the annotated classes, even though we are not restricted to them.
@inproceedings{Osep16ICRA,
title={Multi-Scale Object Candidates for Generic Object Tracking in Street
Scenes},
author={O\v{s}ep, Aljo\v{s}a and Hermans, Alexander and Engelmann, Francis and Klostermann, Dirk and and Mathias, Markus and Leibe, Bastian},
booktitle={ICRA},
year={2016}
}
The STRANDS Project: Long-Term Autonomy in Everyday Environments

Thanks to the efforts of our community, autonomous robots are becoming capable of ever more complex and impressive feats. There is also an increasing demand for, perhaps even an expectation of, autonomous capabilities from end-users. However, much research into autonomous robots rarely makes it past the stage of a demonstration or experimental system in a controlled environment. If we don't confront the challenges presented by the complexity and dynamics of real end-user environments, we run the risk of our research becoming irrelevant or ignored by the industries who will ultimately drive its uptake. In the STRANDS project we are tackling this challenge head-on. We are creating novel autonomous systems, integrating state-of-the-art research in artificial intelligence and robotics into robust mobile service robots, and deploying these systems for long-term installations in security and care environments. To date, over four deployments, our robots have been operational for a combined duration of 2545 hours (or a little over 106 days), covering 116km while autonomously performing end-user defined tasks. In this article we present an overview of the motivation and approach of the STRANDS project, describe the technology we use to enable long, robust autonomous runs in challenging environments, and describe how our robots are able to use these long runs to improve their own performance through various forms of learning.
Semantic Segmentation of Modular Furniture

This paper proposes an approach for the semantic seg- mentation and structural parsing of modular furniture items, such as cabinets, wardrobes, and bookshelves, into so called interaction elements. Such a segmentation into functional units is challenging not only due to the visual similarity of the different elements but also because of their often uniformly colored and low-texture appearance. Our method addresses these challenges by merging structural and appearance likelihoods of each element and jointly op- timizing over shape, relative location, and class labels us- ing Markov Chain Monte Carlo (MCMC) sampling. We propose a novel concept called rectangle coverings which provides a tight bound on the number of structural elements and hence narrows down the search space. We evaluate our approach’s performance on a novel dataset of furniture items and demonstrate its applicability in practice.
@inproceedings{badamiWACV17,
title={Semantic Segmentation of Modular Furniture},
author={Pohlen, Tobias and Badami, Ishrat and Mathias, Markus and Leibe, Bastian},
booktitle={WACV},
year={2016}
}
Superpixels: An Evaluation of the State-of-the-Art
Superpixels group perceptually similar pixels to create visually meaningful entities while heavily reducing the number of primitives. As of these properties, superpixel algorithms have received much attention since their naming in 2003. By today, publicly available and well-understood superpixel algorithms have turned into standard tools in low-level vision. As such, and due to their quick adoption in a wide range of applications, appropriate benchmarks are crucial for algorithm selection and comparison. Until now, the rapidly growing number of algorithms as well as varying experimental setups hindered the development of a unifying benchmark. We present a comprehensive evaluation of 28 state-of-the-art superpixel algorithms utilizing a benchmark focussing on fair comparison and designed to provide new and relevant insights. To this end, we explicitly discuss parameter optimization and the importance of strictly enforcing connectivity. Furthermore, by extending well-known metrics, we are able to summarize algorithm performance independent of the number of generated superpixels, thereby overcoming a major limitation of available benchmarks. Furthermore, we discuss runtime, robustness against noise, blur and affine transformations, implementation details as well as aspects of visual quality. Finally, we present an overall ranking of superpixel algorithms which redefines the state-of-the-art and enables researchers to easily select appropriate algorithms and the corresponding implementations which themselves are made publicly available as part of our benchmark at davidstutz.de/projects/superpixel-benchmark/.
@article{Stutz2016Arxiv,
title = {{Superpixels: An Evaluation of the State-of-the-Art}},
author = {David Stutz and Alexander Hermans and Bastian Leibe},
journal = {arXiv preprint arXiv:1612.01601},
year = {2016}
}
An Efficient Convolutional Network for Human Pose Estimation
In recent years, human pose estimation has greatly benefited from deep learning and huge gains in performance have been achieved. The trend to maximise the accuracy on benchmarks, however, resulted in computationally expensive deep network architectures that require expensive hardware and pre-training on large datasets. This makes it difficult to compare different methods and to reproduce existing results. We therefore propose in this work an efficient deep network architecture that can be efficiently trained on mid-range GPUs without the need of any pre-training. Despite of the low computational requirements of our network, it is on par with much more complex models on popular benchmarks for human pose estimation.
On Multi-Modal People Tracking from Mobile Platforms in Very Crowded and Dynamic Environments

Tracking people is a key technology for robots and intelligent systems in human environments. Many person detectors, filtering methods and data association algorithms for people tracking have been proposed in the past 15+ years in both the robotics and computer vision communities, achieving decent tracking performances from static and mobile platforms in real-world scenarios. However, little effort has been made to compare these methods, analyze their performance using different sensory modalities and study their impact on different performance metrics. In this paper, we propose a fully integrated real-time multi-modal laser/RGB-D people tracking framework for moving platforms in environments like a busy airport terminal. We conduct experiments on two challenging new datasets collected from a first-person perspective, one of them containing very dense crowds of people with up to 30 individuals within close range at the same time. We consider four different, recently proposed tracking methods and study their impact on seven different performance metrics, in both single and multi-modal settings. We extensively discuss our findings, which indicate that more complex data association methods may not always be the better choice, and derive possible future research directions.
» Show BibTeX
@incollection{linder16multi,
title={On Multi-Modal People Tracking from Mobile Platforms in Very Crowded and Dynamic Environments},
author={Linder, Timm and Breuers, Stefan and Leibe, Bastian and Arras, Kai Oliver},
booktitle={ICRA},
year={2016},
}
Exploring Bounding Box Context for Multi-Object Tracker Fusion
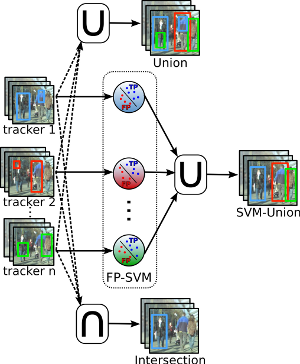
Many multi-object-tracking (MOT) techniques have been developed over the past years. The most successful ones are based on the classical tracking-by-detection approach. The different methods rely on different kinds of data association, use motion and appearance models, or add optimization terms for occlusion and exclusion. Still, errors occur for all those methods and a consistent evaluation has just started. In this paper we analyze three current state-of-the-art MOT trackers and show that there is still room for improvement. To that end, we train a classifier on the trackers' output bounding boxes in order to prune false positives. Furthermore, the different approaches have different strengths resulting in a reduced false negative rate when combined. We perform an extensive evaluation over ten common evaluation sequences and consistently show improved performances by exploiting the strengths and reducing the weaknesses of current methods.
@inproceedings{breuersWACV16,
title={Exploring Bounding Box Context for Multi-Object Tracker Fusion},
author={Breuers, Stefan and Yang, Shishan and Mathias, Markus and Leibe, Bastian},
booktitle={WACV},
year={2016}
}
Visual landmark recognition from Internet photo collections: A large-scale evaluation
In this paper, we present an object-centric, fixeddimensional 3D shape representation for robust matching of partially observed object shapes, which is an important component for object categorization from 3D data. A main problem when working with RGB-D data from stereo, Kinect, or laser sensors is that the 3D information is typically quite noisy. For that reason, we accumulate shape information over time and register it in a common reference frame. Matching the resulting shapes requires a strategy for dealing with partial observations. We therefore investigate several distance functions and kernels that implement different such strategies and compare their matching performance in quantitative experiments. We show that the resulting representation achieves good results for a large variety of vision tasks, such as multi-class classification, person orientation estimation, and articulated body pose estimation, where robust 3D shape matching is essential.
Biternion Nets: Continuous Head Pose Regression from Discrete Training Labels

TL;DR: By doing the obvious thing of encoding an angle φ as (cos φ, sin φ), we can do cool things and simplify data labeling requirements.
While head pose estimation has been studied for some time, continuous head pose estimation is still an open problem. Most approaches either cannot deal with the periodicity of angular data or require very fine-grained regression labels. We introduce biternion nets, a CNN-based approach that can be trained on very coarse regression labels and still estimate fully continuous 360° head poses. We show state-of-the-art results on several publicly available datasets. Finally, we demonstrate how easy it is to record and annotate a new dataset with coarse orientation labels in order to obtain continuous head pose estimates using our biternion nets.
» Show BibTeX
@inproceedings{Beyer2015BiternionNets,
author = {Lucas Beyer and Alexander Hermans and Bastian Leibe},
title = {Biternion Nets: Continuous Head Pose Regression from Discrete Training Labels},
booktitle = {Pattern Recognition},
publisher = {Springer},
series = {Lecture Notes in Computer Science},
volume = {9358},
pages = {157-168},
year = {2015},
isbn = {978-3-319-24946-9},
doi = {10.1007/978-3-319-24947-6_13},
ee = {http://lucasb.eyer.be/academic/biternions/biternions_gcpr15.pdf},
}
A Fixed-Dimensional 3D Shape Representation for Matching Partially Observed Objects in Street Scenes
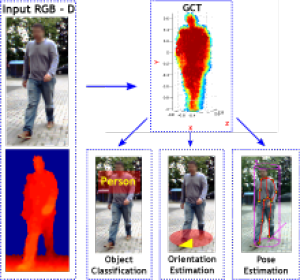
In this paper, we present an object-centric, fixeddimensional 3D shape representation for robust matching of partially observed object shapes, which is an important component for object categorization from 3D data. A main problem when working with RGB-D data from stereo, Kinect, or laser sensors is that the 3D information is typically quite noisy. For that reason, we accumulate shape information over time and register it in a common reference frame. Matching the resulting shapes requires a strategy for dealing with partial observations. We therefore investigate several distance functions and kernels that implement different such strategies and compare their matching performance in quantitative experiments. We show that the resulting representation achieves good results for a large variety of vision tasks, such as multi-class classification, person orientation estimation, and articulated body pose estimation, where robust 3D shape matching is essential.
Multi-band Hough Forests for Detecting Humans with Reflective Safety Clothing from Mobile Machinery
We address the problem of human detection from heavy mobile machinery and robotic equipment operating at industrial working sites. Exploiting the fact that workers are typically obliged to wear high-visibility clothing with reflective markers, we propose a new recognition algorithm that specifically incorporates the highly discriminative features of the safety garments in the detection process. Termed Multi-band Hough Forest, our detector fuses the input from active near-infrared (NIR) and RGB color vision to learn a human appearance model that not only allows us to detect and localize industrial workers, but also to estimate their body orientation. We further propose an efficient pipeline for automated generation of training data with high-quality body part annotations that are used in training to increase detector performance. We report a thorough experimental evaluation on challenging image sequences from a real-world production environment, where persons appear in a variety of upright and non-upright body positions.
Fixing WTFs: Detecting Image Matches caused by Watermarks, Timestamps, and Frames in Internet Photos
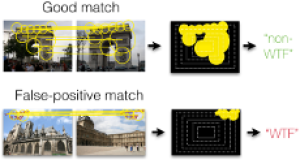
An increasing number of photos in Internet photo collections comes with watermarks, timestamps, or frames (in the following called WTFs) embedded in the image content. In image retrieval, such WTFs often cause false-positive matches. In image clustering, these false-positive matches can cause clusters of different buildings to be joined into one. This harms applications like landmark recognition or large-scale structure-from-motion, which rely on clean building clusters. We propose a simple, but highly effective detector for such false-positive matches. Given a matching image pair with an estimated homography, we first determine similar regions in both images. Exploiting the fact that WTFs typically appear near the border, we build a spatial histogram of the similar regions and apply a binary classifier to decide whether the match is due to a WTF. Based on a large-scale dataset of WTFs we collected from Internet photo collections, we show that our approach is general enough to recognize a large variety of watermarks, timestamps, and frames, and that it is efficient enough for largescale applications. In addition, we show that our method fixes the problems that WTFs cause in image clustering applications. The source code is publicly available and easy to integrate into existing retrieval and clustering systems.
Person Attribute Recognition with a Jointly-trained Holistic CNN Model
This paper addresses the problem of human visual attribute recognition, i.e., the prediction of a fixed set of semantic attributes given an image of a person. Previous work often considered the different attributes independently from each other, without taking advantage of possible dependencies between them. In contrast, we propose a method to jointly train a CNN model for all attributes that can take advantage of those dependencies, considering as input only the image without additional external pose, part or context information. We report detailed experiments examining the contribution of individual aspects, which yields beneficial insights for other researchers. Our holistic CNN achieves superior performance on two publicly available attribute datasets improving on methods that additionally rely on pose-alignment or context. To support further evaluations, we present a novel dataset, based on realistic outdoor video sequences, that contains more than 27,000 pedestrians annotated with 10 attributes. Finally, we explore design options to embrace the N/A labels inherently present in this task.
@InProceedings{PARSE27k,
author = {Patrick Sudowe and Hannah Spitzer and Bastian Leibe},
title = {{Person Attribute Recognition with a Jointly-trained Holistic CNN Model}},
booktitle = {ICCV'15 ChaLearn Looking at People Workshop},
year = {2015},
}
A Semantic Occlusion Model for Human Pose Estimation from a Single Depth image

Human pose estimation from depth data has made significant progress in recent years and commercial sensors estimate human poses in real-time. However, state-of-theart methods fail in many situations when the humans are partially occluded by objects. In this work, we introduce a semantic occlusion model that is incorporated into a regression forest approach for human pose estimation from depth data. The approach exploits the context information of occluding objects like a table to predict the locations of occluded joints. In our experiments on synthetic and real data, we show that our occlusion model increases the joint estimation accuracy and outperforms the commercial Kinect 2 SDK for occluded joints.
Sequence-Level Object Candidates Based on Saliency for Generic Object Recognition on Mobile Systems

In this paper, we propose a novel approach for generating generic object candidates for object discovery and recognition in continuous monocular video. Such candidates have recently become a popular alternative to exhaustive window-based search as basis for classification. Contrary to previous approaches, we address the candidate generation problem at the level of entire video sequences instead of at the single image level. We propose a processing pipeline that starts from individual region candidates and tracks them over time. This enables us to group candidates for similar objects and to automatically filter out inconsistent regions. For generating the per-frame candidates, we introduce a novel multi-scale saliency approach that achieves a higher per-frame recall with fewer candidates than current state-of-the-art methods. Taken together, those two components result in a significant reduction of the number of object candidates compared to frame level methods, while keeping a consistently high recall.
Robust Marker-Based Tracking for Measuring Crowd Dynamics

We present a system to conduct laboratory experiments with thousands of pedestrians. Each participant is equipped with an individual marker to enable us to perform precise tracking and identification. We propose a novel rotation invariant marker design which guarantees a minimal Hamming distance between all used codes. This increases the robustness of pedestrian identification. We present an algorithm to detect these markers, and to track them through a camera network. With our system we are able to capture the movement of the participants in great detail, resulting in precise trajectories for thousands of pedestrians. The acquired data is of great interest in the field of pedestrian dynamics. It can also potentially help to improve multi-target tracking approaches, by allowing better insights into the behaviour of crowds.
SPENCER: A Socially Aware Service Robot for Passenger Guidance and Help in Busy Airports

We present an ample description of a socially compliant mobile robotic platform, which is developed in the EU-funded project SPENCER. The purpose of this robot is to assist, inform and guide passengers in large and busy airports. One particular aim is to bring travellers of connecting flights conveniently and efficiently from their arrival gate to the passport control. The uniqueness of the project stems from the strong demand of service robots for this application with a large potential impact for the aviation industry on one side, and on the other side from the scientific advancements in social robotics, brought forward and achieved in SPENCER. The main contributions of SPENCER are novel methods to perceive, learn, and model human social behavior and to use this knowledge to plan appropriate actions in real- time for mobile platforms. In this paper, we describe how the project advances the fields of detection and tracking of individuals and groups, recognition of human social relations and activities, normative human behavior learning, socially-aware task and motion planning, learning socially annotated maps, and conducting empir- ical experiments to assess socio-psychological effects of normative robot behaviors.
@article{triebel2015spencer,
title={SPENCER: a socially aware service robot for passenger guidance and help in busy airports},
author={Triebel, Rudolph and Arras, Kai and Alami, Rachid and Beyer, Lucas and Breuers, Stefan and Chatila, Raja and Chetouani, Mohamed and Cremers, Daniel and Evers, Vanessa and Fiore, Michelangelo and Hung, Hayley and Islas Ramírez, Omar A. and Joosse, Michiel and Khambhaita, Harmish and Kucner, Tomasz and Leibe, Bastian and Lilienthal, Achim J. and Linder, Timm and Lohse, Manja and Magnusson, Martin and Okal, Billy and Palmieri, Luigi and Rafi, Umer and Rooij, Marieke van and Zhang, Lu},
journal={Field and Service Robotics (FSR)
year={2015},
publisher={University of Toronto}
}
Probabilistic Labeling Cost for High-Accuracy Multi-view Reconstruction

In this paper, we propose a novel labeling cost for multiview reconstruction. Existing approaches use data terms with specific weaknesses that are vulnerable to common challenges, such as low-textured regions or specularities. Our new probabilistic method implicitly discards outliers and can be shown to become more exact the closer we get to the true object surface. Our approach achieves top results among all published methods on the Middlebury DINO SPARSE dataset and also delivers accurate results on several other datasets with widely varying challenges, for which it works in unchanged form.
Real-Time RGB-D based People Detection and Tracking for Mobile Robots and Head-Worn Cameras
We present a real-time RGB-D based multiperson detection and tracking system suitable for mobile robots and head-worn cameras. Our approach combines RGBD visual odometry estimation, region-of-interest processing, ground plane estimation, pedestrian detection, and multihypothesis tracking components into a robust vision system that runs at more than 20fps on a laptop. As object detection is the most expensive component in any such integration, we invest significant effort into taking maximum advantage of the available depth information. In particular, we propose to use two different detectors for different distance ranges. For the close range (up to 5-7m), we present an extremely fast depth-based upper-body detector that allows video-rate system performance on a single CPU core when applied to Kinect sensors. In order to cover also farther distance ranges, we optionally add an appearance-based full-body HOG detector (running on the GPU) that exploits scene geometry to restrict the search space. Our approach can work with both Kinect RGB-D input for indoor settings and with stereo depth input for outdoor scenarios. We quantitatively evaluate our approach on challenging indoor and outdoor sequences and show state-of-the-art performance in a large variety of settings. Our code is publicly available.
Dense 3D Semantic Mapping of Indoor Scenes from RGB-D Images
Dense semantic segmentation of 3D point clouds is a challenging task. Many approaches deal with 2D semantic segmentation and can obtain impressive results. With the availability of cheap RGB-D sensors the field of indoor semantic segmentation has seen a lot of progress. Still it remains unclear how to deal with 3D semantic segmentation in the best way. We propose a novel 2D-3D label transfer based on Bayesian updates and dense pairwise 3D Conditional Random Fields. This approach allows us to use 2D semantic segmentations to create a consistent 3D semantic reconstruction of indoor scenes. To this end, we also propose a fast 2D semantic segmentation approach based on Randomized Decision Forests. Furthermore, we show that it is not needed to obtain a semantic segmentation for every frame in a sequence in order to create accurate semantic 3D reconstructions. We evaluate our approach on both NYU Depth datasets and show that we can obtain a significant speed-up compared to other methods.
@inproceedings{Hermans14ICRA,
author = {Alexander Hermans and Georgios Floros and Bastian Leibe},
title = {{Dense 3D Semantic Mapping of Indoor Scenes from RGB-D Images}},
booktitle = {International Conference on Robotics and Automation},
year = {2014}
}
Multiple Target Tracking for Marker-less Augmented Reality
In this work, we implemented an AR framework for planar targets based on the ORB feature-point descriptor. The main components of the framework are a detector, a tracker and a graphical overlay. The detector returns a homography that maps the model- image onto the target in the camera-image. The homography is estimated from a set of feature-point correspondences using the Direct Linear Transform (DLT) algorithm and Levenberg-Marquardt (LM) optimization. The outliers in the set of feature-point correspondences are removed using RANSAC. The tracker is based on the Kalman filter, which applies a consistent dynamic movement on the target. In a hierarchical matching scheme, we extract additional matches from consecutive frames and perspectively transformed model-images, which yields more accurate and jitter-free homography estimations. The graphical overlay computes the six-degree-of-freedom (6DoF) pose from the estimated homography. Finally, to visualize the computed pose, we draw a cube on the surface of the tracked target. In the evaluation part, we analyze the performance of our system by looking at the accuracy of the estimated homography and the ratio of correctly tracked frames. The evaluation is based on the ground truth provided by two datasets. We evaluate most components of the framework under different target movements and lighting conditions. In particular, we proof that our framework is robust against considerable perspective distortion and show the benefit of using the hierarchical matching scheme to minimize jitter and improve accuracy.
A Flexible ASIP Architecture for Connected Components Labeling in Embedded Vision Applications
Real-time identification of connected regions of pixels in large (e.g. FullHD) frames is a mandatory and expensive step in many computer vision applications that are becoming increasingly popular in embedded mobile devices such as smart-phones, tablets and head mounted devices. Standard off-the-shelf embedded processors are not yet able to cope with the performance/flexibility trade-offs required by such applications. Therefore, in this work we present an Application Specific Instruction Set Processor (ASIP) tailored to concurrently execute thresholding, connected components labeling and basic feature extraction of image frames. The proposed architecture is capable to cope with frame complexities ranging from QCIF to FullHD frames with 1 to 4 bytes-per-pixel formats, while achieving an average frame rate of 30 frames-per-second (fps). Synthesis was performed for a standard 65nm CMOS library, obtaining an operating frequency of 350MHz and 2.1mm2 area. Moreover, evaluations were conducted both on typical and synthetic data sets, in order to thoroughly assess the achievable performance. Finally, an entire planar-marker based augmented reality application was developed and simulated for the ASIP.
Tracking People and Their Objects

Current pedestrian tracking approaches ignore impor- tant aspects of human behavior. Humans are not moving independently, but they closely interact with their environ- ment, which includes not only other persons, but also dif- ferent scene objects. Typical everyday scenarios include people moving in groups, pushing child strollers, or pulling luggage. In this paper, we propose a probabilistic approach for classifying such person-object interactions, associating objects to persons, and predicting how the interaction will most likely continue. Our approach relies on stereo depth information in order to track all scene objects in 3D, while simultaneously building up their 3D shape models. These models and their relative spatial arrangement are then fed into a probabilistic graphical model which jointly infers pairwise interactions and object classes. The inferred inter- actions can then be used to support tracking by recovering lost object tracks. We evaluate our approach on a novel dataset containing more than 15,000 frames of person- object interactions in 325 video sequences and demonstrate good performance in challenging real-world scenarios.
Random Forests of Local Experts for Pedestrian Detection
Pedestrian detection is one of the most challenging tasks in computer vision, and has received a lot of attention in the last years. Recently, some authors have shown the advan- tages of using combinations of part/patch-based detectors in order to cope with the large variability of poses and the existence of partial occlusions. In this paper, we propose a pedestrian detection method that efficiently combines mul- tiple local experts by means of a Random Forest ensemble. The proposed method works with rich block-based repre- sentations such as HOG and LBP, in such a way that the same features are reused by the multiple local experts, so that no extra computational cost is needed with respect to a holistic method. Furthermore, we demonstrate how to inte- grate the proposed approach with a cascaded architecture in order to achieve not only high accuracy but also an ac- ceptable efficiency. In particular, the resulting detector op- erates at five frames per second using a laptop machine. We tested the proposed method with well-known challeng- ing datasets such as Caltech, ETH, Daimler, and INRIA. The method proposed in this work consistently ranks among the top performers in all the datasets, being either the best method or having a small difference with the best one.
Discovering Details and Scene Structure with Hierarchical Iconoid Shift

Current landmark recognition engines are typically aimed at recognizing building-scale landmarks, but miss interesting details like portals, statues or windows. This is because they use a flat clustering that summarizes all photos of a building facade in one cluster. We propose Hierarchical Iconoid Shift, a novel landmark clustering algorithm capable of discovering such details. Instead of just a collection of clusters, the output of HIS is a set of dendrograms describing the detail hierarchy of a landmark. HIS is based on the novel Hierarchical Medoid Shift clustering algorithm that performs a continuous mode search over the complete scale space. HMS is completely parameter-free, has the same complexity as Medoid Shift and is easy to parallelize. We evaluate HIS on 800k images of 34 landmarks and show that it can extract an often surprising amount of detail and structure that can be applied, e.g., to provide a mobile user with more detailed information on a landmark or even to extend the landmark’s Wikipedia article.
OpenStreetSLAM: Global Vehicle Localization Using OpenStreetMaps

In this paper we propose an approach for global vehicle localization that combines visual odometry with map information from OpenStreetMaps to provide robust and accurate estimates for the vehicle’s position. The main contribution of this work comes from the incorporation of the map data as an additional cue into the observation model of a Monte Carlo Localization framework. The resulting approach is able to compensate for the drift that visual odometry accumulates over time, significantly improving localization quality. As our results indicate, the proposed approach outperforms current state-ofthe- art visual odometry approaches, indicating in parallel the potential that map data can bring to the global localization task.
SIFT-Realistic Rendering

3D localization approaches establish correspondences between points in a query image and a 3D point cloud reconstruction of the environment. Traditionally, the database models are created from photographs using Structure-from-Motion (SfM) techniques, which requires large collections of densely sampled images. In this paper, we address the question how point cloud data from terrestrial laser scanners can be used instead to significantly reduce the data collection effort and enable more scalable localization.
The key change here is that, in contrast to SfM points, laser-scanned 3D points are not automatically associated with local image features that could be matched to query image features. In order to make this data usable for image-based localization, we explore how point cloud rendering techniques can be leveraged to create virtual views from which database features can be extracted that match real image-based features as closely as possible. We propose different rendering techniques for this task, experimentally quantify how they affect feature repeatability, and demonstrate their benefit for image-based localization.
Computer Vision Systems

This book constitutes the refereed proceedings of the 9th International Conference on Computer Vision Systems, ICVS 2013, held in St. Petersburg, Russia, July 16-18, 2013. Proceedings. The 16 revised papers presented with 20 poster papers were carefully reviewed and selected from 94 submissions. The papers are organized in topical sections on image and video capture; visual attention and object detection; self-localization and pose estimation; motion and tracking; 3D reconstruction; features, learning and validation.
Taking Mobile Multi-Object Tracking to the Next Level: People, Unknown Objects, and Carried Items

In this paper, we aim to take mobile multi-object tracking to the next level. Current approaches work in a tracking-by-detection framework, which limits them to object categories for which pre-trained detector models are available. In contrast, we propose a novel tracking-before-detection approach that can track both known and unknown object categories in very challenging street scenes. Our approach relies on noisy stereo depth data in order to segment and track objects in 3D. At its core is a novel, compact 3D representation that allows us to robustly track a large variety of objects, while building up models of their 3D shape online. In addition to improving tracking performance, this represensation allows us to detect anomalous shapes, such as carried items on a person’s body. We evaluate our approach on several challenging video sequences of busy pedestrian zones and show that it outperforms state-of-the-art approaches.
Joint 2D-3D Temporally Consistent Semantic Segmentation of Street Scenes

In this paper we propose a novel Conditional Random Field (CRF) formulation for the semantic scene labeling problem which is able to enforce temporal consistency between consecutive video frames and take advantage of the 3D scene geometry to improve segmentation quality. The main contribution of this work lies in the novel use of a 3D scene reconstruction as a means to temporally couple the individual image segmentations, allowing information flow from 3D geometry to the 2D image space. As our results show, the proposed framework outperforms state-of-the-art methods and opens a new perspective towards a tighter interplay of 2D and 3D information in the scene understanding problem.
Close-Range Human Detection for Head-Mounted Cameras
In this paper we consider the problem of multi-person detection from the perspective of a head mounted stereo camera. As pedestrians close to the camera cannot be detected by classical full-body detectors due to strong occlusion, we propose a stereo depth-template based detection approach for close-range pedestrians. We perform a sliding window procedure, where we measure the similarity between a learned depth template and the depth image. To reduce the search space of the detector we slide the detector only over few selected regions of interest that are generated based on depth information. The region-of-interest selection allows us to further constrain the number of scales to be evaluated, significantly reducing the computational cost. We present experiments on stereo sequences recorded from a head-mounted camera setup in crowded shopping street scenarios and show that our proposed approach achieves superior performance on this very challenging data.
Improving Image-Based Localization by Active Correspondence Search
We propose a powerful pipeline for determining the pose of a query image relative to a point cloud reconstruction of a large scene consisting of more than one million 3D points. The key component of our approach is an efficient and effective search method to establish matches between image features and scene points needed for pose estimation. Our main contribution is a framework for actively searching for additional matches, based on both 2D-to-3D and 3D-to-2D search. A unified formulation of search in both directions allows us to exploit the distinct advantages of both strategies, while avoiding their weaknesses. Due to active search, the resulting pipeline is able to close the gap in registration performance observed between efficient search methods and approaches that are allowed to run for multiple seconds, without sacrificing run-time efficiency. Our method achieves the best registration performance published so far on three standard benchmark datasets, with run-times comparable or superior to the fastest state-of-the-art methods.
The original publication will be available at www.springerlink.com upon publication.
Image Retrieval for Image-Based Localization Revisited
To reliably determine the camera pose of an image relative to a 3D point cloud of a scene, correspondences between 2D features and 3D points are needed. Recent work has demonstrated that directly matching the features against the points outperforms methods that take an intermediate image retrieval step in terms of the number of images that can be localized successfully. Yet, direct matching is inherently less scalable than retrieval-based approaches. In this paper, we therefore analyze the algorithmic factors that cause the performance gap and identify false positive votes as the main source of the gap. Based on a detailed experimental evaluation, we show that retrieval methods using a selective voting scheme are able to outperform state-of-the-art direct matching methods. We explore how both selective voting and correspondence computation can be accelerated by using a Hamming embedding of feature descriptors. Furthermore, we introduce a new dataset with challenging query images for the evaluation of image-based localization.
Towards Fast Image-Based Localization on a City-Scale
Recent developments in Structure-from-Motion approaches allow the reconstructions of large parts of urban scenes. The available models can in turn be used for accurate image-based localization via pose estimation from 2D-to-3D correspondences. In this paper, we analyze a recently proposed localization method that achieves state-of-the-art localization performance using a visual vocabulary quantization for efficient 2D-to-3D correspondence search. We show that using only a subset of the original models allows the method to achieve a similar localization performance. While this gain can come at additional computational cost depending on the dataset, the reduced model requires significantly less memory, allowing the method to handle even larger datasets. We study how the size of the subset, as well as the quantization, affect both the search for matches and the time needed by RANSAC for pose estimation.
The original publication will be available at www.springerlink.com upon publication.
Digitization of Inaccessible Archeological Sites with Autonomous Mobile Robots
Discovering Favorite Views of Popular Places with Iconoid Shift

In this paper, we propose a novel algorithm for automatic landmark building discovery in large, unstructured image collections. In contrast to other approaches which aim at a hard clustering, we regard the task as a mode estimation problem. Our algorithm searches for local attractors in the image distribution that have a maximal mutual homography overlap with the images in their neighborhood. Those attractors correspond to central, iconic views of single objects or buildings, which we efficiently extract using a medoid shift search with a novel distance measure. We propose efficient algorithms for performing this search. Most importantly, our approach performs only an efficient local exploration of the matching graph that makes it applicable for large-scale analysis of photo collections. We show experimental results validating our approach on a dataset of 500k images of the inner city of Paris.
@inproceedings{DBLP:conf/iccv/WeyandL11,
author = {Tobias Weyand and
Bastian Leibe},
title = {Discovering favorite views of popular places with iconoid shift},
booktitle = {{IEEE} International Conference on Computer Vision, {ICCV} 2011, Barcelona,
Spain, November 6-13, 2011},
pages = {1132--1139},
year = {2011},
crossref = {DBLP:conf/iccv/2011},
url = {http://dx.doi.org/10.1109/ICCV.2011.6126361},
doi = {10.1109/ICCV.2011.6126361},
timestamp = {Thu, 19 Jan 2012 18:05:15 +0100},
biburl = {http://dblp.uni-trier.de/rec/bib/conf/iccv/WeyandL11},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Level-Set Person Segmentation and Tracking with Multi-Region Appearance Models and Top-Down Shape Information
In this paper, we address the problem of segmentationbased tracking of multiple articulated persons. We propose two improvements to current level-set tracking formulations. The first is a localized appearance model that uses additional level-sets in order to enforce a hierarchical subdivision of the object shape into multiple connected regions with distinct appearance models. The second is a novel mechanism to include detailed object shape information in the form of a per-pixel figure/ground probability map obtained from an object detection process. Both contributions are seamlessly integrated into the level-set framework. Together, they considerably improve the accuracy of the tracked segmentations. We experimentally evaluate our proposed approach on two challenging sequences and demonstrate its good performance in practice.
@inproceedings{DBLP:conf/iccv/HorbertRL11,
author = {Esther Horbert and
Konstantinos Rematas and
Bastian Leibe},
title = {Level-set person segmentation and tracking with multi-region appearance
models and top-down shape information},
booktitle = {{IEEE} International Conference on Computer Vision, {ICCV} 2011, Barcelona,
Spain, November 6-13, 2011},
pages = {1871--1878},
year = {2011},
crossref = {DBLP:conf/iccv/2011},
url = {http://dx.doi.org/10.1109/ICCV.2011.6126455},
doi = {10.1109/ICCV.2011.6126455},
timestamp = {Thu, 19 Jan 2012 18:05:15 +0100},
biburl = {http://dblp.uni-trier.de/rec/bib/conf/iccv/HorbertRL11},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Fast Image-Based Localization using Direct 2D-to-3D Matching

Estimating the position and orientation of a camera given an image taken by it is an important step in many interesting applications such as tourist navigations, robotics, augmented reality and incremental Structure-from-Motion reconstruction. To do so, we have to find correspondences between structures seen in the image and a 3D representation of the scene. Due to the recent advances in the field of Structure-from-Motion it is now possible to reconstruct large scenes up to the level of an entire city in very little time. We can use these results to enable image-based localization of a camera (and its user) on a large scale. However, when processing such large data, the computation between points in the image and points in the model quickly becomes the bottleneck of the localization pipeline. Therefore, it is extremely important to develop methods that are able to effectively and efficiently handle such large environments and that scale well to even larger scenes.
Multi-Class Image Labeling with Top-Down Segmentation and Generalized Robust P^N Potentials

We propose a novel formulation for the scene labeling problem which is able to combine object detections with pixel-level information in a Conditional Random Field (CRF) framework. Since object detection and multi-class image labeling are mutually informative problems, pixel-wise segmentation can benefit from powerful object detectors and vice versa. The main contribution of the current work lies in the incorporation of topdown object segmentations as generalized robust P N potentials into the CRF formulation. These potentials present a principled manner to convey soft object segmentations into a unified energy minimization framework, enabling joint optimization and thus mutual benefit for both problems. As our results show, the proposed approach outperforms the state-of-the-art methods on the categories for which object detections are available. Quantitative and qualitative experiments show the effectiveness of the proposed method.
@inproceedings{DBLP:conf/bmvc/FlorosRL11,
author = {Georgios Floros and
Konstantinos Rematas and
Bastian Leibe},
title = {Multi-Class Image Labeling with Top-Down Segmentation and Generalized
Robust {\textdollar}P{\^{}}N{\textdollar} Potentials},
booktitle = {British Machine Vision Conference, {BMVC} 2011, Dundee, UK, August
29 - September 2, 2011. Proceedings},
pages = {1--11},
year = {2011},
crossref = {DBLP:conf/bmvc/2011},
url = {http://dx.doi.org/10.5244/C.25.79},
doi = {10.5244/C.25.79},
timestamp = {Wed, 24 Apr 2013 17:19:07 +0200},
biburl = {http://dblp.uni-trier.de/rec/bib/conf/bmvc/FlorosRL11},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Real-Time Multi-Person Tracking with Time-Constrained Detection
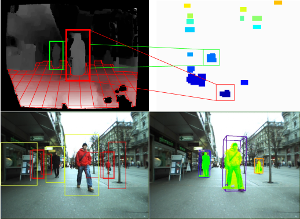
This paper presents a robust real-time multi-person tracking framework for busy street scenes. Tracking-by-detection approaches have recently been successfully applied to this task. However, their run-time is still limited by the computationally expensive object detection component. In this paper, we therefore consider the problem of making best use of an object detector with a fixed and very small time budget. The question we ask is: given a fixed time budget that allows for detector-based verification of k small regions-of-interest (ROIs) in the image, what are the best regions to attend to in order to obtain stable tracking performance? We address this problem by applying a statistical Poisson process model in order to rate the urgency by which individual ROIs should be attended to. These ROIs are initially extracted from a 3D depth-based occupancy map of the scene and are then tracked over time. This allows us to balance the system resources in order to satisfy the twin goals of detecting newly appearing objects, while maintaining the quality of existing object trajectories.
@inproceedings{DBLP:conf/bmvc/MitzelSL11,
author = {Dennis Mitzel and
Patrick Sudowe and
Bastian Leibe},
title = {Real-Time Multi-Person Tracking with Time-Constrained Detection},
booktitle = {British Machine Vision Conference, {BMVC} 2011, Dundee, UK, August
29 - September 2, 2011. Proceedings},
pages = {1--11},
year = {2011},
crossref = {DBLP:conf/bmvc/2011},
url = {http://dx.doi.org/10.5244/C.25.104},
doi = {10.5244/C.25.104},
timestamp = {Wed, 24 Apr 2013 17:19:07 +0200},
biburl = {http://dblp.uni-trier.de/rec/bib/conf/bmvc/MitzelSL11},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Lying Pose Recognition for Elderly Fall Detection

This paper proposes a pipeline for lying pose recognition from single images, which is designed for health-care robots to find fallen people. We firstly detect object bounding boxes by a mixture of viewpoint-specific part based model detectors and later estimate a detailed configuration of body parts on the detected regions by a finer tree-structured model. Moreover, we exploit the information provided by detection to infer a reasonable limb prior for the pose estimation stage. Additional robustness is achieved by integrating a viewpointspecific foreground segmentation into the detection and body pose estimation stages. This step yields a refinement of detection scores and a better color model to initialize pose estimation. We apply our proposed approach to challenging data sets of fallen people in different scenarios. Our quantitative and qualitative results demonstrate that the part-based model significantly outperforms a holistic model based on same feature type for lying pose detection. Moreover, our system offers a reasonable estimation for the body configuration of varying lying poses.
@inproceedings{DBLP:conf/rss/WangZL11,
author = {Simin Wang and
Salim Zabir and
Bastian Leibe},
title = {Lying Pose Recognition for Elderly Fall Detection},
booktitle = {Robotics: Science and Systems VII, University of Southern California,
Los Angeles, CA, USA, June 27-30, 2011},
year = {2011},
crossref = {DBLP:conf/rss/2011},
url = {http://www.roboticsproceedings.org/rss07/p44.html},
timestamp = {Sun, 18 Dec 2011 20:27:03 +0100},
biburl = {http://dblp.uni-trier.de/rec/bib/conf/rss/WangZL11},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Online Multi-Person Tracking-by-Detection from a Single, Uncalibrated Camera

In this paper, we address the problem of automatically detecting and tracking a variable number of persons in complex scenes using a monocular, potentially moving, uncalibrated camera. We propose a novel approach for multi-person tracking-bydetection in a particle filtering framework. In addition to final high-confidence detections, our algorithm uses the continuous confidence of pedestrian detectors and online trained, instance-specific classifiers as a graded observation model. Thus, generic object category knowledge is complemented by instance-specific information. The main contribution of this paper is to explore how these unreliable information sources can be used for robust multi-person tracking. The algorithm detects and tracks a large number of dynamically moving persons in complex scenes with occlusions, does not rely on background modeling, requires no camera or ground plane calibration, and only makes use of information from the past. Hence, it imposes very few restrictions and is suitable for online applications. Our experiments show that the method yields good tracking performance in a large variety of highly dynamic scenarios, such as typical surveillance videos, webcam footage, or sports sequences. We demonstrate that our algorithm outperforms other methods that rely on additional information. Furthermore, we analyze the influence of different algorithm components on the robustness.
@article{Breitenstein:2011:OMT:2006854.2007007,
author = {Breitenstein, Michael D. and Reichlin, Fabian and Leibe, Bastian and Koller-Meier, Esther and Van Gool, Luc},
title = {Online Multiperson Tracking-by-Detection from a Single, Uncalibrated Camera},
journal = {IEEE Trans. Pattern Anal. Mach. Intell.},
issue_date = {September 2011},
volume = {33},
number = {9},
month = sep,
year = {2011},
issn = {0162-8828},
pages = {1820--1833},
numpages = {14},
url = {http://dx.doi.org/10.1109/TPAMI.2010.232},
doi = {10.1109/TPAMI.2010.232},
acmid = {2007007},
publisher = {IEEE Computer Society},
address = {Washington, DC, USA},
keywords = {Multi-object tracking, tracking-by-detection, detector confidence particle filter, pedestrian detection, particle filtering, sequential Monte Carlo estimation, online learning, detector confidence, surveillance, sports analysis, traffic safety.},
}
Online Loop Closure for Real-time Interactive 3D Scanning

We present a real-time interactive 3D scanning system that allows users to scan complete object geometry by turning the object around in front of a real-time 3D range scanner. The incoming 3D surface patches are registered and integrated into an online 3D point cloud. In contrast to previous systems the online reconstructed 3D model also serves as final result. Registration error accumulation which leads to the well-known loop closure problem is addressed already during the scanning session by distorting the object as rigidly as possible. Scanning errors are removed by explicitly handling outliers based on visibility constraints. Thus, no additional post-processing is required which otherwise might lead to artifacts in the model reconstruction. Both geometry and texture are used for registration which allows for a wide range of objects with different geometric and photometric properties to be scanned. We show the results of our modeling approach on several difficult real-world objects. Qualitative and quantitative results are given for both synthetic and real data demonstrating the importance of online loop closure and outlier handling for model reconstruction. We show that our real-time scanning system has comparable accuracy to offline methods with the additional benefit of immediate feedback and results.
@article{DBLP:journals/cviu/WeiseWLG11,
author = {Thibaut Weise and
Thomas Wismer and
Bastian Leibe and
Luc J. Van Gool},
title = {Online loop closure for real-time interactive 3D scanning},
journal = {Computer Vision and Image Understanding},
volume = {115},
number = {5},
pages = {635--648},
year = {2011},
url = {http://dx.doi.org/10.1016/j.cviu.2010.11.023},
doi = {10.1016/j.cviu.2010.11.023},
timestamp = {Mon, 18 Apr 2011 08:20:18 +0200},
biburl = {http://dblp.uni-trier.de/rec/bib/journals/cviu/WeiseWLG11},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Fast PRISM: Branch and Bound Hough Transform for Object Class Detection
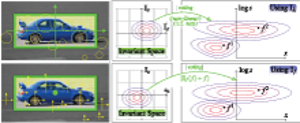
This paper addresses the task of efficient object class detection by means of the Hough transform. This approach has been made popular by the Implicit Shape Model (ISM) and has been adopted many times. Although ISM exhibits robust detection performance, its probabilistic formulation is unsatisfactory. The PRincipled Implicit Shape Model (PRISM) overcomes these problems by interpreting Hough voting as a dual implementation of linear sliding-window detection. It thereby gives a sound justification to the voting procedure and imposes minimal constraints. We demonstrate PRISM’s flexibility by two complementary implementations: a generatively trained Gaussian Mixture Model as well as a discriminatively trained histogram approach. Both systems achieve state-of-the-art performance. Detections are found by gradient-based or branch and bound search, respectively. The latter greatly benefits from PRISM’s feature-centric view. It thereby avoids the unfavorable memory trade-off and any on-line pre-processing of the original Efficient Subwindow Search (ESS). Moreover, our approach takes account of the features’ scale value while ESS does not. Finally, we show how to avoid soft-matching and spatial pyramid descriptors during detection without losing their positive effect. This makes algorithms simpler and faster. Both are possible if the object model is properly regularized and we discuss a modification of SVMs which allows for doing so.
@article{DBLP:journals/ijcv/LehmannLG11,
author = {Alain D. Lehmann and
Bastian Leibe and
Luc J. Van Gool},
title = {Fast {PRISM:} Branch and Bound Hough Transform for Object Class Detection},
journal = {International Journal of Computer Vision},
volume = {94},
number = {2},
pages = {175--197},
year = {2011},
url = {http://dx.doi.org/10.1007/s11263-010-0342-x},
doi = {10.1007/s11263-010-0342-x},
timestamp = {Wed, 19 Feb 2014 09:33:24 +0100},
biburl = {http://dblp.uni-trier.de/rec/bib/journals/ijcv/LehmannLG11},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Real Time Vision Based Multi-person Tracking for Mobile Robotics and Intelligent Vehicles
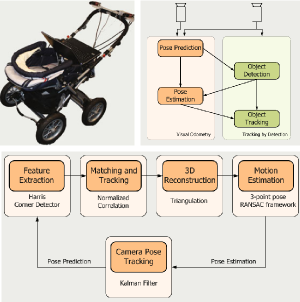
In this paper, we present a real-time vision-based multiperson tracking system working in crowded urban environments. Our approach combines stereo visual odometry estimation, HOG pedestrian detection, and multi-hypothesis tracking-by-detection to a robust tracking framework that runs on a single laptop with a CUDA-enabled graphics card. Through shifting the expensive computations to the GPU and making extensive use of scene geometry constraints we could build up a mobile system that runs with 10Hz. We experimentally demonstrate on several challenging sequences that our approach achieves competitive tracking performance.
@inproceedings{DBLP:conf/icira/MitzelFSZL11,
author = {Dennis Mitzel and
Georgios Floros and
Patrick Sudowe and
Benito van der Zander and
Bastian Leibe},
title = {Real Time Vision Based Multi-person Tracking for Mobile Robotics and
Intelligent Vehicles},
booktitle = {Intelligent Robotics and Applications - 4th International Conference,
{ICIRA} 2011, Aachen, Germany, December 6-8, 2011, Proceedings, Part
{II}},
pages = {105--115},
year = {2011},
crossref = {DBLP:conf/icira/2011-2},
url = {http://dx.doi.org/10.1007/978-3-642-25489-5_11},
doi = {10.1007/978-3-642-25489-5_11},
timestamp = {Fri, 02 Dec 2011 12:36:17 +0100},
biburl = {http://dblp.uni-trier.de/rec/bib/conf/icira/MitzelFSZL11},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Efficient Use of Geometric Constraints for Sliding-Window Object Detection in Video

We systematically investigate how geometric constraints can be used for efficient sliding-window object detection. Starting with a general characterization of the space of sliding-window locations that correspond to geometrically valid object detections, we derive a general algorithm for incorporating ground plane constraints directly into the detector computation. Our approach is indifferent to the choice of detection algorithm and can be applied in a wide range of scenarios. In particular, it allows to effortlessly combine multiple different detectors and to automatically compute regions-of-interest for each of them. We demonstrate its potential in a fast CUDA implementation of the HOG detector and show that our algorithm enables a factor 2-4 speed improvement on top of all other optimizations.
Bibtex:
@InProceedings{Sudowe11ICVS,
author = {P. Sudowe and B. Leibe},
title = {{Efficient Use of Geometric Constraints for Sliding-Window Object Detection in Video}},
booktitle = {{International Conference on Computer Vision Systems (ICVS'11)}},
OPTpages = {},
year = {2011},
}
Efficient Object Detection and Segmentation with a Cascaded Hough Forest ISM

Visual pedestrian/car detection is very important for mobile robotics in complex outdoor scenarios. In this paper, we propose two improvements to the popular Hough Forest object detection framework. We show how this framework can be extended to efficiently infer precise probabilistic segmentations for the object hypotheses and how those segmentations can be used to improve the final hypothesis selection. Our approach benefits from the dense sampling of a Hough Forest detector, which results in qualitatively better segmentations than previous voting based methods. We show that, compared to previous approaches, the dense feature sampling necessitates several adaptations to the segmentation framework and propose an improved formulation. In addition, we propose an efficient cascaded voting scheme that significantly reduces the effort of the Hough voting stage without loss in accuracy. We quantitatively evaluate our approach on several challenging sequences, reaching stateof-the-art performance and showing the effectiveness of the proposed framework.
@inproceedings{DBLP:conf/iccvw/RematasL11,
author = {Konstantinos Rematas and
Bastian Leibe},
title = {Efficient object detection and segmentation with a cascaded Hough
Forest {ISM}},
booktitle = {{IEEE} International Conference on Computer Vision Workshops, {ICCV}
2011 Workshops, Barcelona, Spain, November 6-13, 2011},
pages = {966--973},
year = {2011},
crossref = {DBLP:conf/iccvw/2011},
url = {http://dx.doi.org/10.1109/ICCVW.2011.6130356},
doi = {10.1109/ICCVW.2011.6130356},
timestamp = {Fri, 20 Jan 2012 17:21:11 +0100},
biburl = {http://dblp.uni-trier.de/rec/bib/conf/iccvw/RematasL11},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Real-Time Multi-Person Tracking with Detector Assisted Structure Propagation

Classical tracking-by-detection approaches require a robust object detector that needs to be executed in each frame. However the detector is typically the most computationally expensive component, especially if more than one object class needs to be detected. In this paper we investigate how the usage of the object detector can be reduced by using stereo range data for following detected objects over time. To this end we propose a hybrid tracking framework consisting of a stereo based ICP (Iterative Closest Point) tracker and a high-level multi-hypothesis tracker. Initiated by a detector response, the ICP tracker follows individual pedestrians over time using just the raw depth information. Its output is then fed into the high-level tracker that is responsible for solving long-term data association and occlusion handling. In addition, we propose to constrain the detector to run only on some small regions of interest (ROIs) that are extracted from a 3D depth based occupancy map of the scene. The ROIs are tracked over time and only newly appearing ROIs are evaluated by the detector. We present experiments on real stereo sequences recorded from a moving camera setup in urban scenarios and show that our proposed approach achieves state of the art performance
@inproceedings{DBLP:conf/iccvw/MitzelL11,
author = {Dennis Mitzel and
Bastian Leibe},
title = {Real-time multi-person tracking with detector assisted structure propagation},
booktitle = {{IEEE} International Conference on Computer Vision Workshops, {ICCV}
2011 Workshops, Barcelona, Spain, November 6-13, 2011},
pages = {974--981},
year = {2011},
crossref = {DBLP:conf/iccvw/2011},
url = {http://dx.doi.org/10.1109/ICCVW.2011.6130357},
doi = {10.1109/ICCVW.2011.6130357},
timestamp = {Fri, 20 Jan 2012 17:21:11 +0100},
biburl = {http://dblp.uni-trier.de/rec/bib/conf/iccvw/MitzelL11},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Figure-Ground Segmentation - Object Based

Tracking with a moving camera is a challenging task due to the combined effects of scene activity and egomotion. As there is no longer a static image background from which moving objects can easily be distinguished, dedicated effort must be spent on detecting objects of interest in the input images and on determining their precise extent. In recent years, there has been considerable progress in the development of approaches that apply object detection and class-specific segmentation in order to facilitate tracking under such circumstances (“tracking-by-detection”). In this chapter, we will give an overview of the main concepts and techniques used in such tracking-by-detection systems. In detail, the chapter will present fundamental techniques and current state-of-the-art approaches for performing object detection, for obtaining detailed object segmentations from single images based on top–down and bottom–up cues, and for propagating this information over time.
Visual Object Recognition

The visual recognition problem is central to computer vision research. From robotics to information retrieval, many desired applications demand the ability to identify and localize categories, places, and objects. This tutorial overviews computer vision algorithms for visual object recognition and image classification. We introduce primary representations and learning approaches, with an emphasis on recent advances in the field. The target audience consists of researchers or students working in AI, robotics, or vision who would like to understand what methods and representations are available for these problems. This lecture summarizes what is and isn't possible to do reliably today, and overviews key concepts that could be employed in systems requiring visual categorization.
Table of Contents: Introduction / Overview: Recognition of Specific Objects / Local Features: Detection and Description / Matching Local Features / Geometric Verification of Matched Features / Example Systems: Specific-Object Recognition / Overview: Recognition of Generic Object Categories / Representations for Object Categories / Generic Object Detection: Finding and Scoring Candidates / Learning Generic Object Category Models / Example Systems: Generic Object Recognition / Other Considerations and Current Challenges / Conclusions
Motion Estimating Device

A motion estimating device first detects mobile objects Oi and Oi' in continuous image frames T and T', and acquires image areas Ri and Ri' corresponding to the mobile objects Oi and Oi'. Then, the motion estimating device removes the image areas Ri and Ri' corresponding to the mobile objects Oi and Oi' in the image frames T and T', extracts corresponding point pairs Pj of feature points between the image frames T and T' from the image areas having removed the image areas Ri and Ri', and carries out the motion estimation of the autonomous mobile machine between the image frames T and T' on the basis of the positional relationship of the corresponding point pairs Pj of feature points.
@misc{ess2012motion,
title={Motion estimating device},
author={Ess, A. and Leibe, B. and Schindler, K. and Van Gool, L. and Kitahama, K. and Funayama, R.},
url={http://www.google.com/patents/US8213684},
year={2012},
publisher={Google Patents},
note={US Patent 8,213,684}
}
Object Detection and Tracking for Autonomous Navigation in Dynamic Environments
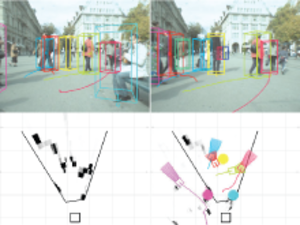
We address the problem of vision-based navigation in busy inner-city locations, using a stereo rig mounted on a mobile platform. In this scenario semantic information becomes important: rather than mod- elling moving objects as arbitrary obstacles, they should be categorised and tracked in order to predict their future behaviour. To this end, we combine classical geometric world mapping with object category detection and tracking. Object-category specific detectors serve to find instances of the most important object classes (in our case pedestrians and cars). Based on these detections, multi-object tracking recovers the objects’ trajectories, thereby making it possible to predict their future locations, and to employ dynamic path planning. The approach is evaluated on challenging, realistic video sequences recorded at busy inner-city locations.
@article{ess2010object,
title={Object detection and tracking for autonomous navigation in dynamic environments},
author={Ess, Andreas and Schindler, Konrad and Leibe, Bastian and Van Gool, Luc},
journal={The International Journal of Robotics Research},
volume={29},
number={14},
pages={1707--1725},
year={2010},
}
Multi-Person Tracking with Sparse Detection and Continuous Segmentation

This paper presents an integrated framework for mobile street-level tracking of multiple persons. In contrast to classic tracking-by-detection approa- ches, our framework employs an efficient level-set tracker in order to follow indi- vidual pedestrians over time. This low-level tracker is initialized and periodically updated by a pedestrian detector and is kept robust through a series of consis- tency checks. In order to cope with drift and to bridge occlusions, the resulting tracklet outputs are fed to a high-level multi-hypothesis tracker, which performs longer-term data association. This design has the advantage of simplifying short- term data association, resulting in higher-quality tracks that can be maintained even in situations where the pedestrian detector does no longer yield good de- tections. In addition, it requires the pedestrian detector to be active only part of the time, resulting in computational savings. We quantitatively evaluate our ap- proach on several challenging sequences and show that it achieves state-of-the-art performance.
@incollection{mitzel2010multi,
title={Multi-person tracking with sparse detection and continuous segmentation},
author={Mitzel, Dennis and Horbert, Esther and Ess, Andreas and Leibe, Bastian},
booktitle={ECCV},
pages={397--410},
year={2010},
}
Geometrically Constrained Level-Set Tracking for Automotive Applications
We propose a new approach for integrating geometric scene knowledge into a level-set tracking framework. Our approach is based on a novel constrained-homography transformation model that restricts the deformation space to physically plausible rigid motion on the ground plane. This model is especially suitable for tracking vehicles in automo- tive scenarios. Apart from reducing the number of parameters in the estimation, the 3D transformation model allows us to obtain additional information about the tracked objects and to recover their detailed 3D motion and orientation at every time step. We demonstrate how this in- formation can be used to improve a Kalman filter estimate of the tracked vehicle dynamics in a higher-level tracker, leading to more accurate ob- ject trajectories. We show the feasibility of this approach for an applica- tion of tracking cars in an inner-city scenario.
@incollection{horbert2010geometrically,
title={Geometrically constrained level set tracking for automotive applications},
author={Horbert, Esther and Mitzel, Dennis and Leibe, Bastian},
booktitle={Pattern Recognition},
pages={472--482},
year={2010},
}
An Evaluation of Two Automatic Landmark Building Discovery Algorithms for City Reconstruction

An important part of large-scale city reconstruction systems is an im- age clustering algorithm that divides a set of images into groups that should cover only one building each. Those groups then serve as input for structure from mo- tion systems. A variety of approaches for this mining step have been proposed recently, but there is a lack of comparative evaluations and realistic benchmarks. In this work, we want to fill this gap by comparing two state-of-the-art landmark mining algorithms: spectral clustering and min-hash. Furthermore, we introduce a new large-scale dataset for the evaluation of landmark mining algorithms con- sisting of 500k images from the inner city of Paris. We evaluate both algorithms on the well-known Oxford dataset and our Paris dataset and give a detailed com- parison of the clustering quality and computation time of the algorithms.
@incollection{weyand2010evaluation,
title={An evaluation of two automatic landmark building discovery algorithms for city reconstruction},
author={Weyand, Tobias and Hosang, Jan and Leibe, Bastian},
booktitle={ECCV Workshop},
pages={310--323},
year={2010},
}
Incremental Model Selection for Detection and Tracking of Planar Surfaces

Man-made environments are abundant with planar surfaces which have attractive properties and are a prerequisite for a variety of vision tasks. This paper presents an incremental model selection method to detect piecewise planar surfaces, where planes once detected are tracked and serve as priors in subsequent images. The novelty of this approach is to formalize model selection for plane detection with Minimal Description Length (MDL) in an incremental manner. In each iteration tracked planes and new planes computed from randomly sampled interest points are evaluated, the hypotheses which best explain the scene are retained, and their supporting points are marked so that in the next iteration random sampling is guided to unexplained points. Hence, the remaining finer scene details can be represented. We show in a quantitative evaluation that this new method competes with state of the art algorithms while it is more flexible to incorporate prior knowledge from tracking.
@inproceedings{prankl10incremental,
title = {Incremental Model Selection for Detection and Tracking of Planar Surfaces},
author = {Prankl, Johann and Zillich, Michael and Leibe, Bastian and Vincze, Markus},
year = {2010},
booktitle = {BMVC},
}
Automatic Detection and Tracking of Pedestrians from a Moving Stereo Rig
We report on a stereo system for 3D detection and tracking of pedestrians in urban traffic scenes. The system is built around a probabilistic environment model which fuses evidence from dense 3D reconstruction and image-based pedestrian detection into a consistent interpretation of the observed scene, and a multi-hypothesis tracker to reconstruct the pedestrians’ trajectories in 3D coordinates over time. Experiments on real stereo sequences recorded in busy inner-city scenarios are presented, in which the system achieves promising results.
@article{schindler2010automatic,
title={Automatic detection and tracking of pedestrians from a moving stereo rig},
author={Schindler, Konrad and Ess, Andreas and Leibe, Bastian and Van Gool, Luc},
journal={ISPRS Journal of Photogrammetry and Remote Sensing},
volume={65},
number={6},
pages={523--537},
year={2010},
}
SCRAMSAC: Improving RANSAC's Efficiency with a Spatial Consistency Filter

Geometric verification with RANSAC has become a crucial step for many local feature based matching applications. Therefore, the details of its implementation are directly relevant for an application's run-time and the quality of the estimated results. In this paper, we propose a RANSAC extension that is several orders of magnitude faster than standard RANSAC and as fast as and more robust to degenerate configurations than PROSAC, the currently fastest RANSAC extension from the literature. In addition, our proposed method is simple to implement and does not require parameter tuning. Its main component is a spatial consistency check that results in a reduced correspondence set with a significantly increased inlier ratio, leading to faster convergence of the remaining estimation steps. In addition, we experimentally demonstrate that RANSAC can operate entirely on the reduced set not only for sampling, but also for its consensus step, leading to additional speed-ups. The resulting approach is widely applicable and can be readily combined with other extensions from the literature. We quantitatively evaluate our approach's robustness on a variety of challenging datasets and compare its performance to the state-of-the-art.
Robust Tracking-by-Detection Using a Detector Confidence Particle Filter
We propose a novel approach for multi-person tracking-by-detection in a particle filtering framework. In addition to final high-confidence detections, our algorithm uses the continuous confidence of pedestrian detectors and online trained, instance-specific classifiers as a graded observation model. Thus, generic object category knowledge is complemented by instance-specific information. A main contribution of this paper is the exploration of how these unreliable information sources can be used for multi-person tracking. The resulting algorithm robustly tracks a large number of dynamically moving persons in complex scenes with occlusions, does not rely on background modeling, and operates entirely in 2D (requiring no camera or ground plane calibration). Our Markovian approach relies only on information from the past and is suitable for online applications. We evaluate the performance on a variety of datasets and show that it improves upon state-of-the-art methods.
Feature-Centric Efficient Subwindow Search
Many object detection systems rely on linear classifiers embedded in a sliding-window scheme. Such exhaustive search involves massive computation. Efficient Subwindow Search (ESS) [11] avoids this by means of branch and bound. However, ESS makes an unfavourable memory tradeoff. Memory usage scales with both image size and overall object model size. This risks becoming prohibitive in a multiclass system. In this paper, we make the connection between sliding-window and Hough-based object detection explicit. Then, we show that the feature-centric view of the latter also nicely fits with the branch and bound paradigm, while it avoids the ESS memory tradeoff. Moreover, on-line integral image calculations are not needed. Both theoretical and quantitative comparisons with the ESS bound are provided, showing that none of this comes at the expense of performance.
Using Multi-View Recognition and Meta-data Annotation to Guide a Robot's Attention

In the transition from industrial to service robotics, robots will have to deal with increasingly unpredictable and variable environments. We present a system that is able to recognize objects of a certain class in an image and to identify their parts for potential interactions. The method can recognize objects from arbitrary viewpoints and generalizes to instances that have never been observed during training, even if they are partially occluded and appear against cluttered backgrounds. Our approach builds on the Implicit Shape Model of Leibe et al. (2008). We extend it to couple recognition to the provision of meta-data useful for a task and to the case of multiple viewpoints by integrating it with the dense multi-view correspondence finder of Ferrari et al. (2006). Meta-data can be part labels but also depth estimates, information on material types, or any other pixelwise annotation. We present experimental results on wheelchairs, cars, and motorbikes.
Robust Multi-Person Tracking from a Mobile Platform

In this paper, we address the problem of multi-person tracking in busy pedestrian zones using a stereo rig mounted on a mobile platform. The complexity of the problem calls for an integrated solution that extracts as much visual information as possible and combines it through cognitive feedback cycles. We propose such an approach, which jointly estimates camera position, stereo depth, object detection, and tracking. The interplay between those components is represented by a graphical model. Since the model has to incorporate object-object interactions and temporal links to past frames, direct inference is intractable. We therefore propose a two-stage procedure: for each frame we first solve a simplified version of the model (disregarding interactions and temporal continuity) to estimate the scene geometry and an overcomplete set of object detections. Conditioned on these results, we then address object interactions, tracking, and prediction in a second step. The approach is experimentally evaluated on several long and difficult video sequences from busy inner-city locations. Our results show that the proposed integration makes it possible to deliver robust tracking performance in scenes of realistic complexity.
PRISM: PRincipled Implicit Shape Model

This paper addresses the problem of object detection by means of the Generalised Hough transform paradigm. The Implicit Shape Model (ISM) is a well-known approach based on this idea. It made this paradigm popular and has been adopted many times. Although the algorithm exhibits robust detection performance, its description, i.e. its probabilistic model, involves arguments which are unsatisfactory from a probabilistic standpoint. We propose a framework which overcomes these problems and gives a sound justification to the voting procedure. Furthermore, our framework allows for a formal understanding of the heuristic of soft-matching commonly used in visual vocabulary systems. We show that it is sufficient to use soft-matching during learning only and to perform fast nearest neighbour matching at recognition time (where speed is of prime importance). Our implementation is based on Gaussian Mixture Models (instead of kernel density estimators as with ISM) which lead to a fast gradient-based object detector.
Shape-from-Recognition: Recognition Enables Meta-Data Transfer

Low-level cues in an image not only allow to infer higher-level information like the presence of an object, but the inverse is also true. Category-level object recognition has now reached a level of maturity and accuracy that allows to successfully feed back its output to other processes. This is what we refer to as cognitive feedback. In this paper, we study one particular form of cognitive feedback, where the ability to recognize objects of a given category is exploited to infer different kinds of meta-data annotations for images of previously unseen object instances, in particular information on 3D shape. Meta-data can be discrete, real- or vector-valued. Our approach builds on the Implicit Shape Model of Leibe and Schiele [1], and extends it to transfer annotations from training images to test images. We focus on the inference of approximative 3D shape information about objects in a single 2D image. In experiments, we illustrate how our method can infer depth maps, surface normals and part labels for previously unseen object instances.
Moving Obstacle Detection in Highly Dynamic Scenes
We address the problem of vision-based multi-person tracking in busy pedestrian zones using a stereo rig mounted on a mobile platform. Specifically, we are interested in the application of such a system for supporting path planning algorithms in the avoidance of dynamic obstacles. The complexity of the problem calls for an integrated solution, which extracts as much visual information as possible and combines it through cognitive feedback. We propose such an approach, which jointly estimates camera position, stereo depth, object detections, and trajectories based only on visual information. The interplay between these components is represented in a graphical model. For each frame, we first estimate the ground surface together with a set of object detections. Based on these results, we then address object interactions and estimate trajectories. Finally, we employ the tracking results to predict future motion for dynamic objects and fuse this information with a static occupancy map estimated from dense stereo. The approach is experimentally evaluated on several long and challenging video sequences from busy inner-city locations recorded with different mobile setups. The results show that the proposed integration makes stable tracking and motion prediction possible, and thereby enables path planning in complex and highly dynamic scenes.
In-hand Scanning with Online Loop Closure

We present a complete 3D in-hand scanning system that allows users to scan objects by simply turning them freely in front of a real-time 3D range scanner. The 3D object model is reconstructed online as a point cloud by registering and integrating the incoming 3D patches with the online 3D model. The accumulation of registration errors leads to the well-known loop closure problem. We address this issue already during the scanning session by distorting the object as rigidly as possible. Scanning errors are removed by explicitly handling outliers. As a result of our proposed online modeling and error handling procedure, the online model is of sufficiently high quality to serve as the final model. Thus, no additional post-processing is required which might lead to artifacts in the model reconstruction. We demonstrate our approach on several difficult real-world objects and quantitatively evaluate the resulting modeling accuracy.
Markovian Tracking-by-Detection from a Single, Uncalibrated Camera

We present an algorithm for multi-person tracking-by-detection in a particle filtering framework. To address the unreliability of current state-of-the-art object detectors, our algorithm tightly couples object detection, classification, and tracking components. Instead of relying only on the final, sparse output from a detector, we additionally employ its continuous intermediate output to impart our approach with more flexibility to handle difficult situations. The resulting algorithm robustly tracks a variable number of dynamically moving persons in complex scenes with occlusions. The approach does not rely on background modeling and is based only on 2D information from a single camera, not requiring any camera or ground plane calibration. We evaluate the algorithm on the PETS’09 tracking dataset and discuss the importance of the different algorithm components to robustly handle difficult situations.
Improved Multi-Person Tracking with Active Occlusion Handling
We address the problem of vision-based multi-person tracking in busy inner-city locations using a stereo rig mounted on a mobile platform. Specifically, we are interested in the application of such a system for autonomous navigation and path planning. In such a scenario, semantic information about the moving scene objects becomes important. In order to estimate this robustly, we combine classical geometric world mapping with multi-person detection and tracking. In this paper, we refine an approach presented in earlier work, which jointly estimates camera position, stereo depth, object detections, and trajectories based only on visual information. We analyze the influence of the trajectory generator, which forms part of any tracking-by-detection system, and propose a set of measures to improve its performance. The extensions are experimentally evaluated on challenging, realistic video sequences recorded at busy inner-city locations. The results show that the proposed extensions significantly improve overall system performance, making the resulting detecting and tracking capabilities an interesting component of future navigation system for highly dynamic scenes.
Robust Object Detection with Interleaved Categorization and Segmentation
This paper presents a novel method for detecting and localizing objects of a visual category in cluttered real-world scenes. Our approach considers object categorization and figure-ground segmentation as two interleaved processes that closely collaborate towards a common goal. As shown in our work, the tight coupling between those two processes allows them to benefit from each other and improve the combined performance. The core part of our approach is a highly flexible learned representation for object shape that can combine the information observed on different training examples in a probabilistic extension of the Generalized Hough Transform. The resulting approach can detect categorical objects in novel images and automatically infer a probabilistic segmentation from the recognition result. This segmentation is then in turn used to again improve recognition by allowing the system to focus its efforts on object pixels and to discard misleading influences from the background. Moreover, the information from where in the image a hypothesis draws its support is employed in an MDL based hypothesis verification stage to resolve ambiguities between overlapping hypotheses and factor out the effects of partial occlusion. An extensive evaluation on several large data sets shows that the proposed system is applicable to a range of different object categories, including both rigid and articulated objects. In addition, its flexible representation allows it to achieve competitive object detection performance already from training sets that are between one and two orders of magnitude smaller than those used in comparable systems.
3D Urban Scene Modeling Integrating Recognition and Reconstruction

Supplying realistically textured 3D city models at ground level promises to be useful for pre-visualizing upcoming traffic situations in car navigation systems. Because this previsualization can be rendered from the expected future viewpoints of the driver, the required maneuver will be more easily understandable. 3D city models can be reconstructed from the imagery recorded by surveying vehicles. The vastness of image material gathered by these vehicles, however, puts extreme demands on vision algorithms to ensure their practical usability. Algorithms need to be as fast as possible and should result in compact, memory efficient 3D city models for future ease of distribution and visualization. For the considered application, these are not contradictory demands. Simplified geometry assumptions can speed up vision algorithms while automatically guaranteeing compact geometry models. In this paper, we present a novel city modeling framework which builds upon this philosophy to create 3D content at high speed. Objects in the environment, such as cars and pedestrians, may however disturb the reconstruction, as they violate the simplified geometry assumptions, leading to visually unpleasant artifacts and degrading the visual realism of the resulting 3D city model. Unfortunately, such objects are prevalent in urban scenes. We therefore extend the reconstruction framework by integrating it with an object recognition module that automatically detects cars in the input video streams and localizes them in 3D. The two components of our system are tightly integrated and benefit from each other’s continuous input. 3D reconstruction delivers geometric scene context, which greatly helps improve detection precision. The detected car locations, on the other hand, are used to instantiate virtual placeholder models which augment the visual realism of the reconstructed city model.
Using Recognition to Guide a Robot’s Attention

In the transition from industrial to service robotics, robots will have to deal with increasingly unpredictable and variable environments. We present a system that is able to recognize objects of a certain class in an image and to identify their parts for potential interactions. This is demonstrated for object instances that have never been observed during training, and under partial occlusion and against cluttered backgrounds. Our approach builds on the Implicit Shape Model of Leibe and Schiele, and extends it to couple recognition to the provision of meta-data useful for a task. Meta-data can for example consist of part labels or depth estimates. We present experimental results on wheelchairs and cars.
Measuring camera translation by the dominant apical angle

This paper provides a technique for measuring camera translation relatively w.r.t. the scene from two images. We demonstrate that the amount of the translation can be reliably measured for general as well as planar scenes by the most frequent apical angle, the angle under which the camera centers are seen from the perspective of the reconstructed scene points. Simulated experiments show that the dominant apical angle is a linear function of the length of the true camera translation. In a real experiment, we demonstrate that by skipping image pairs with too small motion, we can reliably initialize structure from motion, compute accurate camera trajectory in order to rectify images and use the ground plane constraint in recognition of pedestrians in a hand-held video sequence.
Accurate and Robust Registration for In-hand Modeling

We present fast 3D surface registration methods for inhand modeling. This allows users to scan complete objects swiftly by simply turning them around in front of the scanner. The paper makes two main contributions. First, we propose an efficient method for detecting registration failures, which is a vital property of any automatic modeling system. Our method is based on two different consistency tests, one based on geometry and one based on texture. Second, we extend ICP by three additional fast registration methods for both coarse and fine alignment based on both texture and geometry. Each of those methods brings in additional information that can compensate for ambiguities in the other cues. Together, they allow for the robust reconstruction of a large variety of objects with different geometric and photometric properties. Finally, we show how both failure detection and fast registration can be combined in a practical and robust in-hand modeling system that operates at interactive frame rates.
A Mobile Vision System for Robust Multi-Person Tracking

We present a mobile vision system for multi-person tracking in busy environments. Specifically, the system integrates continuous visual odometry computation with tracking-by-detection in order to track pedestrians in spite of frequent occlusions and egomotion of the camera rig. To achieve reliable performance under real-world conditions, it has long been advocated to extract and combine as much visual information as possible. We propose a way to closely integrate the vision modules for visual odometry, pedestrian detection, depth estimation, and tracking. The integration naturally leads to several cognitive feedback loops between the modules. Among others, we propose a novel feedback connection from the object detector to visual odometry which utilizes the semantic knowledge of detection to stabilize localization. Feedback loops always carry the danger that erroneous feedback from one module is amplified and causes the entire system to become instable. We therefore incorporate automatic failure detection and recovery, allowing the system to continue when a module becomes unreliable. The approach is experimentally evaluated on several long and difficult video sequences from busy inner-city locations. Our results show that the proposed integration makes it possible to deliver stable tracking performance in scenes of previously infeasible complexity.
World-scale Mining of Objects and Events from Community Photo Collections

In this paper, we describe an approach for mining images of objects (such as touristic sights) from community photo col- lections in an unsupervised fashion. Our approach relies on retrieving geotagged photos from those web-sites using a grid of geospatial tiles. The downloaded photos are clustered into potentially interesting entities through a processing pipeline of several modalities, including visual, textual and spatial proximity. The resulting clusters are analyzed and are automatically classified into objects and events. Using mining techniques, we then find text labels for these clusters, which are used to again assign each cluster to a corresponding Wikipedia article in a fully unsupervised manner. A final ver- ification step uses the contents (including images) from the selected Wikipedia article to verify the cluster-article assignment. We demonstrate this approach on several urban areas, densely covering an area of over 700 square kilometers and mining over 200,000 photos, making it probably the largest experiment of its kind to date.
Probabilistic Parameter Selection for Learning Scene Structure from Video
We present an online learning approach for robustly combining unreliable observations from a pedestrian detector to estimate the rough 3D scene geometry from video sequences of a static camera. Our approach is based on an entropy modelling framework, which allows to simultaneously adapt the detector parameters, such that the expected information gain about the scene structure is maximised. As a result, our approach automatically restricts the detector scale range for each image region as the estimation results become more confident, thus improving detector run-time and limiting false positives.
Coupled Object Detection and Tracking from Static Cameras and Moving Vehicles

We present a novel approach for multi-object tracking which considers object detection and spacetime trajectory estimation as a coupled optimization problem. Our approach is formulated in a Minimum Description Length hypothesis selection framework, which allows our system to recover from mismatches and temporarily lost tracks. Building upon a state-of-the-art object detector, it performs multi-view/multi-category object recognition to detect cars and pedestrians in the input images. The 2D object detections are checked for their consistency with (automatically estimated) scene geometry and are converted to 3D observations, which are accumulated in a world coordinate frame. A subsequent trajectory estimation module analyzes the resulting 3D observations to find physically plausible spacetime trajectories. Tracking is achieved by performing model selection after every frame. At each time instant, our approach searches for the globally optimal set of spacetime trajectories which provides the best explanation for the current image and for all evidence collected so far, while satisfying the constraints that no two objects may occupy the same physical space, nor explain the same image pixels at any point in time. Successful trajectory hypotheses are then fed back to guide object detection in future frames. The optimization procedure is kept efficient through incremental computation and conservative hypothesis pruning. We evaluate our approach on several challenging video sequences and demonstrate its performance on both a surveillance-type scenario and a scenario where the input videos are taken from inside a moving vehicle passing through crowded city areas.
Articulated Multi-Body Tracking Under Egomotion

In this paper, we address the problem of 3D articulated multi-person tracking in busy street scenes from a moving, human-level observer. In order to handle the complexity of multi-person interactions, we propose to pursue a two-stage strategy. A multi-body detection-based tracker first analyzes the scene and recovers individual pedestrian trajectories, bridging sensor gaps and resolving temporary occlusions. A specialized articulated tracker is then applied to each recovered pedestrian trajectory in parallel to estimate the tracked person's precise body pose over time. This articulated tracker is implemented in a Gaussian Process framework and operates on global pedestrian silhouettes using a learned statistical representation of human body dynamics. We interface the two tracking levels through a guided segmentation stage, which combines traditional bottom-up cues with top-down information from a human detector and the articulated tracker's shape prediction. We show the proposed approach's viability and demonstrate its performance for articulated multi-person tracking on several challenging video sequences of a busy inner-city scenario.
Dynamic 3D Scene Analysis from a Moving Vehicle

In this paper, we present a system that integrates fully automatic scene geometry estimation, 2D object detection, 3D localization, trajectory estimation, and tracking for dynamic scene interpretation from a moving vehicle. Our sole input are two video streams from a calibrated stereo rig on top of a car. From these streams, we estimate Structurefrom-Motion (SfM) and scene geometry in real-time. In parallel, we perform multi-view/multi-category object recognition to detect cars and pedestrians in both camera images. Using the SfM self-localization, 2D object detections are converted to 3D observations, which are accumulated in a world coordinate frame. A subsequent tracking module analyzes the resulting 3D observations to find physically plausible spacetime trajectories. Finally, a global optimization criterion takes object-object interactions into account to arrive at accurate 3D localization and trajectory estimates for both cars and pedestrians. We demonstrate the performance of our integrated system on challenging real-world data showing car passages through crowded city areas.
Coupled Detection and Trajectory Estimation for Multi-Object Tracking

We present a novel approach for multi-object tracking which considers object detection and spacetime trajectory estimation as a coupled optimization problem. It is formulated in a hypothesis selection framework and builds upon a state-of-the-art pedestrian detector. At each time instant, it searches for the globally optimal set of spacetime trajectories which provides the best explanation for the current image and for all evidence collected so far, while satisfying the constraints that no two objects may occupy the same physical space, nor explain the same image pixels at any point in time. Successful trajectory hypotheses are fed back to guide object detection in future frames. The optimization procedure is kept efficient through incremental computation and conservative hypothesis pruning. The resulting approach can initialize automatically and track a large and varying number of persons over long periods and through complex scenes with clutter, occlusions, and large-scale background changes. Also, the global optimization framework allows our system to recover from mismatches and temporarily lost tracks. We demonstrate the feasibility of the proposed approach on several challenging video sequences.
Fast 3D Scanning with Automatic Motion Compensation

We present a novel 3D scanning system combining stereo and active illumination based on phase-shift for robust and accurate scene reconstruction. Stereo overcomes the traditional phase discontinuity problem and allows for the reconstruction of complex scenes containing multiple objects. Due to the sequential recording of three patterns, motion will introduce artifacts in the reconstruction. We develop a closed-form expression for the motion error in order to apply motion compensation on a pixel level. The resulting scanning system can capture accurate depth maps of complex dynamic scenes at 17 fps and can cope with both rigid and deformable objects.
Efficient Mining of Frequent and Distinctive Feature Configurations
We present a novel approach to automatically find spatial configurations of local features occurring frequently on instances of a given object class, and rarely on the background. The approach is based on computationally effi- cient data mining techniques and can find frequent con- figurations among tens of thousands of candidates within seconds. Based on the mined configurations we develop a method to select features which have high probability of lying on previously unseen instances of the object class. The technique is meant as an intermediate processing layer to filter the large amount of clutter features returned by lowlevel feature extraction, and hence to facilitate the tasks of higher-level processing stages such as object detection.
Depth and Appearance for Mobile Scene Analysis

In this paper, we address the challenging problem of simultaneous pedestrian detection and ground-plane estimation from video while walking through a busy pedestrian zone. Our proposed system integrates robust stereo depth cues, ground-plane estimation, and appearance-based object detection in a principled fashion using a graphical model. Object-object occlusions lead to complex interactions in this model that make an exact solution computationally intractable. We therefore propose a novel iterative approach that first infers scene geometry using Belief Propagation and then resolves interactions between objects using a global optimization procedure. This approach leads to a robust solution in few iterations, while allowing object detection to benefit from geometry estimation and vice versa. We quantitatively evaluate the performance of our proposed approach on several challenging test sequences showing strolls through busy shopping streets. Comparisons to various baseline systems show that it outperforms both a system using no scene geometry and one just relying on Structure-from-Motion without dense stereo
@InProceedings{eth_biwi_00498,
author = {A. Ess and B. Leibe and L. Van Gool},
title = {Depth and Appearance for Mobile Scene Analysis},
booktitle = {International Conference on Computer Vision (ICCV'07)},
year = {2007},
month = {October},
keywords = {}
}
Depth-from-Recognition: Inferring Meta-data through Cognitive Feedback

Thanks to recent progress in category-level object recognition, we have now come to a point where these techniques have gained sufficient maturity and accuracy to succesfully feed back their output to other processes. This is what we refer to as cognitive feedback. In this paper, we study one particular form of cognitive feedback, where the ability to recognize objects of a given category is exploited to infer meta-data such as depth cues, 3D points, or object decomposition in images of previously unseen object instances. Our approach builds on the Implicit Shape Model of Leibe and Schiele, and extends it to transfer annotations from training images to test images. Experimental results validate the viability of our approach.
Towards Multi-View Object Class Detection
We present a novel system for generic object class de- tection. In contrast to most existing systems which focus on a single viewpoint or aspect, our approach can detect ob- ject instances from arbitrary viewpoints. This is achieved by combining the Implicit Shape Model for object class de- tection proposed by Leibe and Schiele with the multi-view specific object recognition system of Ferrari et al. After learning single-view codebooks, these are inter- connected by so-called activation links, obtained through multi-view region tracks across different training views of individual object instances. During recognition, these inte- grated codebooks work together to determine the location and pose of the object. Experimental results demonstrate the viability of the approach and compare it to a bank of independent single-view detectors.
Multi-Aspect Detection of Articulated Objects
A wide range of methods have been proposed to detect and recognize objects. However, effective and efficient multi- viewpoint detection of objects is still in its infancy, since most current approaches can only handle single viewpoints or as- pects. This paper proposes a general approach for multi- aspect detection of objects. As the running example for de- tection we use pedestrians, which add another difficulty to the problem, namely human body articulations. Global ap- pearance changes caused by different articulations and view- points of pedestrians are handled in a unified manner by a generalization of the Implicit Shape Model [5]. An important property of this new approach is to share local appearance across different articulations and viewpoints, therefore re- quiring relatively few training samples. The effectiveness of the approach is shown and compared to previous approaches on two datasets containing pedestrians with different articu- lations and from multiple viewpoints.
Multiple Object Class Detection with a Generative Model

In this paper we propose an approach capable of si- multaneous recognition and localization of multiple object classes using a generative model. A novel hierarchical rep- resentation allows to represent individual images as well as various objects classes in a single, scale and rotation invari- ant model. The recognition method is based on a codebook representation where appearance clusters built from edge based features are shared among several object classes. A probabilistic model allows for reliable detection of various objects in the same image. The approach is highly effi- cient due to fast clustering and matching methods capable of dealing with millions of high dimensional features. The system shows excellent performance on several object cate- gories over a wide range of scales, in-plane rotations, back- ground clutter, and partial occlusions. The performance of the proposed multi-object class detection approach is com- petitive to state of the art approaches dedicated to a single object class recognition problem.
3D City Modeling Using Cognitive Loops

3D city modeling using computer vision is very chal- lenging. A typical city contains objects which are a night- mare for some vision algorithms, while other algorithms have been designed to identify exactly these parts but, in their turn, suffer from other weaknesses which limit their application. For instance, moving cars with metallic sur- faces can degrade the results of a 3D city reconstruction algorithm which is primarily based on the assumption of a static scene with diffuse reflection properties. On the other hand, a specialized object recognition algorithm could be able to detect cars, but also yields too many false positives without the availability of additional scene knowledge. In this paper, the design of a cognitive loop which intertwines both aforementioned algorithms is demonstrated for 3D city modeling, proving that the whole can be much more than the simple sum of its parts. A cognitive loop is the mutual trans- fer of higher knowledge between algorithms, which enables the combination of algorithms to overcome the weaknesses of any single algorithm. We demonstrate the promise of this approach on a real-world city modeling task using video data recorded by a survey vehicle. Our results show that the cognitive combination of algorithms delivers convincing city models which improve upon the degree of realism that is possible from a purely reconstruction-based approach.
Efficient Clustering and Matching for Object Class Recognition
In this paper we address the problem of building object class representations based on local features and fast matching in a large database. We propose an efficient algorithm for hierarchical agglomerative clustering. We examine different agglomerative and partitional clustering strategies and compare the quality of obtained clusters. Our combination of partitional-agglomerative clustering gives significant improvement in terms of efficiency while main- taining the same quality of clusters. We also propose a method for building data structures for fast matching in high dimensional feature spaces. These improvements allow to deal with large sets of training data typically used in recognition of multiple object classes.
Segmentation Based Multi-Cue Integration for Object Detection

This paper proposes a novel method for integrating multiple local cues, i.e. lo- cal region detectors as well as descriptors, in the context of object detection. Rather than to fuse the outputs of several distinct classifiers in a fixed setup, our approach implements a highly flexible combination scheme, where the con- tributions of all individual cues are flexibly recombined depending on their ex- planatory power for each new test image. The key idea behind our approach is to integrate the cues over an estimated top-down segmentation, which allows to quantify how much each of them contributed to the object hypothesis. By combining those contributions on a per-pixel level, our approach ensures that each cue only contributes to object regions for which it is confident and that potential correlations between cues are effectively factored out. Experimental results on several benchmark data sets show that the proposed multi-cue combi- nation scheme significantly increases detection performance compared to any of its constituent cues alone. Moreover, it provides an interesting evaluation tool to analyze the complementarity of local feature detectors and descriptors.
Integrating Recognition and Reconstruction for Cognitive Traffic Scene Analysis from a Moving Vehicle

This paper presents a practical system for vision-based traffic scene analysis from a moving vehicle based on a cognitive feedback loop which in- tegrates real-time geometry estimation with appearance-based object detection. We demonstrate how those two components can benefit from each other’s con- tinuous input and how the transferred knowledge can be used to improve scene analysis. Thus, scene interpretation is not left as a matter of logical reasoning, but is instead addressed by the repeated interaction and consistency checks between different levels and modes of visual processing. As our results show, the proposed tight integration significantly increases recognition performance, as well as over- all system robustness. In addition, it enables the construction of novel capabilities such as the accurate 3D estimation of object locations and orientations and their temporal integration in a world coordinate frame. The system is evaluated on a challenging real-world car detection task in an urban scenario.
Pedestrian Detection in Crowded Scenes

In this paper, we address the problem of detecting pedestrians in crowded real-world scenes with severe overlaps. Our basic premise is that this problem is too difficult for any type of model or feature alone. Instead, we present a novel algorithm that integrates evidence in multiple iterations and from different sources. The core part of our method is the combination of local and global cues via a probabilistic top-down segmentation. Altogether, this approach allows to examine and compare object hypotheses with high precision down to the pixel level. Qualitative and quantitative results on a large data set confirm that our method is able to reliably detect pedestrians in crowded scenes, even when they overlap and partially occlude each other. In addition, the flexible nature of our approach allows it to operate on very small training sets.
An Evaluation of Local Shape-Based Features for Pedestrian Detection

Pedestrian detection in real world scenes is a challenging problem. In recent years a variety of approaches have been proposed, and impressive results have been reported on a variety of databases. This paper systematically evaluates (1) various local shape descriptors, namely Shape Context and Local Chamfer descriptor and (2) four different interest point detectors for the detection of pedestrians. Those results are compared to the standard global Chamfer matching approach. A main result of the paper is that Shape Context trained on real edge images rather than on clean pedestrian silhouettes combined with the Hessian-Laplace detector outperforms all other tested approaches.
Local Features for Object Class Recognition
In this paper we compare the performance of local detectors and descriptors in the context of object class recognition. Recently, many detectors / descriptors have been evaluated in the context of matching as well as invariance to viewpoint changes [20]. However, it is unclear if these results can be generalized to categorization problems, which require different properties of features. We evaluate 5 stateof-the-art scale invariant region detectors and 5 descriptors. Local features are computed for 20 object classes and clustered using hierarchical agglomerative clustering. We measure the quality of appearance clusters and location distributions using entropy as well as precision. We also measure how the clusters generalize from training set to novel test data. Our results indicate that extended SIFT descriptors [22] computed on Hessian-Laplace [20] regions perform best. Second score is obtained by Salient regions [11]. The results also show that these two detectors provide complementary features. The new detectors/descriptors significantly improve the performance of a state-of-the art recognition approach [16] in pedestrian detection task.
Integrating Representative and Discriminant Models for Object Category Detection
Category detection is a lively area of research. While categorization algorithms tend to agree in using local descriptors, they differ in the choice of the classifier, with some using generative models and others discriminative approaches. This paper presents a method for object category detection which integrates a generative model with a discriminative classifier. For each object category, we generate an appearance codebook, which becomes a common vocabulary for the generative and discriminative methods. Given a query image, the generative part of the algorithm finds a set of hypotheses and estimates their support in location and scale. Then, the discriminative part verifies each hypothesis on the same codebook activations. The new algorithm exploits the strengths of both original methods, minimizing their weaknesses. Experiments on several databases show that our new approach performs better than its building blocks taken separately. Moreover, experiments on two challenging multi-scale databases show that our new algorithm outperforms previously reported results.
Combined Object Categorization and Segmentation with an Implicit Shape Model

We present a method for object categorization in real-world scenes. Following a common consensus in the field, we do not assume that a figureground segmentation is available prior to recognition. However, in contrast to most standard approaches for object class recognition, our approach automatically segments the object as a result of the categorization. This combination of recognition and segmentation into one process is made possible by our use of an Implicit Shape Model, which integrates both into a common probabilistic framework. In addition to the recognition and segmentation result, it also generates a per-pixel confidence measure specifying the area that supports a hypothesis and how much it can be trusted. We use this confidence to derive a natural extension of the approach to handle multiple objects in a scene and resolve ambiguities between overlapping hypotheses with a novel MDL-based criterion. In addition, we present an extensive evaluation of our method on a standard dataset for car detection and compare its performance to existing methods from the literature. Our results show that the proposed method significantly outperforms previously published methods while needing one order of magnitude less training examples. Finally, we present results for articulated objects, which show that the proposed method can categorize and segment unfamiliar objects in different articulations and with widely varying texture patterns, even under significant partial occlusion.
Scale Invariant Object Categorization Using a Scale-Adaptive Mean-Shift Search

The goal of our work is object categorization in real-world scenes. That is, given a novel image we want to recognize and localize unseen-before objects based on their similarity to a learned object category. For use in a realworld system, it is important that this includes the ability to recognize objects at multiple scales. In this paper, we present an approach to multi-scale object categorization using scale-invariant interest points and a scale-adaptive Mean-Shift search. The approach builds on the method from [12], which has been demonstrated to achieve excellent results for the single-scale case, and extends it to multiple scales. We present an experimental comparison of the influence of different interest point operators and quantitatively show the method’s robustness to large scale changes.
Awarded the main prize of the German Pattern Recognition Society (DAGM Best Paper Award)
Interleaved Object Categorization and Segmentation
This thesis is concerned with the problem of visual object categorization, that is of recognizing unseen-before objects, localizing them in cluttered real-world images, and assigning the correct category label. This capability is one of the core competencies of the human visual system. Yet, computer vision systems are still far from reaching a comparable level of performance. Moreover, computer vision research has in the past mainly focused on the simpler and more specific problem of identifying known objects under novel viewing conditions. The visual categorization problem is closely linked to the task of figure-ground segmentation, that is of dividing the image into an object and a non-object part. Historically, figure-ground segmentation has often been seen as an important and even necessary preprocessing step for object recognition. However, purely bottomup approaches have so far been unable to yield segmentations of sufficient quality, so that most current recognition approaches have been designed to work independently from segmentation. In contrast, this thesis considers object categorization and figure-ground segmentation as two interleaved processes that closely collaborate towards a common goal. The core part of our work is a probabilistic formulation which integrates both capabilities into a common framework. As shown in our experiments, the tight coupling between those two processes allows them to profit from each other and improve their individual performances. The resulting approach can detect categorical objects in novel images and automatically compute a segmentation for them. This segmentation is then used to again improve recognition by allowing the system to focus its effort on object pixels and discard misleading influences from the background. In addition to improving the recognition performance for individual hypotheses, the top-down segmentation also allows to determine exactly from where a hypothesis draws its support. We use this information to design a hypothesis verification stage based on the MDL principle that resolves ambiguities between overlapping hypotheses on a per-pixel level and factors out the effects of partial occlusion. Altogether, this procedure constitutes a novel mechanism in object detection that allows to analyze scenes containing multiple objects in a principled manner. Our results show that it presents an improvement over conventional criteria based on bounding box overlap and permits more accurate acceptance decisions. Our approach is based on a highly flexible implicit representation for object shape that can combine the information of local parts observed on different training examples and interpolate between the corresponding objects. As a result, the proposed method can learn object models already from few training examples and achieve competitive object detection performance with training sets that are between one and two orders of magnitude smaller than those used in comparable systems. An extensive evaluation on several large data sets shows that the system is applicable to many different object categories, including both rigid and articulated objects.
Analyzing Contour and Appearance Based Methods for Object Categorization

Object recognition has reached a level where we can identify a large number of previously seen and known objects. However, the more challenging and important task of categorizing previously unseen objects remains largely unsolved. Traditionally, contour and shape based methods are regarded most adequate for handling the generalization requirements needed for this task. Appearance based methods, on the other hand, have been successful in object identification and detection scenarios. Today little work is done to systematically compare existing methods and characterize their relative capabilities for categorizing objects. In order to compare different methods we present a new database specifically tailored to the task of object categorization. It contains high-resolution color images of 80 objects from 8 different categories, for a total of 3280 images. It is used to analyze the performance of several appearance and contour based methods. The best categorization result is obtained by an appropriate combination of different methods.
On-line Face Tracking Using a Feature-Driven Level Set
An efficient and general framework for the incorporation of statistical prior information, based on a wide variety of detectable point features, into level set based object tracking is presented. Level set evolution is based on the maximisation of a set of likelihoods on mesh values at features, which are located using a stochastic sampling process. This evolution is based on the interpolation of likelihood gradients using kernels centred at the features. Feature detectors implemented are based on moments of colour histogram segmented images and learned image patches located using normalised correlation, although a wide variety of feature detectors could be used. A computationally efficient level set implementation is presented along with a method for the incorporation of a motion model into the scheme.
Interleaved Object Categorization and Segmentation
Historically, figure-ground segmentation has been seen as an important and even necessary precursor for object recognition. In that context, segmentation is mostly defined as a data driven, that is bottom-up, process. As for humans object recognition and segmentation are heavily intertwined processes, it has been argued that top-down knowledge from object recognition can and should be used for guiding the segmentation process. In this paper, we present a method for the categorization of unfamiliar objects in difficult real-world scenes. The method generates object hypotheses without prior segmentation that can be used to obtain a category-specific figure-ground segmentation. In particular, the proposed approach uses a probabilistic formulation to incorporate knowledge about the recognized category as well as the supporting information in the image to segment the object from the background. This segmentation can then be used for hypothesis verification, to further improve recognition performance. Experimental results show the capacity of the approach to categorize and segment object categories as diverse as cars and cows.
Saliency of Interest Points under Scale Changes
Interest point detectors are commonly employed to reduce the amount of data to be processed. The ideal interest point detector would robustly select those features which are most appropriate or salient for the application and data at hand. There is however a tradeoff between the robustness and the discriminance of the selected features. Whereas robustness in terms of repeatability is relatively well explored, the discriminance of interest points is rarely discussed. This paper formalizes the notion of saliency and evaluates three state-of-the-art interest point detectors with respect to their capability of selecting salient image features in two recognition settings.
@inproceedings{hall2002saliency,
title={{Saliency of Interest Points under Scale Changes.}},
author={{Hall, Daniela and Leibe, Bastian and Schiele, Bernt}},
booktitle={{BMVC}},
pages={1--10},
year={2002}
}
Computer Vision-Based Gesture Tracking, Object Tracking, and 3D Reconstruction for Augmented Desks
The Perceptive Workbench endeavors to create a spontaneous and unimpeded interface between the physical and virtual worlds. Its vision-based methods for interaction constitute an alternative to wired input devices and tethered tracking. Objects are recognized and tracked when placed on the display surface. By using multiple infrared light sources, the object’s 3D shape can be captured and inserted into the virtual interface. This ability permits spontaneity since either preloaded objects or those objects selected at run-time by the user can become physical icons. Integrated into the same vision-based interface is the ability to identify 3D hand position, pointing direction, and sweeping arm gestures. Such gestures can enhance selection, manipulation, and navigation tasks. The Perceptive Workbench has been used for a variety of applications, including augmented reality gaming and terrain navigation. This paper focuses on the techniques used in implementing the Perceptive Workbench and the system’s performance.
@article{starner2003perceptive,
title={{Computer Vision-Based Gesture Tracking, Object Tracking, and 3D Reconstruction for Augmented Desks}},
author={{Starner, Thad and Leibe, Bastian and Minnen, David and Westyn, Tracy and Hurst, Amy and Weeks, Justin}},
journal={{Machine Vision and Applications}},
volume={14},
number={1},
pages={59--71},
year={2003},
publisher={Springer}
}
3D Object Recognition from Range Images using Local Feature Histograms

This paper explores a view-based approach to recognize free-form objects in range images. We are using a set of local features that are easy to calculate and robust to partial occlusions. By combining those features in a multidimensional histogram, we can obtain highly discriminant classifiers without the need for segmentation. Recognition is performed using either histogram matching or a probabilistic recognition algorithm. We compare the performance of both methods in the presence of occlusions and test the system on a database of almost 2000 full-sphere views of 30 free-form objects. The system achieves a recognition accuracy above 93% on ideal images, and of 89% with 20% occlusion.
@inproceedings{hetzel20013d,
title={3D Object Recognition from Range Images using Local Feature Histograms}},
author={{Hetzel, G{\"u}nter and Leibe, Bastian and Levi, Paul and Schiele, Bernt}},
booktitle={{Computer Vision and Pattern Recognition, 2001. CVPR 2001. Proceedings of the 2001 IEEE Computer Society Conference on}},
volume={2},
pages={II--394},
year={2001},
organization={IEEE}
}
Local Feature Histograms for Object Recognition from Range Images
In this paper, we explore the use of local feature histograms for view-based recognition of free-form objects from range images. Our approach uses a set of local features that are easy to calculate and robust to partial occlusions. By combining them in a multidimensional histogram, we can obtain highly discriminative classi ers without having to solve a segmentation problem. The system achieves above 91% recognition accuracy on a database of almost 2000 full-sphere views of 30 free-form objects, with only minimal space requirements. In addition, since it only requires the calculation of very simple features, it is ex- tremely fast and can achieve real-time recognition performance.
@article{leibe2001local,
title={Local feature histograms for object recognition from range images},
author={Leibe, Bastian and Hetzel, G{\"u}nter and Levi, Paul},
year={2001}
}
Integration of Wireless Gesture Tracking, Object Tracking, and 3D Reconstruction in the Perceptive Workbench

The Perceptive Workbench endeavors to create a spontaneous and unimpeded interface between the physical and virtual worlds. Its vision-based methods for interaction constitute an alternative to wired input devices and tethered tracking. Objects are recognized and tracked when placed on the display surface. By using multiple infrared light sources, the object’s 3D shape can be captured and inserted into the virtual interface. This ability permits spontaneity since either preloaded objects or those objects selected at run-time by the user can become physical icons. Integrated into the same vision-based interface is the ability to identify 3D hand position, pointing direction, and sweeping arm gestures. Such gestures can enhance selection, manipulation, and navigation tasks. In previous publications, the Perceptive Workbench has demonstrated its utility for a variety of applications, including augmented reality gaming and terrain navigation. This paper will focus on the implementation and performance aspects and will introduce recent enhancements to the system.
@incollection{leibe2001integration,
title={{Integration of Wireless Gesture Tracking, Object Tracking, and 3D Reconstruction in the Perceptive Workbench}},
author={{Leibe, Bastian and Minnen, David and Weeks, Justin and Starner, Thad}},
booktitle={{Computer Vision Systems}},
pages={73--92},
year={2001},
publisher={Springer}
}
Toward Spontaneous Interaction with the Perceptive Workbench
Until now, we have interacted with computers mostly by using wire-based devices. Typically, the wires limit the distance of movement and inhibit freedom of orientation. In addition, most interactions are indirect. The user moves a device as an analog for the action created in the display space. We envision an untethered interface that accepts gestures directly and can accept any objects we choose as interactors. We discuss methods for producing more seamless interaction between the physical and virtual environments through the Perceptive Workbench. We applied the system to an augmented reality game and a terrain navigating system. The Perceptive Workbench can reconstruct 3D virtual representations of previously unseen real-world objects placed on its surface. In addition, the Perceptive Workbench identifies and tracks such objects as they are manipulated on the desk's surface and allows the user to interact with the augmented environment through 2D and 3D gestures
@article{leibe2000toward,
title={{Toward Spontaneous Interaction with the Perceptive Workbench}},
author={{Leibe, Bastian and Starner, Thad and Ribarsky, William and Wartell, Zachary and Krum, David and Weeks, Justin and Singletary, Bradley and Hedges, L},
journal={{Computer Graphics and Applications, IEEE}},
volume={20},
number={6},
pages={54--65},
year={2000},
publisher={IEEE}
}
The Perceptive Workbench: Toward Spontaneous Interaction in Semi-Immersive Virtual Environments
The Perceptive Workbench enables a spontaneous, natural, and unimpeded interface between the physical and virtual worlds. It uses vision-based methods for interaction that eliminate the need for wired input devices and wired tracking. Objects are recognized and tracked when placed on the display surface. Through the use of multiple light sources, the objectÕs 3D shape can be captured and inserted into the virtual interface. This ability permits spontaneity since either preloaded objects or those objects selected on the spot by the user can become physical icons. Integrated into the same vision-based interface is the ability to identify 3D hand position, pointing direction, and sweeping arm gestures. Such gestures can enhance selection, manipulation, and navigation tasks. In this paper, the Perceptive Workbench is used for augmented reality gaming and terrain navigation applications, which demonstrate the utility and capability of the interface.
@inproceedings{leibe2000perceptive,
title={{The Perceptive Workbench: Toward Spontaneous Interaction in Semi-Immersive Virtual Environments}},
author={{Leibe, Bastian and Starner, Thad and Ribarsky, William and Wartell, Zachary and Krum, David and Singletary, Brad and Hodges, Larry}},
booktitle={{Natural Interaction in Semi Immersive Virtual Environments, in Proceedings of IEEE Virtual Reality 2000}},
year={2000},
organization={Citeseer}
}
MIND-WARPING: Towards Creating a Compelling Collaborative Augmented Reality Game

Computer gaming offers a unique test-bed and market for advanced concepts in computer science, such as Human Computer Interaction (HCI), computer-supported collaborative work (CSCW), intelligent agents, graphics, and sensing technology. In addition, computer gaming is especially wellsuited for explorations in the relatively young fields of wearable computing and augmented reality (AR). This paper presents a developing multi-player augmented reality game, patterned as a cross between a martial arts fighting game and an agent controller, as implemented using the Wearable Augmented Reality for Personal, Intelligent, and Networked Gaming (WARPING) system. Through interactions based on gesture, voice, and head movement input and audio and graphical output, the WARPING system demonstrates how computer vision techniques can be exploited for advanced, intelligent interfaces.
@inproceedings{starner2000mind,
title={{MIND-WARPING: towards creating a compelling collaborative augmented reality game}},
author={{Starner, Thad and Leibe, Bastian and Singletary, Brad and Pair, Jarrell}},
booktitle={{Proceedings of the 5th international conference on Intelligent user interfaces}},
pages={256--259},
year={2000},
organization={ACM}
}
