
Profile

|
My research focus is on the intersection of Computer Vision, Mobile Robotics and Machine Learning. In particular, I am interested in multi-object tracking, segmentation, and learning-in-the-wild from unlabeled video in mobile robotics scenarios. Sport/traveling/coffee/beer enthusiast.
Successfully defended my thesis on June 27, 2019 and now continuing doing cool stuff at TUM in Dynamic Vision and Learning Group with Prof. Dr. Laura Leal-Taixé!
Teaching
- Machine Learning, WS2013
- Computer Vision, WS2014
- Machine Learning, SS2016
Students (Master Theses)
- Deyvid Kochanov paper
- Dirk Klostermann paper
- Alina Shigabutdinova
- Kilian Merkelbach
- Johannes Gross paper
Reviewer for
- CVPR, ICRA, IROS, ECCV, ICCV, IJCV, RSS, RAL, GCPR
You can find some cool stuff on my GitHub
Publications
Opening up Open World Tracking

Tracking and detecting any object, including ones never-seen-before during model training, is a crucial but elusive capability of autonomous systems. An autonomous agent that is blind to never-seen-before objects poses a safety hazard when operating in the real world and yet this is how almost all current systems work. One of the main obstacles towards advancing tracking any object is that this task is notoriously difficult to evaluate. A benchmark that would allow us to perform an apples-to-apples comparison of existing efforts is a crucial first step towards advancing this important research field. This paper addresses this evaluation deficit and lays out the landscape and evaluation methodology for detecting and tracking both known and unknown objects in the open-world setting. We propose a new benchmark, TAO-OW: Tracking Any Object in an Open World}, analyze existing efforts in multi-object tracking, and construct a baseline for this task while highlighting future challenges. We hope to open a new front in multi-object tracking research that will hopefully bring us a step closer to intelligent systems that can operate safely in the real world.
@inproceedings{liu2022opening,
title={Opening up Open-World Tracking},
author={Liu, Yang and Zulfikar, Idil Esen and Luiten, Jonathon and Dave, Achal and Ramanan, Deva and Leibe, Bastian and O{\v{s}}ep, Aljo{\v{s}}a and Leal-Taix{\'e}, Laura},
journal={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2022}
}
HOTA: A Higher Order Metric for Evaluating Multi-object Tracking
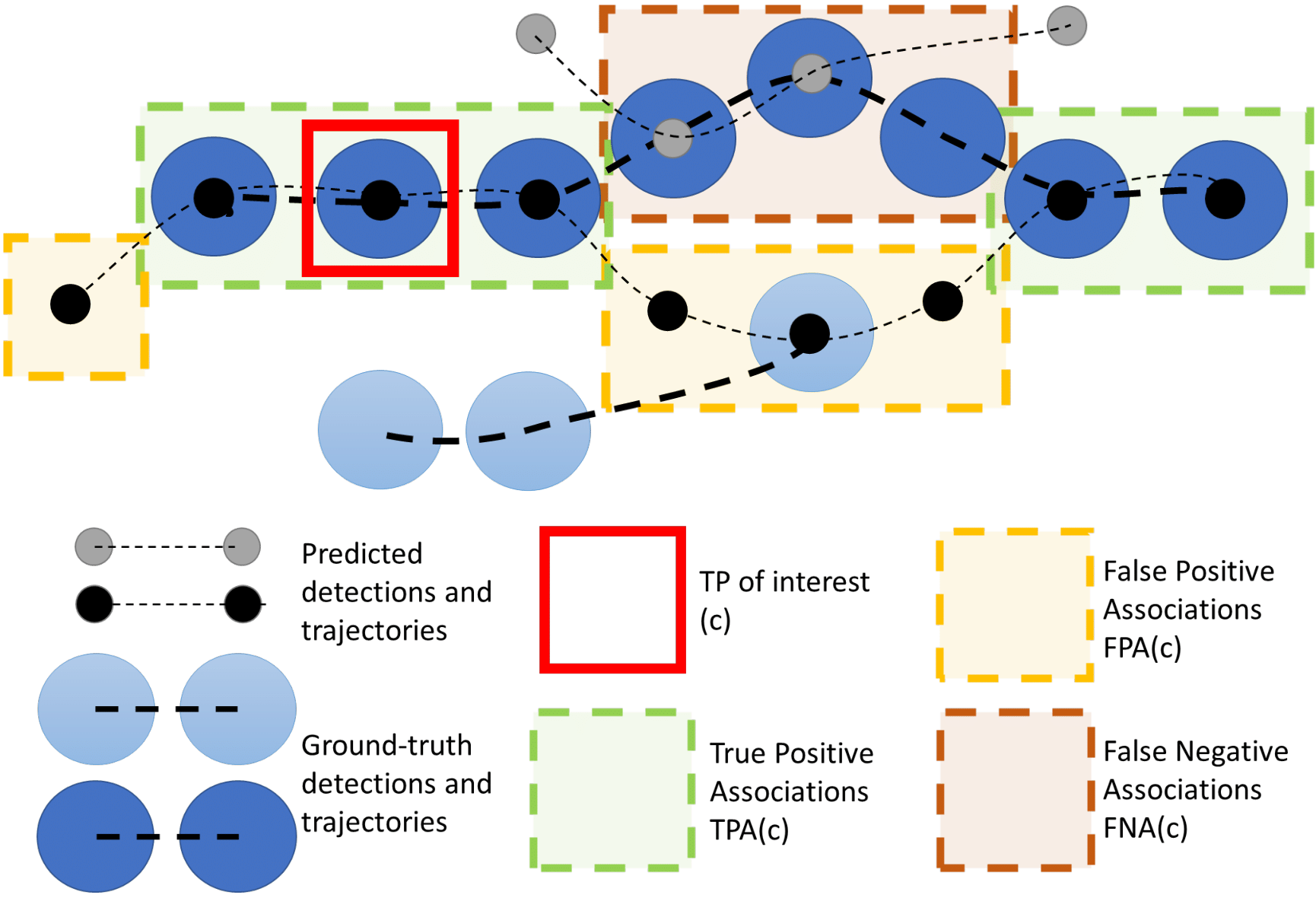
Multi-object tracking (MOT) has been notoriously difficult to evaluate. Previous metrics overemphasize the importance of either detection or association. To address this, we present a novel MOT evaluation metric, higher order tracking accuracy (HOTA), which explicitly balances the effect of performing accurate detection, association and localization into a single unified metric for comparing trackers. HOTA decomposes into a family of sub-metrics which are able to evaluate each of five basic error types separately, which enables clear analysis of tracking performance. We evaluate the effectiveness of HOTA on the MOTChallenge benchmark, and show that it is able to capture important aspects of MOT performance not previously taken into account by established metrics. Furthermore, we show HOTA scores better align with human visual evaluation of tracking performance.
@article{luiten2020IJCV,
title={HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking},
author={Luiten, Jonathon and Osep, Aljosa and Dendorfer, Patrick and Torr, Philip and Geiger, Andreas and Leal-Taix{\'e}, Laura and Leibe, Bastian},
journal={International Journal of Computer Vision},
pages={1--31},
year={2020},
publisher={Springer}
}
STEm-Seg: Spatio-temporal Embeddings for Instance Segmentation in Videos

Existing methods for instance segmentation in videos typically involve multi-stage pipelines that follow the tracking-by-detection paradigm and model a video clip as a sequence of images. Multiple networks are used to detect objects in individual frames, and then associate these detections over time. Hence, these methods are often non-end-to-end trainable and highly tailored to specific tasks. In this paper, we propose a different approach that is well-suited to a variety of tasks involving instance segmentation in videos. In particular, we model a video clip as a single 3D spatio-temporal volume, and propose a novel approach that segments and tracks instances across space and time in a single stage. Our problem formulation is centered around the idea of spatio-temporal embeddings which are trained to cluster pixels belonging to a specific object instance over an entire video clip. To this end, we introduce (i) novel mixing functions that enhance the feature representation of spatio-temporal embeddings, and (ii) a single-stage, proposal-free network that can reason about temporal context. Our network is trained end-to-end to learn spatio-temporal embeddings as well as parameters required to cluster these embeddings, thus simplifying inference. Our method achieves state-of-the-art results across multiple datasets and tasks.
» Show BibTeX
@inproceedings{AtharMahadevan20ECCV,
title={STEm-Seg: Spatio-temporal Embeddings for Instance Segmentation in Videos},
author={Athar, Ali and Mahadevan, Sabarinath and O{\v{s}}ep, Aljo{\v{s}}a and Leal-Taix{\'e}, Laura and Leibe, Bastian},
booktitle=ECCV,
year={2020}
}
Making a Case for 3D Convolutions for Object Segmentation in Videos

The task of object segmentation in videos is usually accomplished by processing appearance and motion information separately using standard 2D convolutional networks, followed by a learned fusion of the two sources of information. On the other hand, 3D convolutional networks have been successfully applied for video classification tasks, but have not been leveraged as effectively to problems involving dense per-pixel interpretation of videos compared to their 2D convolutional counterparts and lag behind the aforementioned networks in terms of performance. In this work, we show that 3D CNNs can be effectively applied to dense video prediction tasks such as salient object segmentation. We propose a simple yet effective encoder-decoder network architecture consisting entirely of 3D convolutions that can be trained end-to-end using a standard cross-entropy loss. To this end, we leverage an efficient 3D encoder, and propose a 3D decoder architecture, that comprises novel 3D Global Convolution layers and 3D Refinement modules. Our approach outperforms existing state-of-the-arts by a large margin on the DAVIS'16 Unsupervised, FBMS and ViSal dataset benchmarks in addition to being faster, thus showing that our architecture can efficiently learn expressive spatio-temporal features and produce high quality video segmentation masks.
» Show BibTeX
@inproceedings{Mahadevan20BMVC,
title={Making a Case for 3D Convolutions for Object Segmentation in Videos},
author={Mahadevan, Sabarinath and Athar, Ali and O{\v{s}}ep, Aljo{\v{s}}a and Hennen, Sebastian and Leal-Taix{\'e}, Laura and Leibe, Bastian},
booktitle={BMVC},
year={2020}
}
MOTS: Multi-Object Tracking and Segmentation

This paper extends the popular task of multi-object tracking to multi-object tracking and segmentation (MOTS). Towards this goal, we create dense pixel-level annotations for two existing tracking datasets using a semi-automatic annotation procedure. Our new annotations comprise 65,213 pixel masks for 977 distinct objects (cars and pedestrians) in 10,870 video frames. For evaluation, we extend existing multi-object tracking metrics to this new task. Moreover, we propose a new baseline method which jointly addresses detection, tracking, and segmentation with a single convolutional network. We demonstrate the value of our datasets by achieving improvements in performance when training on MOTS annotations. We believe that our datasets, metrics and baseline will become a valuable resource towards developing multi-object tracking approaches that go beyond 2D bounding boxes. We make our annotations, code, and models available at https://www.vision.rwth-aachen.de/page/mots.
» Show BibTeX
@inproceedings{Voigtlaender19CVPR_MOTS,
author = {Paul Voigtlaender and Michael Krause and Aljo\u{s}a O\u{s}ep and Jonathon Luiten and Berin Balachandar Gnana Sekar and Andreas Geiger and Bastian Leibe},
title = {{MOTS}: Multi-Object Tracking and Segmentation},
booktitle = {CVPR},
year = {2019},
}
AlignNet-3D: Fast Point Cloud Registration of Partially Observed Objects

Methods tackling multi-object tracking need to estimate the number of targets in the sensing area as well as to estimate their continuous state. While the majority of existing methods focus on data association, precise state (3D pose) estimation is often only coarsely estimated by approximating targets with centroids or (3D) bounding boxes. However, in automotive scenarios, motion perception of surrounding agents is critical and inaccuracies in the vehicle close-range can have catastrophic consequences. In this work, we focus on precise 3D track state estimation and propose a learning-based approach for object-centric relative motion estimation of partially observed objects. Instead of approximating targets with their centroids, our approach is capable of utilizing noisy 3D point segments of objects to estimate their motion. To that end, we propose a simple, yet effective and efficient network, AlignNet-3D, that learns to align point clouds. Our evaluation on two different datasets demonstrates that our method outperforms computationally expensive, global 3D registration methods while being significantly more efficient.
@inproceedings{Gross193DV,
title = {AlignNet-3D: Fast Point Cloud Registration of Partially Observed Objects},
author = {Johannes Gro\ss and Aljo\v{s}a O\v{s}ep and Bastian Leibe},
booktitle = {International Conference on 3D Vision {(3DV)}},
year = {2019}
}
Large-Scale Object Mining for Object Discovery from Unlabeled Video
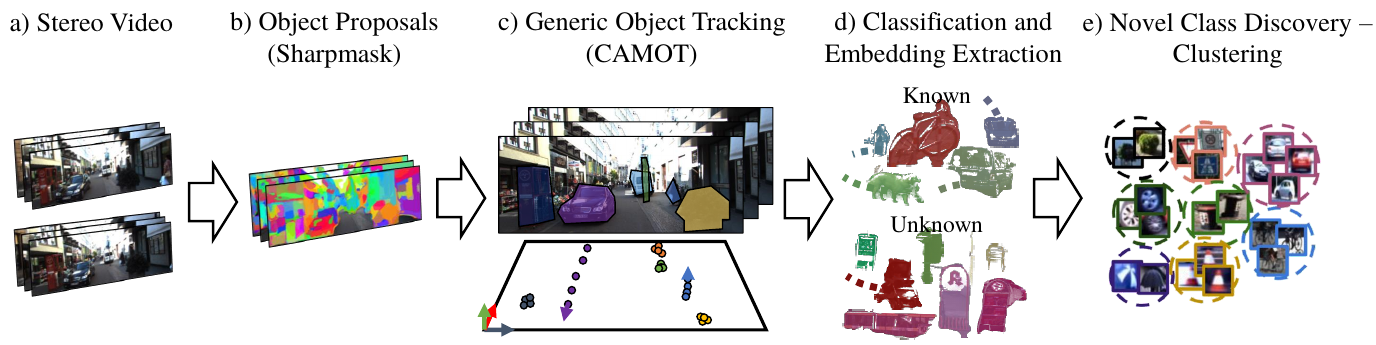
This paper addresses the problem of object discovery from unlabeled driving videos captured in a realistic automotive setting. Identifying recurring object categories in such raw video streams is a very challenging problem. Not only do object candidates first have to be localized in the input images, but many interesting object categories occur relatively infrequently. Object discovery will therefore have to deal with the difficulties of operating in the long tail of the object distribution. We demonstrate the feasibility of performing fully automatic object discovery in such a setting by mining object tracks using a generic object tracker. In order to facilitate further research in object discovery, we will release a collection of more than 360'000 automatically mined object tracks from 10+ hours of video data (560'000 frames). We use this dataset to evaluate the suitability of different feature representations and clustering strategies for object discovery.
@article{Osep19ICRA,
author = {O\v{s}ep, Aljo\v{s}a and Voigtlaender, Paul and Luiten, Jonathon and Breuers, Stefan and Leibe, Bastian},
title = {Large-Scale Object Mining for Object Discovery from Unlabeled Video},
journal = {ICRA},
year = {2019}
}
4D Generic Video Object Proposals

Many high-level video understanding methods require input in the form of object proposals. Currently, such proposals are predominantly generated with the help of networks that were trained for detecting and segmenting a set of known object classes, which limits their applicability to cases where all objects of interest are represented in the training set. This is a restriction for automotive scenarios, where unknown objects can frequently occur. We propose an approach that can reliably extract spatio-temporal object proposals for both known and unknown object categories from stereo video. Our 4D Generic Video Tubes (4D-GVT) method leverages motion cues, stereo data, and object instance segmentation to compute a compact set of video-object proposals that precisely localizes object candidates and their contours in 3D space and time. We show that given only a small amount of labeled data, our 4D-GVT proposal generator generalizes well to real-world scenarios, in which unknown categories appear. It outperforms other approaches that try to detect as many objects as possible by increasing the number of classes in the training set to several thousand.
@inproceedings{Osep19ICRA,
author = {O\v{s}ep, Aljo\v{s}a and Voigtlaender, Paul and Weber, Mark and Luiten, Jonathon and Leibe, Bastian},
title = {4D Generic Video Object Proposals},
booktitle = {ICRA},
year = {2020}
}
Track, then Decide: Category-Agnostic Vision-based Multi-Object Tracking

The most common paradigm for vision-based multi-object tracking is tracking-by-detection, due to the availability of reliable detectors for several important object categories such as cars and pedestrians. However, future mobile systems will need a capability to cope with rich human-made environments, in which obtaining detectors for every possible object category would be infeasible. In this paper, we propose a model-free multi-object tracking approach that uses a category-agnostic image segmentation method to track objects. We present an efficient segmentation mask-based tracker which associates pixel-precise masks reported by the segmentation. Our approach can utilize semantic information whenever it is available for classifying objects at the track level, while retaining the capability to track generic unknown objects in the absence of such information. We demonstrate experimentally that our approach achieves performance comparable to state-of-the-art tracking-by-detection methods for popular object categories such as cars and pedestrians. Additionally, we show that the proposed method can discover and robustly track a large variety of other objects.
@article{Osep18ICRA,
author = {O\v{s}ep, Aljo\v{s}a and Mehner, Wolfgang and Voigtlaender, Paul and Leibe, Bastian},
title = {Track, then Decide: Category-Agnostic Vision-based Multi-Object Tracking},
journal = {ICRA},
year = {2018}
}
Towards Large-Scale Video Video Object Mining
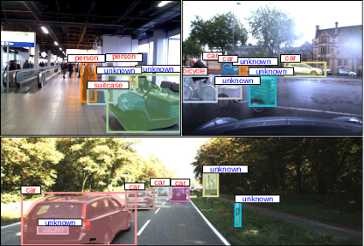
We propose to leverage a generic object tracker in order to perform object mining in large-scale unlabeled videos, captured in a realistic automotive setting. We present a dataset of more than 360'000 automatically mined object tracks from 10+ hours of video data (560'000 frames) and propose a method for automated novel category discovery and detector learning. In addition, we show preliminary results on using the mined tracks for object detector adaptation.
@article{OsepVoigtlaender18ECCVW,
title={Towards Large-Scale Video Object Mining},
author={Aljo\v{s}a O\v{s}ep and Paul Voigtlaender and Jonathon Luiten and Stefan Breuers and Bastian Leibe},
journal={ECCV 2018 Workshop on Interactive and Adaptive Learning in an Open World},
year={2018}
}
Large-Scale Object Discovery and Detector Adaptation from Unlabeled Video
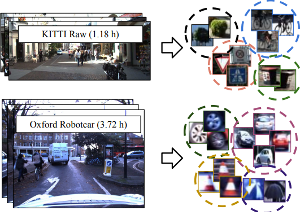
We explore object discovery and detector adaptation based on unlabeled video sequences captured from a mobile platform. We propose a fully automatic approach for object mining from video which builds upon a generic object tracking approach. By applying this method to three large video datasets from autonomous driving and mobile robotics scenarios, we demonstrate its robustness and generality. Based on the object mining results, we propose a novel approach for unsupervised object discovery by appearance-based clustering. We show that this approach successfully discovers interesting objects relevant to driving scenarios. In addition, we perform self-supervised detector adaptation in order to improve detection performance on the KITTI dataset for existing categories. Our approach has direct relevance for enabling large-scale object learning for autonomous driving.
@article{OsepVoigtlaender18arxiv,
title={Large-Scale Object Discovery and Detector Adaptation from Unlabeled Video},
author={Aljo\v{s}a O\v{s}ep and Paul Voigtlaender and Jonathon Luiten and Stefan Breuers and Bastian Leibe},
journal={arXiv preprint arXiv:1712.08832},
year={2018}
}
Combined Image- and World-Space Tracking in Traffic Scenes

Tracking in urban street scenes plays a central role in autonomous systems such as self-driving cars. Most of the current vision-based tracking methods perform tracking in the image domain. Other approaches, e.g. based on LIDAR and radar, track purely in 3D. While some vision-based tracking methods invoke 3D information in parts of their pipeline, and some 3D-based methods utilize image-based information in components of their approach, we propose to use image- and world-space information jointly throughout our method. We present our tracking pipeline as a 3D extension of image-based tracking. From enhancing the detections with 3D measurements to the reported positions of every tracked object, we use world- space 3D information at every stage of processing. We accomplish this by our novel coupled 2D-3D Kalman filter, combined with a conceptually clean and extendable hypothesize-and-select framework. Our approach matches the current state-of-the-art on the official KITTI benchmark, which performs evaluation in the 2D image domain only. Further experiments show significant improvements in 3D localization precision by enabling our coupled 2D-3D tracking.
@inproceedings{Osep17ICRA,
title={Combined Image- and World-Space Tracking in Traffic Scenes},
author={O\v{s}ep, Aljo\v{s}a and Mehner, Wolfgang and Mathias, Markus and Leibe, Bastian},
booktitle={ICRA},
year={2017}
}
Unsupervised Learning of Shape-Motion Patterns for Objects in Urban Street Scenes
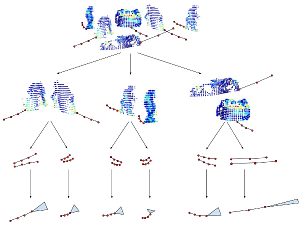
Tracking in urban street scenes is predominantly based on pretrained object-specific detectors and Kalman filter based tracking. More recently, methods have been proposed that track objects by modelling their shape, as well as ones that predict the motion of ob- jects using learned trajectory models. In this paper, we combine these ideas and propose shape-motion patterns (SMPs) that incorporate shape as well as motion to model a vari- ety of objects in an unsupervised way. By using shape, our method can learn trajectory models that distinguish object categories with distinct behaviour. We develop methods to classify objects into SMPs and to predict future motion. In experiments, we analyze our learned categorization and demonstrate superior performance of our motion predictions compared to a Kalman filter and a learned pure trajectory model. We also demonstrate how SMPs can indicate potentially harmful situations in traffic scenarios.
» Show BibTeX
@inproceedings{klostermann2016_smps,
title = {Unsupervised Learning of Shape-Motion Patterns for Objects in Urban Street Scenes},
author = {Dirk Klostermann and Aljosa Osep and J\"org St\"uckler and Bastian Leibe},
booktitle = {Proc. of the British Machine Vision Conference (BMVC)},
year = {2016}, note = {to appear}
}
Scene Flow Propagation for Semantic Mapping and Object Discovery in Dynamic Street Scenes

Scene understanding is an important prerequisite for vehicles and robots that operate autonomously in dynamic urban street scenes. For navigation and high-level behavior planning, the robots not only require a persistent 3D model of the static surroundings - equally important, they need to perceive and keep track of dynamic objects. In this paper, we propose a method that incrementally fuses stereo frame observations into temporally consistent semantic 3D maps. In contrast to previous work, our approach uses scene flow to propagate dynamic objects within the map. Our method provides a persistent 3D occupancy as well as semantic belief on static as well as moving objects. This allows for advanced reasoning on objects despite noisy single-frame observations and occlusions. We develop a novel approach to discover object instances based on the temporally consistent shape, appearance, motion, and semantic cues in our maps. We evaluate our approaches to dynamic semantic mapping and object discovery on the popular KITTI benchmark and demonstrate improved results compared to single-frame methods.
» Show BibTeX
@inproceedings{kochanov2016_sceneflowprop,
title = {Scene Flow Propagation for Semantic Mapping and Object Discovery in Dynamic Street Scenes},
author = {Deyvid Kochanov and Aljosa Osep and J\"org St\"uckler and Bastian Leibe},
booktitle = {Proc. of the IEEE Int. Conf. on Intelligent Robots and Systems (IROS)}, year = {2016},
note = {to appear}
}
Multi-Scale Object Candidates for Generic Object Tracking in Street Scenes

Most vision based systems for object tracking in urban environments focus on a limited number of important object categories such as cars or pedestrians, for which powerful detectors are available. However, practical driving scenarios contain many additional objects of interest, for which suitable detectors either do not yet exist or would be cumbersome to obtain. In this paper we propose a more general tracking approach which does not follow the often used tracking-by- detection principle. Instead, we investigate how far we can get by tracking unknown, generic objects in challenging street scenes. As such, we do not restrict ourselves to only tracking the most common categories, but are able to handle a large variety of static and moving objects. We evaluate our approach on the KITTI dataset and show competitive results for the annotated classes, even though we are not restricted to them.
@inproceedings{Osep16ICRA,
title={Multi-Scale Object Candidates for Generic Object Tracking in Street
Scenes},
author={O\v{s}ep, Aljo\v{s}a and Hermans, Alexander and Engelmann, Francis and Klostermann, Dirk and and Mathias, Markus and Leibe, Bastian},
booktitle={ICRA},
year={2016}
}
A Fixed-Dimensional 3D Shape Representation for Matching Partially Observed Objects in Street Scenes
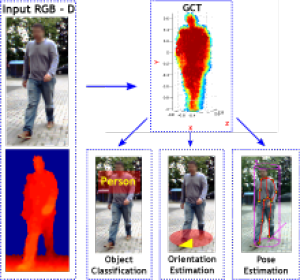
In this paper, we present an object-centric, fixeddimensional 3D shape representation for robust matching of partially observed object shapes, which is an important component for object categorization from 3D data. A main problem when working with RGB-D data from stereo, Kinect, or laser sensors is that the 3D information is typically quite noisy. For that reason, we accumulate shape information over time and register it in a common reference frame. Matching the resulting shapes requires a strategy for dealing with partial observations. We therefore investigate several distance functions and kernels that implement different such strategies and compare their matching performance in quantitative experiments. We show that the resulting representation achieves good results for a large variety of vision tasks, such as multi-class classification, person orientation estimation, and articulated body pose estimation, where robust 3D shape matching is essential.
Multi-View Normal Field Integration for 3D Reconstruction of Mirroring Objects

In this paper, we present a novel, robust multi-view normal field integration technique for reconstructing the full 3D shape of mirroring objects. We employ a turntable-based setup with several cameras and displays. These are used to display illumination patterns which are reflected by the object surface. The pattern information observed in the cameras enables the calculation of individual volumetric normal fields for each combination of camera, display and turntable angle. As the pattern information might be blurred depending on the surface curvature or due to non-perfect mirroring surface characteristics, we locally adapt the decoding to the finest still resolvable pattern resolution. In complex real-world scenarios, the normal fields contain regions without observations due to occlusions and outliers due to interreflections and noise. Therefore, a robust reconstruction using only normal information is challenging. Via a non-parametric clustering of normal hypotheses derived for each point in the scene, we obtain both the most likely local surface normal and a local surface consistency estimate. This information is utilized in an iterative min-cut based variational approach to reconstruct the surface geometry.
Multi-View 3D Reconstruction of Highly-Specular Objects

In this thesis, we address the problem of image-based 3D reconstruction of objects exhibiting complex reflectance behaviour using surface gradient information techniques. In this context, we are addressing two open questions. The first one focuses on the aspect, if it is possible to design a robust multi-view normal field integration algorithm, which can integrate noisy, imprecise and only partially captured real-world data. Secondly, the question is if it is possible to recover a precise geometry of the challenging highly-specular objects by multi-view normal estima- tion and integration using such an algorithm.
The main result of this work is the first multi-view normal field integration algorithm that reliably reconstructs a surface of object from normal fields captured in the real-world setup. The surface of the unknown object is reconstructed by fitting a surface to the vector field reconstructed from observed normal samples. The vector field and the surface consistency information are computed based on a feature space analysis of back-projections of the normals using robust, nonparametric probability density estimation methods. This normal field integration technique is not only suitable for reconstructing lambertian objects, but, in the scope of this work, it is also used for the reconstruction of highly-specular objects via multi-view shape-from-specularity techniques.
We performed an evaluation on synthetic normal fields, photometric stereo based normal estimates of a real lambertian object and, most importantly, demon- strated state-of-the art results in the domain of 3D reconstruction of highly-specular objects based on the measured data and integrated by the proposed algorithm. Our method presents a significant advancement in the area of gradient information based 3D reconstruction techniques with a potential to address 3D reconstruction of a large class of objects exhibiting complex reflectance behaviour. Furthermore, using this method, a wide range of proposed normal estimation techniques can now be used for the recovery of full 3D shapes.
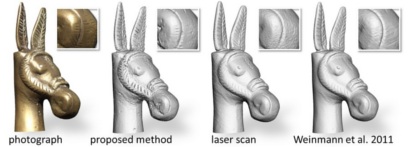
Fusing Structured Light Consistency and Helmholtz Normals for 3D Reconstruction
In this paper, we propose a 3D reconstruction approach which combines a structured light based consistency measure with dense normal information obtained by exploiting the Helmholtz reciprocity principle. This combination compensates for the individual limitations of techniques providing normal information, which are mainly affected by low-frequency drift, and those providing positional information, which are often not well-suited to recover fine details. To obtain Helmholtz reciprocal samples, we employ a turntable-based setup. Due to the reciprocity, the structured light directly provides the occlusion information needed during the normal estimation for both the cameras and light sources. We perform the reconstruction by solving one global variational problem which integrates all available measurements simultaneously, over all cameras, light source positions and turntable rotations. For this, we employ an octree-based continuous min-cut framework in order to alleviate metrification errors while maintaining memory efficiency. We evaluate the performance of our algorithm both on synthetic and real-world data.
