
Publications
Taking Mobile Multi-Object Tracking to the Next Level: People, Unknown Objects, and Carried Items

In this paper, we aim to take mobile multi-object tracking to the next level. Current approaches work in a tracking-by-detection framework, which limits them to object categories for which pre-trained detector models are available. In contrast, we propose a novel tracking-before-detection approach that can track both known and unknown object categories in very challenging street scenes. Our approach relies on noisy stereo depth data in order to segment and track objects in 3D. At its core is a novel, compact 3D representation that allows us to robustly track a large variety of objects, while building up models of their 3D shape online. In addition to improving tracking performance, this represensation allows us to detect anomalous shapes, such as carried items on a person’s body. We evaluate our approach on several challenging video sequences of busy pedestrian zones and show that it outperforms state-of-the-art approaches.
Joint 2D-3D Temporally Consistent Semantic Segmentation of Street Scenes

In this paper we propose a novel Conditional Random Field (CRF) formulation for the semantic scene labeling problem which is able to enforce temporal consistency between consecutive video frames and take advantage of the 3D scene geometry to improve segmentation quality. The main contribution of this work lies in the novel use of a 3D scene reconstruction as a means to temporally couple the individual image segmentations, allowing information flow from 3D geometry to the 2D image space. As our results show, the proposed framework outperforms state-of-the-art methods and opens a new perspective towards a tighter interplay of 2D and 3D information in the scene understanding problem.
Close-Range Human Detection for Head-Mounted Cameras
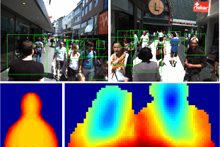
In this paper we consider the problem of multi-person detection from the perspective of a head mounted stereo camera. As pedestrians close to the camera cannot be detected by classical full-body detectors due to strong occlusion, we propose a stereo depth-template based detection approach for close-range pedestrians. We perform a sliding window procedure, where we measure the similarity between a learned depth template and the depth image. To reduce the search space of the detector we slide the detector only over few selected regions of interest that are generated based on depth information. The region-of-interest selection allows us to further constrain the number of scales to be evaluated, significantly reducing the computational cost. We present experiments on stereo sequences recorded from a head-mounted camera setup in crowded shopping street scenarios and show that our proposed approach achieves superior performance on this very challenging data.
Improving Image-Based Localization by Active Correspondence Search
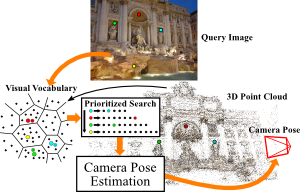
We propose a powerful pipeline for determining the pose of a query image relative to a point cloud reconstruction of a large scene consisting of more than one million 3D points. The key component of our approach is an efficient and effective search method to establish matches between image features and scene points needed for pose estimation. Our main contribution is a framework for actively searching for additional matches, based on both 2D-to-3D and 3D-to-2D search. A unified formulation of search in both directions allows us to exploit the distinct advantages of both strategies, while avoiding their weaknesses. Due to active search, the resulting pipeline is able to close the gap in registration performance observed between efficient search methods and approaches that are allowed to run for multiple seconds, without sacrificing run-time efficiency. Our method achieves the best registration performance published so far on three standard benchmark datasets, with run-times comparable or superior to the fastest state-of-the-art methods.
The original publication will be available at www.springerlink.com upon publication.
Image Retrieval for Image-Based Localization Revisited
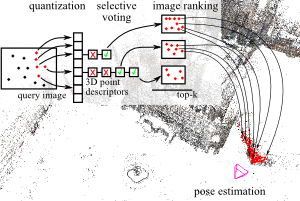
To reliably determine the camera pose of an image relative to a 3D point cloud of a scene, correspondences between 2D features and 3D points are needed. Recent work has demonstrated that directly matching the features against the points outperforms methods that take an intermediate image retrieval step in terms of the number of images that can be localized successfully. Yet, direct matching is inherently less scalable than retrieval-based approaches. In this paper, we therefore analyze the algorithmic factors that cause the performance gap and identify false positive votes as the main source of the gap. Based on a detailed experimental evaluation, we show that retrieval methods using a selective voting scheme are able to outperform state-of-the-art direct matching methods. We explore how both selective voting and correspondence computation can be accelerated by using a Hamming embedding of feature descriptors. Furthermore, we introduce a new dataset with challenging query images for the evaluation of image-based localization.
Towards Fast Image-Based Localization on a City-Scale
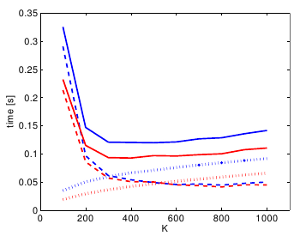
Recent developments in Structure-from-Motion approaches allow the reconstructions of large parts of urban scenes. The available models can in turn be used for accurate image-based localization via pose estimation from 2D-to-3D correspondences. In this paper, we analyze a recently proposed localization method that achieves state-of-the-art localization performance using a visual vocabulary quantization for efficient 2D-to-3D correspondence search. We show that using only a subset of the original models allows the method to achieve a similar localization performance. While this gain can come at additional computational cost depending on the dataset, the reduced model requires significantly less memory, allowing the method to handle even larger datasets. We study how the size of the subset, as well as the quantization, affect both the search for matches and the time needed by RANSAC for pose estimation.
The original publication will be available at www.springerlink.com upon publication.
Digitization of Inaccessible Archeological Sites with Autonomous Mobile Robots
Exploiting Graphics Adapters for Computational Biology
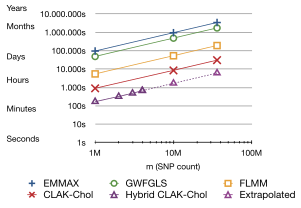
Accelerate Genome-Wide Association Studies (GWAS) by performing the most demanding computation on the GPU in a batched, streamed fashion. Involves huge data size (terabytes), streaming, asynchronicity, parallel computation and some more buzzwords.
@MastersThesis{Beyer2012GWAS,
author = {Lucas Beyer},
title = {{Exploiting Graphics Adapters for Computational Biology}},
school = {RWTH Aachen (AICES)},
address = {Aachen, Germany},
year = {2012},
}
Fusing Structured Light Consistency and Helmholtz Normals for 3D Reconstruction
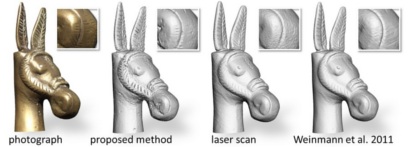
In this paper, we propose a 3D reconstruction approach which combines a structured light based consistency measure with dense normal information obtained by exploiting the Helmholtz reciprocity principle. This combination compensates for the individual limitations of techniques providing normal information, which are mainly affected by low-frequency drift, and those providing positional information, which are often not well-suited to recover fine details. To obtain Helmholtz reciprocal samples, we employ a turntable-based setup. Due to the reciprocity, the structured light directly provides the occlusion information needed during the normal estimation for both the cameras and light sources. We perform the reconstruction by solving one global variational problem which integrates all available measurements simultaneously, over all cameras, light source positions and turntable rotations. For this, we employ an octree-based continuous min-cut framework in order to alleviate metrification errors while maintaining memory efficiency. We evaluate the performance of our algorithm both on synthetic and real-world data.
Material Recognition.
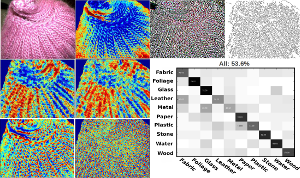
Material recognition is an important subtask in computer vision. In this paper, we aim for the identification of material categories from a single image captured under unknown illumination and view conditions. Therefore, we use several features which cover various aspects of material appearance and perform supervised classification using Support Vector Machines. We demonstrate the feasibility of our approach by testing on the challenging Flickr Material Database. Based on this dataset, we also carry out a comparison to a previously published work [Liu et al., ”Exploring Features in a Bayesian Framework for Material Recognition”, CVPR 2010] which uses Bayesian inference and reaches a recognition rate of 44.6% on this dataset and represents the current state-of the-art. With our SVM approach we obtain 53.1% and hence, significantly outperform this approach.
Improved Ramsey-based Büchi Complementation
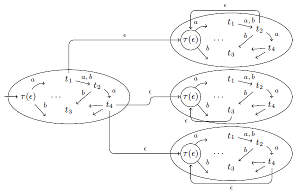
We consider complementing Büchi automata by applying the Ramsey-based approach, which is the original approach already used by Büchi and later improved by Sistla et al. We present several heuristics to reduce the state space of the resulting complement automaton and provide experimental data that shows that our improved construction can compete (in terms of finished complementation tasks) also in practice with alternative constructions like rank-based complementation. Furthermore, we show how our techniques can be used to improve the Ramsey-based complementation such that the asymptotic upper bound for the resulting complement automaton is 2^O(n log n) instead of 2^O(n2).
@incollection{breuers2012improved,
title={Improved Ramsey-based B{\"u}chi Complementation},
author={Breuers, Stefan and L{\"o}ding, Christof and Olschewski, J{\"o}rg},
booktitle={Foundations of Software Science and Computational Structures},
pages={150--164},
year={2012},
publisher={Springer}
}
Previous Year (2011)
