
Publications
Tracking People and Their Objects

Current pedestrian tracking approaches ignore impor- tant aspects of human behavior. Humans are not moving independently, but they closely interact with their environ- ment, which includes not only other persons, but also dif- ferent scene objects. Typical everyday scenarios include people moving in groups, pushing child strollers, or pulling luggage. In this paper, we propose a probabilistic approach for classifying such person-object interactions, associating objects to persons, and predicting how the interaction will most likely continue. Our approach relies on stereo depth information in order to track all scene objects in 3D, while simultaneously building up their 3D shape models. These models and their relative spatial arrangement are then fed into a probabilistic graphical model which jointly infers pairwise interactions and object classes. The inferred inter- actions can then be used to support tracking by recovering lost object tracks. We evaluate our approach on a novel dataset containing more than 15,000 frames of person- object interactions in 325 video sequences and demonstrate good performance in challenging real-world scenarios.
Multi-View Normal Field Integration for 3D Reconstruction of Mirroring Objects

In this paper, we present a novel, robust multi-view normal field integration technique for reconstructing the full 3D shape of mirroring objects. We employ a turntable-based setup with several cameras and displays. These are used to display illumination patterns which are reflected by the object surface. The pattern information observed in the cameras enables the calculation of individual volumetric normal fields for each combination of camera, display and turntable angle. As the pattern information might be blurred depending on the surface curvature or due to non-perfect mirroring surface characteristics, we locally adapt the decoding to the finest still resolvable pattern resolution. In complex real-world scenarios, the normal fields contain regions without observations due to occlusions and outliers due to interreflections and noise. Therefore, a robust reconstruction using only normal information is challenging. Via a non-parametric clustering of normal hypotheses derived for each point in the scene, we obtain both the most likely local surface normal and a local surface consistency estimate. This information is utilized in an iterative min-cut based variational approach to reconstruct the surface geometry.
Random Forests of Local Experts for Pedestrian Detection
Pedestrian detection is one of the most challenging tasks in computer vision, and has received a lot of attention in the last years. Recently, some authors have shown the advan- tages of using combinations of part/patch-based detectors in order to cope with the large variability of poses and the existence of partial occlusions. In this paper, we propose a pedestrian detection method that efficiently combines mul- tiple local experts by means of a Random Forest ensemble. The proposed method works with rich block-based repre- sentations such as HOG and LBP, in such a way that the same features are reused by the multiple local experts, so that no extra computational cost is needed with respect to a holistic method. Furthermore, we demonstrate how to inte- grate the proposed approach with a cascaded architecture in order to achieve not only high accuracy but also an ac- ceptable efficiency. In particular, the resulting detector op- erates at five frames per second using a laptop machine. We tested the proposed method with well-known challeng- ing datasets such as Caltech, ETH, Daimler, and INRIA. The method proposed in this work consistently ranks among the top performers in all the datasets, being either the best method or having a small difference with the best one.
Discovering Details and Scene Structure with Hierarchical Iconoid Shift

Current landmark recognition engines are typically aimed at recognizing building-scale landmarks, but miss interesting details like portals, statues or windows. This is because they use a flat clustering that summarizes all photos of a building facade in one cluster. We propose Hierarchical Iconoid Shift, a novel landmark clustering algorithm capable of discovering such details. Instead of just a collection of clusters, the output of HIS is a set of dendrograms describing the detail hierarchy of a landmark. HIS is based on the novel Hierarchical Medoid Shift clustering algorithm that performs a continuous mode search over the complete scale space. HMS is completely parameter-free, has the same complexity as Medoid Shift and is easy to parallelize. We evaluate HIS on 800k images of 34 landmarks and show that it can extract an often surprising amount of detail and structure that can be applied, e.g., to provide a mobile user with more detailed information on a landmark or even to extend the landmark’s Wikipedia article.
OpenStreetSLAM: Global Vehicle Localization Using OpenStreetMaps

In this paper we propose an approach for global vehicle localization that combines visual odometry with map information from OpenStreetMaps to provide robust and accurate estimates for the vehicle’s position. The main contribution of this work comes from the incorporation of the map data as an additional cue into the observation model of a Monte Carlo Localization framework. The resulting approach is able to compensate for the drift that visual odometry accumulates over time, significantly improving localization quality. As our results indicate, the proposed approach outperforms current state-ofthe- art visual odometry approaches, indicating in parallel the potential that map data can bring to the global localization task.
SIFT-Realistic Rendering

3D localization approaches establish correspondences between points in a query image and a 3D point cloud reconstruction of the environment. Traditionally, the database models are created from photographs using Structure-from-Motion (SfM) techniques, which requires large collections of densely sampled images. In this paper, we address the question how point cloud data from terrestrial laser scanners can be used instead to significantly reduce the data collection effort and enable more scalable localization.
The key change here is that, in contrast to SfM points, laser-scanned 3D points are not automatically associated with local image features that could be matched to query image features. In order to make this data usable for image-based localization, we explore how point cloud rendering techniques can be leveraged to create virtual views from which database features can be extracted that match real image-based features as closely as possible. We propose different rendering techniques for this task, experimentally quantify how they affect feature repeatability, and demonstrate their benefit for image-based localization.
Streaming Data from HDD to GPUs for Sustained Peak Performance
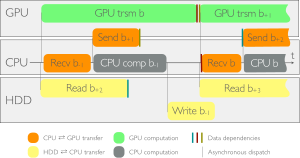
In the context of the genome-wide association studies (GWAS), one has to solve long sequences of generalized least-squares problems; such a task has two limiting factors: execution time --often in the range of days or weeks-- and data management --data sets in the order of Terabytes. We present an algorithm that obviates both issues. By pipelining the computation, and thanks to a sophisticated transfer strategy, we stream data from hard disk to main memory to GPUs and achieve sustained peak performance; with respect to a highly-optimized CPU implementation, our algorithm shows a speedup of 2.6x. Moreover, the approach lends itself to multiple GPUs and attains almost perfect scalability. When using 4 GPUs, we observe speedups of 9x over the aforementioned implementation, and 488x over a widespread biology library.
@inproceedings{Beyer2013GWAS,
author = {Lucas Beyer and Paolo Bientinesi},
title = {Streaming Data from HDD to GPUs for Sustained Peak Performance},
booktitle = {Euro-Par},
publisher = {Springer},
series = {Lecture Notes in Computer Science},
volume = {8097},
pages = {788-799},
year = {2013},
isbn = {3642400477},
ee = {http://arxiv.org/abs/1302.4332},
}
Multi-View 3D Reconstruction of Highly-Specular Objects

In this thesis, we address the problem of image-based 3D reconstruction of objects exhibiting complex reflectance behaviour using surface gradient information techniques. In this context, we are addressing two open questions. The first one focuses on the aspect, if it is possible to design a robust multi-view normal field integration algorithm, which can integrate noisy, imprecise and only partially captured real-world data. Secondly, the question is if it is possible to recover a precise geometry of the challenging highly-specular objects by multi-view normal estima- tion and integration using such an algorithm.
The main result of this work is the first multi-view normal field integration algorithm that reliably reconstructs a surface of object from normal fields captured in the real-world setup. The surface of the unknown object is reconstructed by fitting a surface to the vector field reconstructed from observed normal samples. The vector field and the surface consistency information are computed based on a feature space analysis of back-projections of the normals using robust, nonparametric probability density estimation methods. This normal field integration technique is not only suitable for reconstructing lambertian objects, but, in the scope of this work, it is also used for the reconstruction of highly-specular objects via multi-view shape-from-specularity techniques.
We performed an evaluation on synthetic normal fields, photometric stereo based normal estimates of a real lambertian object and, most importantly, demon- strated state-of-the art results in the domain of 3D reconstruction of highly-specular objects based on the measured data and integrated by the proposed algorithm. Our method presents a significant advancement in the area of gradient information based 3D reconstruction techniques with a potential to address 3D reconstruction of a large class of objects exhibiting complex reflectance behaviour. Furthermore, using this method, a wide range of proposed normal estimation techniques can now be used for the recovery of full 3D shapes.
Computer Vision Systems

This book constitutes the refereed proceedings of the 9th International Conference on Computer Vision Systems, ICVS 2013, held in St. Petersburg, Russia, July 16-18, 2013. Proceedings. The 16 revised papers presented with 20 poster papers were carefully reviewed and selected from 94 submissions. The papers are organized in topical sections on image and video capture; visual attention and object detection; self-localization and pose estimation; motion and tracking; 3D reconstruction; features, learning and validation.
Multi-Scale, Categorical Object Detection and Pose Estimation using Hough Forest in RGB-D Images

Classification and localization of objects enables a robot to plan and execute tasks in unstructured environments. Much work on the detection and pose estimation of objects in the robotics context focused on object instances. We propose here a novel approach that detects object classes and finds the canonical pose of the detected objects in RGB-D images using Hough forests. In Hough forests each random decision tree maps local image patch to one of its leaves through a cascade of binary decisions over a patch appearance, where each leaf casts probabilistic Hough vote in Hough space encoded in object location, scale and orientation. We propose depth and surfel pair-feature as an additional appearance channels to introduce scale, shape and geometric information about the object. Moreover, we exploit depth at various stages of the processing pipeline to handle variable scale efficiently. Since obtaining large amounts of annotated training data is a cumbersome process, we use training data captured on a turn-table setup. Although the training examples from this domain do not include clutter, occlusions or varying background situations. Hence, we propose a simple but effective approach to render training images from turn-table dataset which shows the same statistical distribution in image properties as natural scenes. We evaluate our approach on publicly available RGB-D object recognition benchmark datasets and demonstrate good performance in varying background and view poses, clutter, and occlusions.
Depth-Enhanced Hough Forests for Object-Class Detection and Continuous Pose Estimation

Much work on the detection and pose estimation of objects in the robotics context focused on object instances. We propose a novel approach that detects object classes and finds the pose of the detected objects in RGB-D images. Our method is based on Hough forests, a variant of random decision and regression trees that categorize pixels and vote for 3D object position and orientation. It makes efficient use of dense depth for scale-invariant detection and pose estimation. We propose an effective way to train our method for arbitrary scenes that are rendered from training data in a turn-table setup. We evaluate our approach on publicly available RGB-D object recognition benchmark datasets and demonstrate stateof-the-art performance in varying background and view poses, clutter, and occlusions.
Previous Year (2012)
