
Profile

|
Dr. Alexander Hermans |
My research focus lies on applied deep learning and computer vision, often with a focus on robotics. Wouldn't it be great if stuff we do on benchmark datasets works in the real world too ;D!?
You can find some more info about me on GitHub, Google Scholar or LinkedIn.
Publications
DINO in the Room: Leveraging 2D Foundation Models for 3D Segmentation

Vision foundation models (VFMs) trained on large-scale image datasets provide high-quality features that have significantly advanced 2D visual recognition. However, their potential in 3D scene segmentation remains largely untapped, despite the common availability of 2D images alongside 3D point cloud datasets. While significant research has been dedicated to 2D-3D fusion, recent state-of-the-art 3D methods predominantly focus on 3D data, leaving the integration of VFMs into 3D models underexplored. In this work, we challenge this trend by introducing DITR, a generally applicable approach that extracts 2D foundation model features, projects them to 3D, and finally injects them into a 3D point cloud segmentation model. DITR achieves state-of-the-art results on both indoor and outdoor 3D semantic segmentation benchmarks. To enable the use of VFMs even when images are unavailable during inference, we additionally propose to pretrain 3D models by distilling 2D foundation models. By initializing the 3D backbone with knowledge distilled from 2D VFMs, we create a strong basis for downstream 3D segmentation tasks, ultimately boosting performance across various datasets.
@InProceedings{knaebel2025ditr,
title = {{DINO} in the Room: Leveraging {2D} Foundation Models for {3D} Segmentation},
author = {Knaebel, Karim and Yilmaz, Kadir and de Geus, Daan and Hermans, Alexander and Adrian, David and Linder, Timm and Leibe, Bastian},
booktitle = {2026 International Conference on 3D Vision (3DV)},
year = {2026}
}
Your ViT is Secretly an Image Segmentation Model
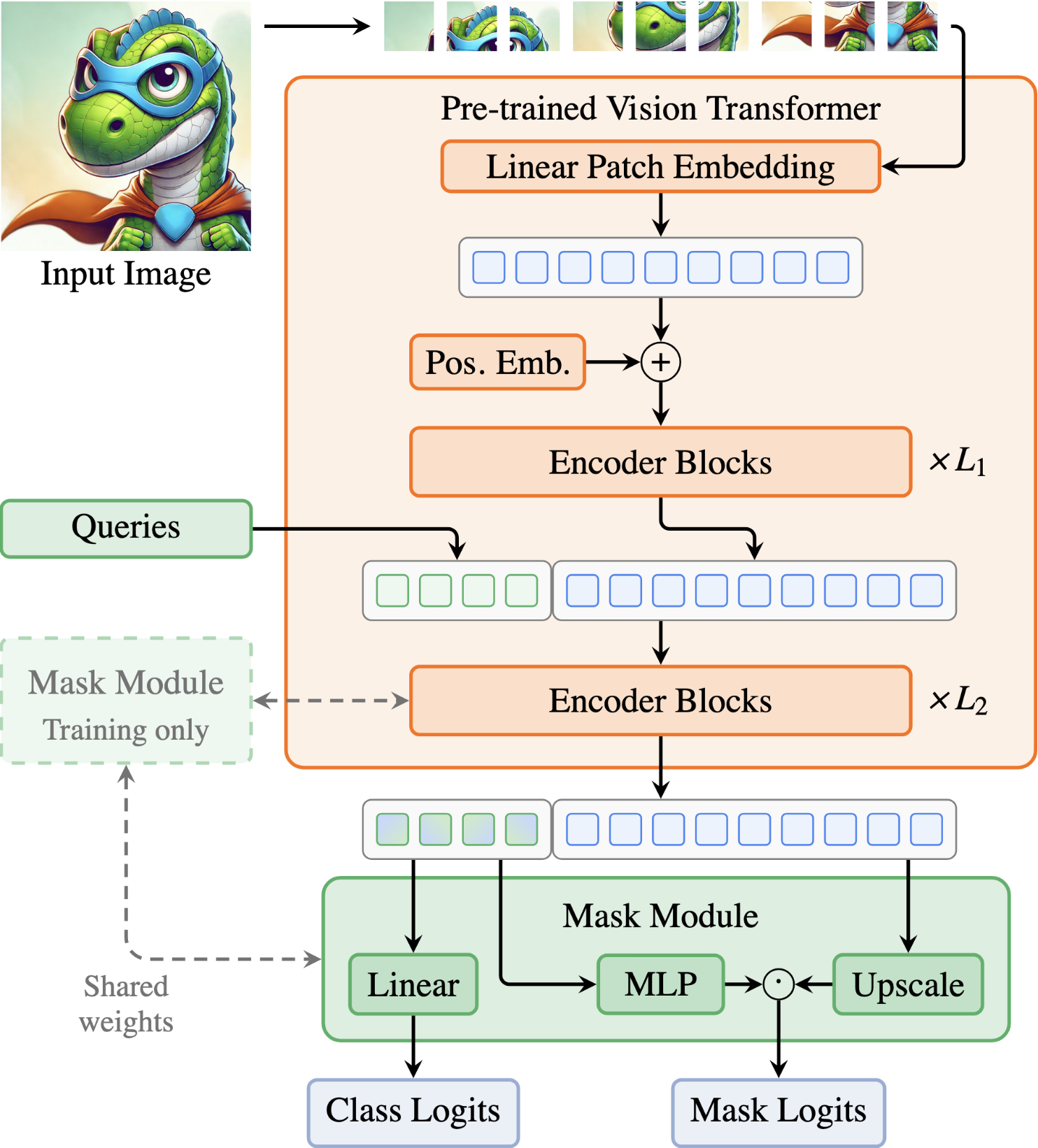
Vision Transformers (ViTs) have shown remarkable performance and scalability across various computer vision tasks. To apply single-scale ViTs to image segmentation, existing methods adopt a convolutional adapter to generate multi-scale features, a pixel decoder to fuse these features, and a Transformer decoder that uses the fused features to make predictions. In this paper, we show that the inductive biases introduced by these task-specific components can instead be learned by the ViT itself, given sufficiently large models and extensive pre-training. Based on these findings, we introduce the Encoder-only Mask Transformer (EoMT), which repurposes the plain ViT architecture to conduct image segmentation. With large-scale models and pre-training, EoMT obtains a segmentation accuracy similar to state-of-the-art models that use task-specific components. At the same time, EoMT is significantly faster than these methods due to its architectural simplicity, e.g., up to 4× faster with ViT-L. Across a range of model sizes, EoMT demonstrates an optimal balance between segmentation accuracy and prediction speed, suggesting that compute resources are better spent on scaling the ViT itself rather than adding architectural complexity. Code: https://www.tue-mps.org/eomt/.
@inproceedings{kerssies2025eomt,
author = {Kerssies, Tommie and Cavagnero, Niccol\`{o} and Hermans, Alexander and Norouzi, Narges and Averta, Giuseppe and Leibe, Bastian and Dubbelman, Gijs and {de Geus}, Daan},
title = {{Your ViT is Secretly an Image Segmentation Model}},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025},
}
Fine-Tuning Image-Conditional Diffusion Models is Easier than You Think
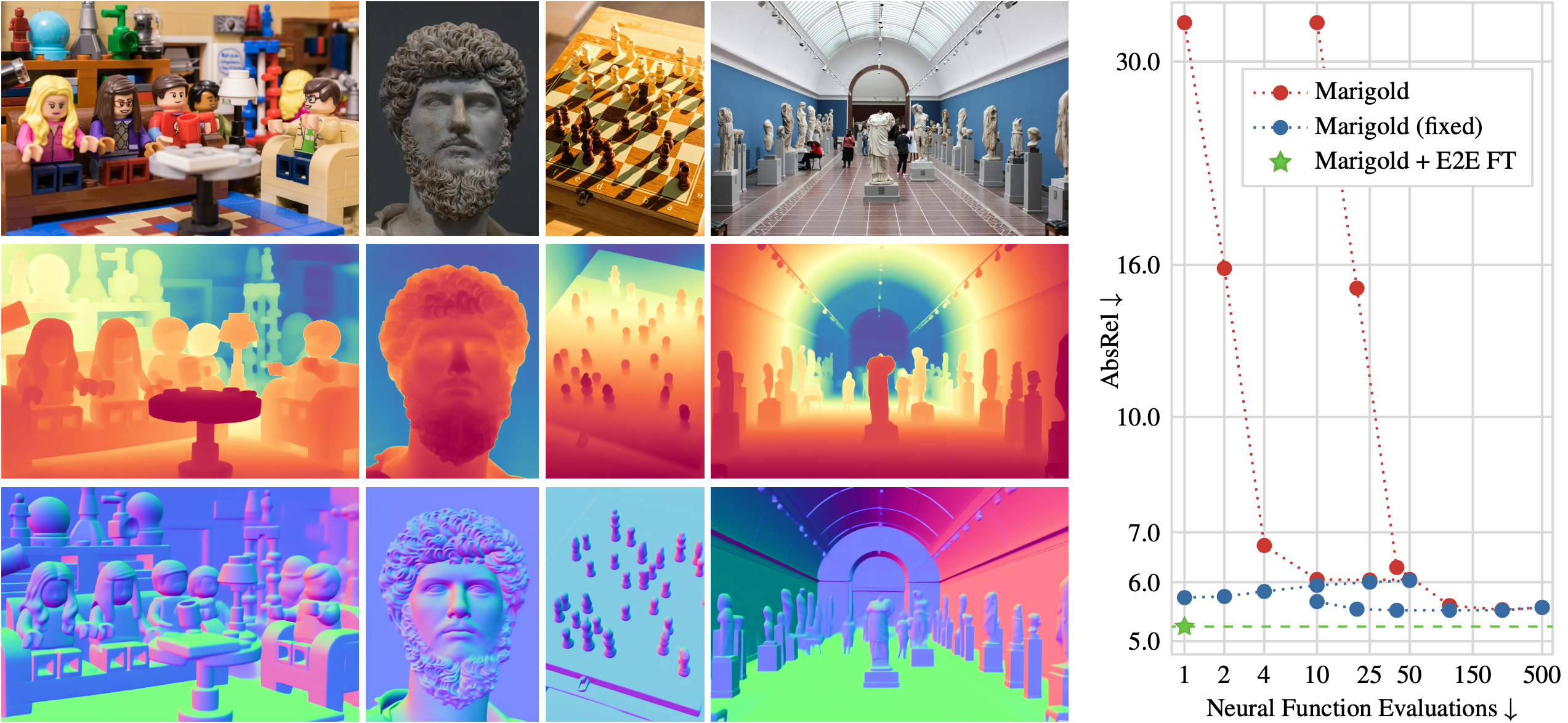
Recent work showed that large diffusion models can be reused as highly precise monocular depth estimators by casting depth estimation as an image-conditional image generation task. While the proposed model achieved state-of-the-art results, high computational demands due to multi-step inference limited its use in many scenarios. In this paper, we show that the perceived inefficiency was caused by a flaw in the inference pipeline that has so far gone unnoticed. The fixed model performs comparably to the best previously reported configuration while being more than 200x faster. To optimize for downstream task performance, we perform end-to-end fine-tuning on top of the single-step model with task-specific losses and get a deterministic model that outperforms all other diffusion-based depth and normal estimation models on common zero-shot benchmarks. We surprisingly find that this fine-tuning protocol also works directly on Stable Diffusion and achieves comparable performance to current state-of-the-art diffusion-based depth and normal estimation models, calling into question some of the conclusions drawn from prior works.
@InProceedings{martingarcia2024diffusione2eft,
title = {Fine-Tuning Image-Conditional Diffusion Models is Easier than You Think},
author = {Martin Garcia, Gonzalo and Knaebel, Karim and Schmidt, Christian and de Geus, Daan and Hermans, Alexander and Leibe, Bastian},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
year = {2025}
}
Sa2VA-i: Improving Sa2VA Results with Consistent Training and Inference

Sa2VA is a recent model for language-guided dense grounding in images and video that achieves state-of-the-art results on multiple segmentation benchmarks and that has become widely popular. However, we found that Sa2VA does not perform according to its full potential for referring video object segmentation tasks. We identify inconsistencies between training and inference procedures as the key factor holding it back. To mitigate this issue, we propose an improved version of Sa2VA, Sa2VA-i, that rectifies these issues and improves the results. In fact, Sa2VA-i sets a new state of the art for multiple video benchmarks and achieves improvements of up to +11.6 J&F on MeViS, +1.4 on Ref-YT-VOS, +3.3 on Ref-DAVIS and +4.1 on ReVOS using the same Sa2VA checkpoints. With our fixes, the Sa2VA-i-1B model even performs on par with the original Sa2VA-26B model on the MeViS benchmark. We hope that this work will show the importance of seemingly trivial implementation details and that it will provide valuable insights for the referring video segmentation field.
@article{sa2va2025improved,
title={Sa2VA-i: Improving Sa2VA Results with Consistent Training and Inference},
author={Nekrasov, Alexey and Athar, Ali and de Geus, Daan and Hermans, Alexander and Leibe, Bastian},
journal={arXiv preprint arXiv:2509.19082},
year={2025}
}
OoDIS: Anomaly Instance Segmentation Benchmark

Autonomous vehicles require a precise understanding of their environment to navigate safely. Reliable identification of unknown objects, especially those that are absent during training, such as wild animals, is critical due to their potential to cause serious accidents. Significant progress in semantic segmentation of anomalies has been driven by the availability of out-of-distribution (OOD) benchmarks. However, a comprehensive understanding of scene dynamics requires the segmentation of individual objects, and thus the segmentation of instances is essential. Development in this area has been lagging, largely due to the lack of dedicated benchmarks. To address this gap, we have extended the most commonly used anomaly segmentation benchmarks to include the instance segmentation task. Our evaluation of anomaly instance segmentation methods shows that this challenge remains an unsolved problem. The benchmark website and the competition page can be found at: https://vision.rwth-aachen.de/oodis
@article{nekrasov2024oodis,
title={{OoDIS: Anomaly Instance Segmentation Benchmark}},
author={Nekrasov, Alexey and Zhou, Rui and Ackermann, Miriam and Hermans, Alexander and Leibe, Bastian and Rottmann, Matthias},
journal={ICRA},
year={2025}
}
RGB-D Cube R-CNN: 3D Object Detection with Selective Modality Dropout
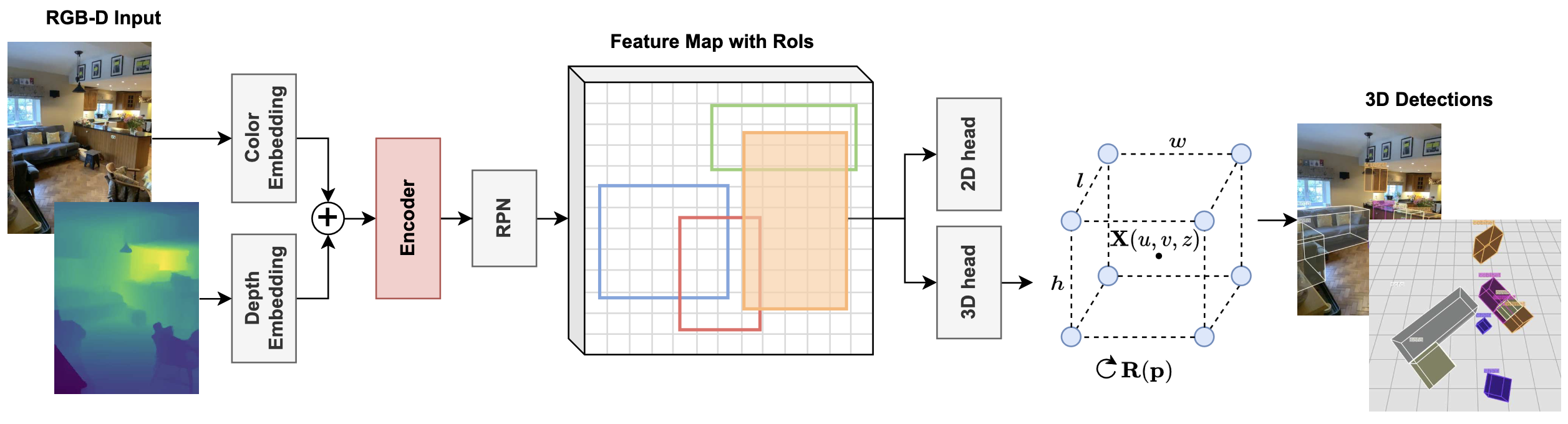
In this paper we create an RGB-D 3D object detector targeted at indoor robotics use cases where one modality may be unavailable due to a specific sensor setup or a sensor failure. We incorporate RGB and depth fusion into the recent Cube R-CNN framework with support for selective modality dropout. To train this model we augment the Omni3DIN dataset with depth information leading to a diverse dataset for 3D object detection in indoor scenes. In order to leverage strong pretrained networks we investigate the viability of Transformer-based backbones (Swin ViT) as an alternative to the currently popular CNN-based DLA backbone. We show that these Transformer-based image models work well based on our early-fusion approach and propose a modality dropout scheme to avoid the disregard of any modality during training facilitating selective modality dropout during inference. In extensive experiments our proposed RGB-D Cube R-CNN outperforms an RGB-only Cube R-CNN baseline by a significant margin on the task of indoor object detection. Additionally we observe a slight performance boost from the RGB-D training when inferring on only one modality which could for example be valuable in robotics applications with a reduced or unreliable sensor set.
@InProceedings{RGB_D_Cube_RCNN_2024_CVPRW,
author = {Piekenbrinck, Jens and Hermans, Alexander and Vaskevicius, Narunas and Linder, Timm and Leibe, Bastian},
title = {{RGB-D Cube R-CNN: 3D Object Detection with Selective Modality Dropout}},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},
year = {2024},
}
DynaMITe: Dynamic Query Bootstrapping for Multi-object Interactive Segmentation Transformer
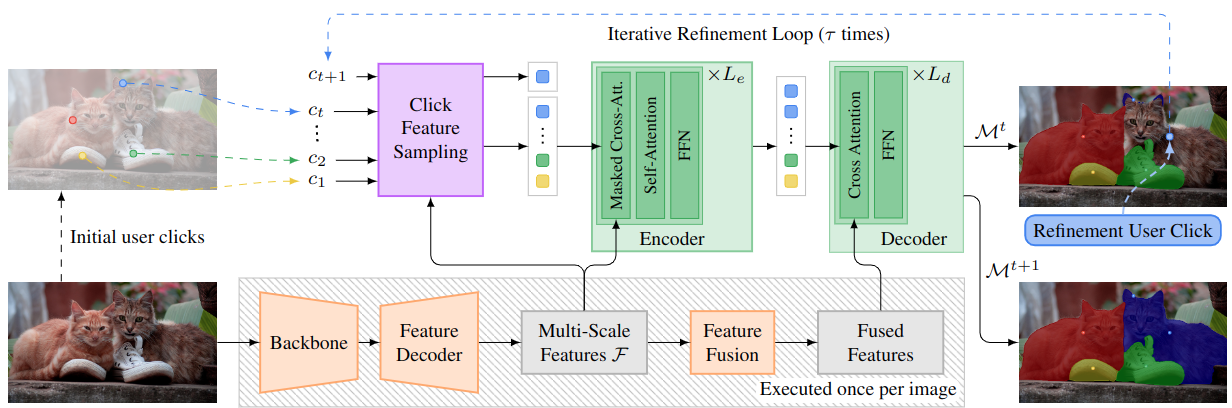
Most state-of-the-art instance segmentation methods rely on large amounts of pixel-precise ground-truth annotations for training, which are expensive to create. Interactive segmentation networks help generate such annotations based on an image and the corresponding user interactions such as clicks. Existing methods for this task can only process a single instance at a time and each user interaction requires a full forward pass through the entire deep network. We introduce a more efficient approach, called DynaMITe, in which we represent user interactions as spatio-temporal queries to a Transformer decoder with a potential to segment multiple object instances in a single iteration. Our architecture also alleviates any need to re-compute image features during refinement, and requires fewer interactions for segmenting multiple instances in a single image when compared to other methods. DynaMITe achieves state-of-the-art results on multiple existing interactive segmentation benchmarks, and also on the new multi-instance benchmark that we propose in this paper.
@article{RanaMahadevan23arxiv,
title={DynaMITe: Dynamic Query Bootstrapping for Multi-object Interactive Segmentation Transformer},
author={Rana, Amit and Mahadevan, Sabarinath and Alexander Hermans and Leibe, Bastian},
journal={arXiv preprint arXiv:2304.06668},
year={2023}
}
TarVis: A Unified Approach for Target-based Video Segmentation
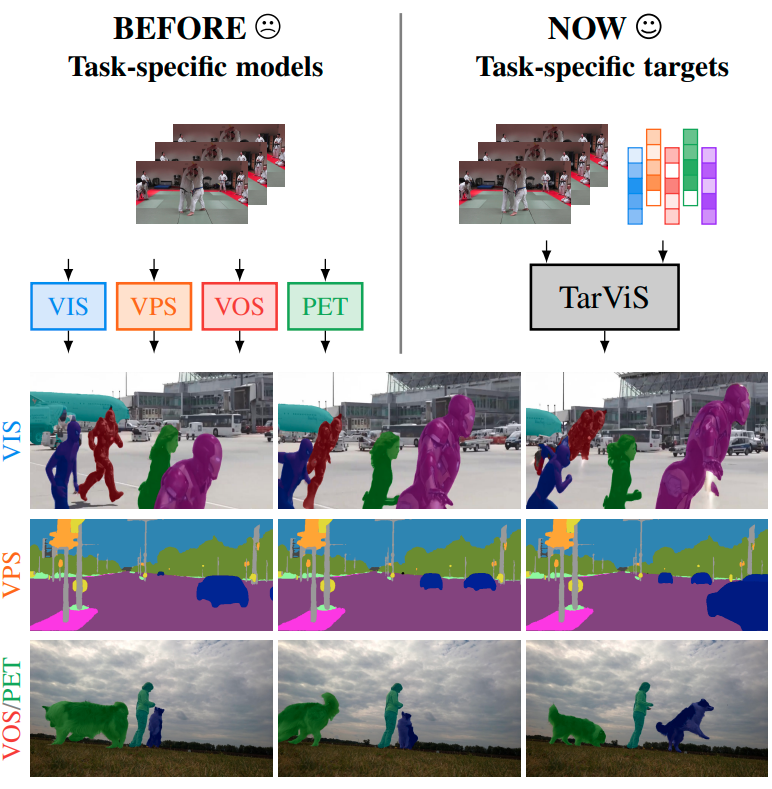
The general domain of video segmentation is currently fragmented into different tasks spanning multiple benchmarks. Despite rapid progress in the state-of-the-art, current methods are overwhelmingly task-specific and cannot conceptually generalize to other tasks. Inspired by recent approaches with multi-task capability, we propose TarViS: a novel, unified network architecture that can be applied to any task that requires segmenting a set of arbitrarily defined 'targets' in video. Our approach is flexible with respect to how tasks define these targets, since it models the latter as abstract 'queries' which are then used to predict pixel-precise target masks. A single TarViS model can be trained jointly on a collection of datasets spanning different tasks, and can hot-swap between tasks during inference without any task-specific retraining. To demonstrate its effectiveness, we apply TarViS to four different tasks, namely Video Instance Segmentation (VIS), Video Panoptic Segmentation (VPS), Video Object Segmentation (VOS) and Point Exemplar-guided Tracking (PET). Our unified, jointly trained model achieves state-of-the-art performance on 5/7 benchmarks spanning these four tasks, and competitive performance on the remaining two.
» Show BibTeX
@inproceedings{athar2023tarvis,
title={TarViS: A Unified Architecture for Target-based Video Segmentation},
author={Athar, Ali and Hermans, Alexander and Luiten, Jonathon and Ramanan, Deva and Leibe, Bastian},
booktitle={CVPR},
year={2023}
}
Learning 3D Human Pose Estimation from Dozens of Datasets using a Geometry-Aware Autoencoder to Bridge Between Skeleton Formats
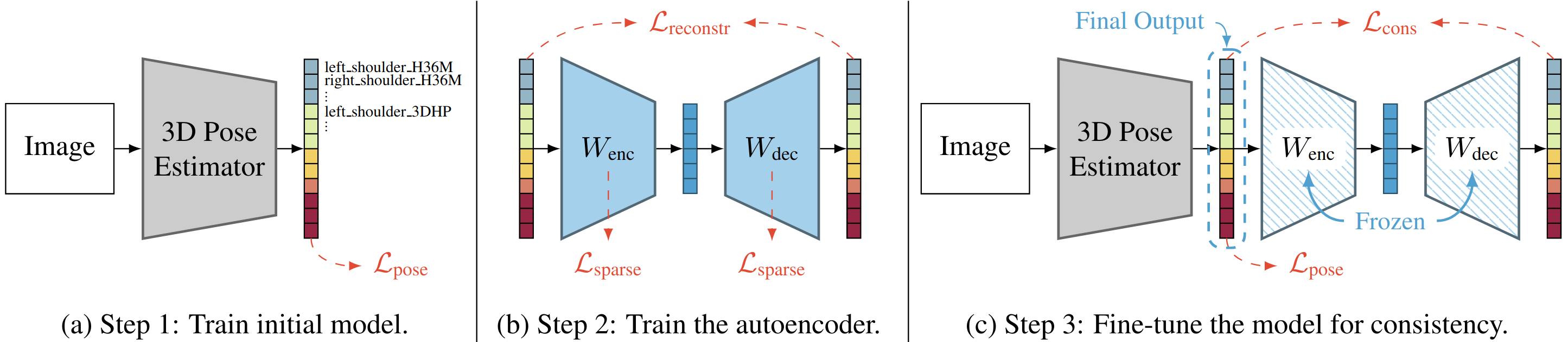
Deep learning-based 3D human pose estimation performs best when trained on large amounts of labeled data, making combined learning from many datasets an important research direction. One obstacle to this endeavor are the different skeleton formats provided by different datasets, i.e., they do not label the same set of anatomical landmarks. There is little prior research on how to best supervise one model with such discrepant labels. We show that simply using separate output heads for different skeletons results in inconsistent depth estimates and insufficient information sharing across skeletons. As a remedy, we propose a novel affine-combining autoencoder (ACAE) method to perform dimensionality reduction on the number of landmarks. The discovered latent 3D points capture the redundancy among skeletons, enabling enhanced information sharing when used for consistency regularization. Our approach scales to an extreme multi-dataset regime, where we use 28 3D human pose datasets to supervise one model, which outperforms prior work on a range of benchmarks, including the challenging 3D Poses in the Wild (3DPW) dataset. Our code and models are available for research purposes.
» Show BibTeX
@inproceedings{Sarandi23WACV,
author = {S\'ar\'andi, Istv\'an and Hermans, Alexander and Leibe, Bastian},
title = {Learning {3D} Human Pose Estimation from Dozens of Datasets using a Geometry-Aware Autoencoder to Bridge Between Skeleton Formats},
booktitle = {IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
year = {2023},
}
Mask3D for 3D Semantic Instance Segmentation

Modern 3D semantic instance segmentation approaches predominantly rely on specialized voting mechanisms followed by carefully designed geometric clustering techniques. Building on the successes of recent Transformer-based methods for object detection and image segmentation, we propose the first Transformer-based approach for 3D semantic instance segmentation. We show that we can leverage generic Transformer building blocks to directly predict instance masks from 3D point clouds. In our model called Mask3D each object instance is represented as an instance query. Using Transformer decoders, the instance queries are learned by iteratively attending to point cloud features at multiple scales. Combined with point features, the instance queries directly yield all instance masks in parallel. Mask3D has several advantages over current state-of-the-art approaches, since it neither relies on (1) voting schemes which require hand-selected geometric properties (such as centers) nor (2) geometric grouping mechanisms requiring manually-tuned hyper-parameters (e.g. radii) and (3) enables a loss that directly optimizes instance masks. Mask3D sets a new state-of-the-art on ScanNet test (+6.2 mAP), S3DIS 6-fold (+10.1 mAP), STPLS3D (+11.2 mAP) and ScanNet200 test (+12.4 mAP).
» Show BibTeX
@article{Schult23ICRA,
title = {{Mask3D for 3D Semantic Instance Segmentation}},
author = {Schult, Jonas and Engelmann, Francis and Hermans, Alexander and Litany, Or and Tang, Siyu and Leibe, Bastian},
booktitle = {{International Conference on Robotics and Automation (ICRA)}},
year = {2023}
}
Point2Vec for Self-Supervised Representation Learning on Point Clouds
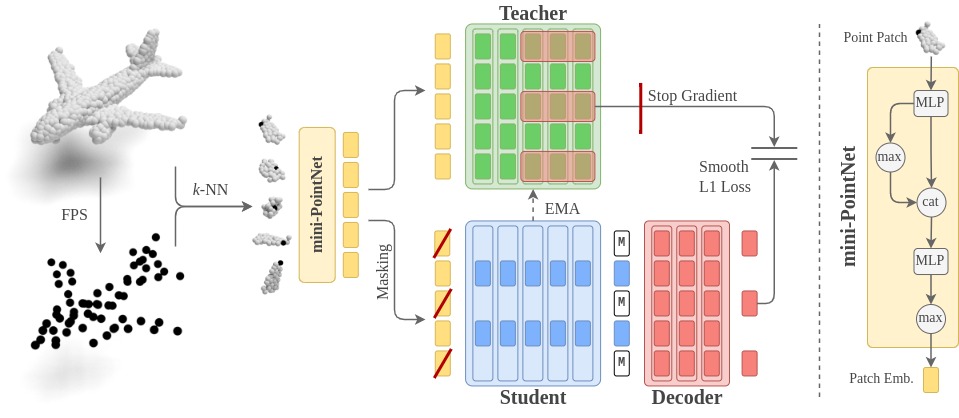
Recently, the self-supervised learning framework data2vec has shown inspiring performance for various modalities using a masked student-teacher approach. However, it remains open whether such a framework generalizes to the unique challenges of 3D point clouds.To answer this question, we extend data2vec to the point cloud domain and report encouraging results on several downstream tasks. In an in-depth analysis, we discover that the leakage of positional information reveals the overall object shape to the student even under heavy masking and thus hampers data2vec to learn strong representations for point clouds. We address this 3D-specific shortcoming by proposing point2vec, which unleashes the full potential of data2vec-like pre-training on point clouds. Our experiments show that point2vec outperforms other self-supervised methods on shape classification and few-shot learning on ModelNet40 and ScanObjectNN, while achieving competitive results on part segmentation on ShapeNetParts. These results suggest that the learned representations are strong and transferable, highlighting point2vec as a promising direction for self-supervised learning of point cloud representations.
@InProceedings{knaebel2023point2vec,
title = {Point2Vec for Self-Supervised Representation Learning on Point Clouds},
author = {Knaebel, Karim and Schult, Jonas and Hermans, Alexander and Leibe, Bastian},
journal = {German Conference on Pattern Recognition (GCPR)},
year = {2023}
}
Clicks as Queries: Interactive Transformer for Multi-instance Segmentation
Transformers have percolated into a multitude of computer vision domains including dense prediction tasks such as instance segmentation and have demonstrated strong performances. Existing transformer based segmentation approaches such as Mask2Former generate pixel-precise object masks automatically given an input image. While these methods are capable of generating high quality masks in general, they have an inherent class bias and are unable to incorporate user inputs to either segment out-of-distribution classes or to correct bad predictions. Hence, we introduce a novel module called Interactive Transformer that enables transformers to predict and refine objects based on user interactions. Subsequently, we use our Interactive Transformer to develop an interactive segmentation network that can generate mask predictions based on user clicks and thereby widen the transformer application domains within computer vision. In addition, the Interactive Transformer can make such interactive segmentation tasks more efficient by (i) imparting the ability to perform multi-instances segmentation, (ii) alleviating the need to re-compute image-level backbone features as done in existing interactive segmentation networks, and (iii) reducing the required number of user interactions by modeling a common background representation. Our transformer-based architecture outperforms the state-of-the-art interactive segmentation networks on multiple benchmark datasets.
@inproceedings{RanaMahadevan23cvprw,
title={Clicks as Queries: Interactive Transformer for Multi-instance Segmentation},
author={Rana, Amit and Mahadevan, Sabarinath and Alexander Hermans and Leibe, Bastian},
booktitle={CVPRW},
year={2023}
}
UGainS: Uncertainty Guided Anomaly Segmentation

A single unexpected object on the road can cause an accident or may lead to injuries. To prevent this, we need a reliable mechanism for finding anomalous objects on the road. This task, called anomaly segmentation, can be a stepping stone to safe and reliable autonomous driving. Current approaches tackle anomaly segmentation by assigning an anomaly score to each pixel and by grouping anomalous regions using simple heuristics. However, pixel grouping is a limiting factor when it comes to evaluating the segmentation performance of individual anomalous objects. To address the issue of grouping multiple anomaly instances into one, we propose an approach that produces accurate anomaly instance masks. Our approach centers on an out-of-distribution segmentation model for identifying uncertain regions and a strong generalist segmentation model for anomaly instances segmentation. We investigate ways to use uncertain regions to guide such a segmentation model to perform segmentation of anomalous instances. By incorporating strong object priors from a generalist model we additionally improve the per-pixel anomaly segmentation performance. Our approach outperforms current pixel-level anomaly segmentation methods, achieving an AP of 80.08% and 88.98% on the Fishyscapes Lost and Found and the RoadAnomaly validation sets respectively.
```
@inproceedings{nekrasov2023ugains,
title = {{UGainS: Uncertainty Guided Anomaly Instance Segmentation}},
author = {Nekrasov, Alexey and Hermans, Alexander and Kuhnert, Lars and Leibe, Bastian},
booktitle = {GCPR},
year = {2023}
}
```
HODOR: High-level Object Descriptors for Object Re-segmentation in Video Learned from Static Images
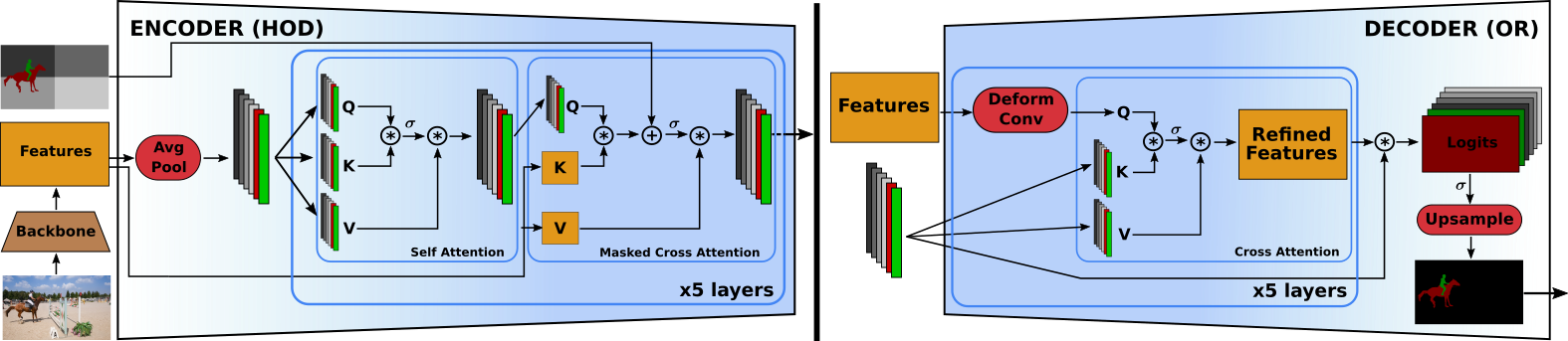
Existing state-of-the-art methods for Video Object Segmentation (VOS) learn low-level pixel-to-pixel correspondences between frames to propagate object masks across video. This requires a large amount of densely annotated video data, which is costly to annotate, and largely redundant since frames within a video are highly correlated. In light of this, we propose HODOR: a novel method that tackles VOS by effectively leveraging annotated static images for understanding object appearance and scene context. We encode object instances and scene information from an image frame into robust high-level descriptors which can then be used to re-segment those objects in different frames. As a result, HODOR achieves state-of-the-art performance on the DAVIS and YouTube-VOS benchmarks compared to existing methods trained without video annotations. Without any architectural modification, HODOR can also learn from video context around single annotated video frames by utilizing cyclic consistency, whereas other methods rely on dense, temporally consistent annotations.
@article{Athar22CVPR,
title = {{HODOR: High-level Object Descriptors for Object Re-segmentation in Video Learned from Static Images}},
author = {Athar, Ali and Luiten, Jonathon and Hermans, Alexander and Ramanan, Deva and Leibe, Bastian},
journal = {{IEEE Conference on Computer Vision and Pattern Recognition (CVPR'22)}},
year = {2022}
}
M2F3D: Mask2Former for 3D Instance Segmentation
In this work, we show that the top performing Mask2Former approach for image-based segmentation tasks works surprisingly well when adapted to the 3D scene understanding domain. Current 3D semantic instance segmentation methods rely largely on predicting centers followed by clustering approaches and little progress has been made in applying transformer-based approaches to this task. We show that with small modifications to the Mask2Former approach for 2D, we can create a 3D instance segmentation approach, without the need for highly 3D specific components or carefully hand-engineered hyperparameters. Initial experiments with our M2F3D model on the ScanNet benchmark are very promising and sets a new state-of-the-art on ScanNet test (+0.4 mAP50).
Please see our extended work Mask3D: Mask Transformer for 3D Instance Segmentation accepted at ICRA 2023.
Global Hierarchical Attention for 3D Point Cloud Analysis
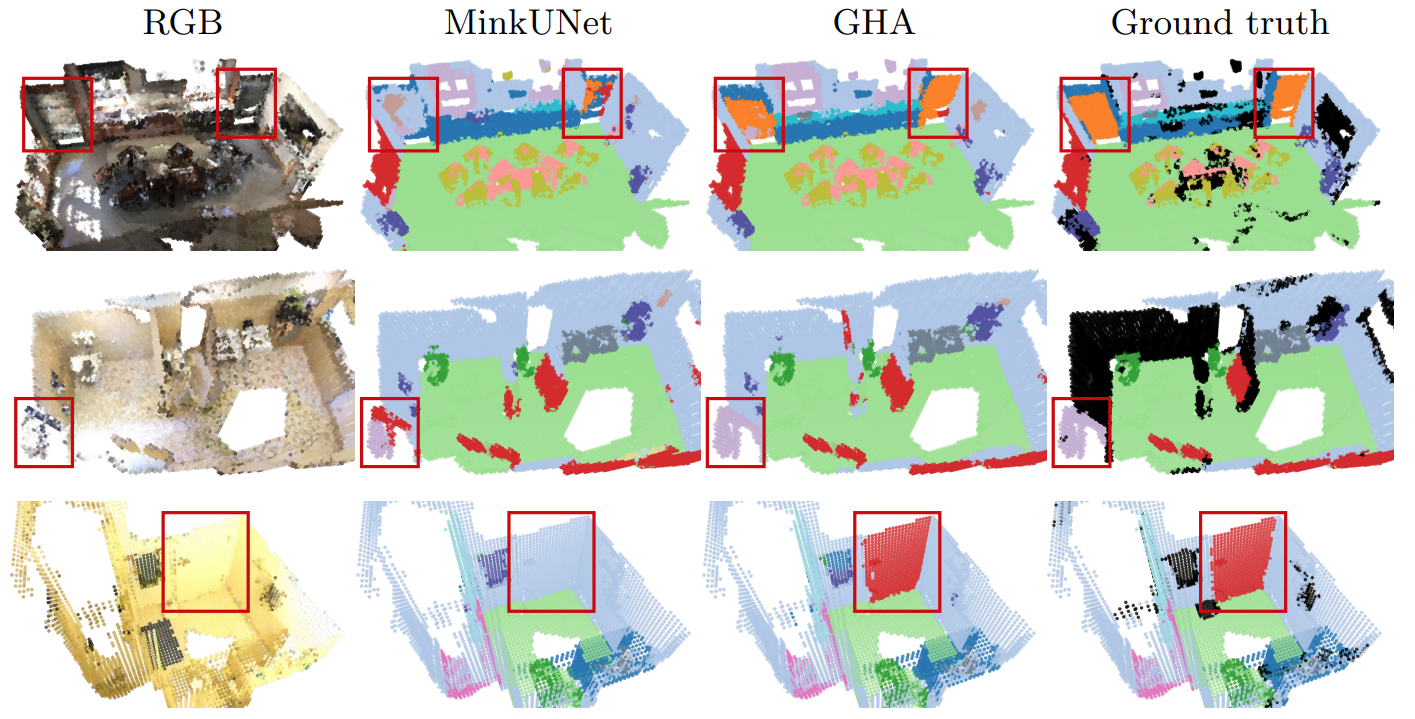
We propose a new attention mechanism, called Global Hierarchical Attention (GHA), for 3D point cloud analysis. GHA approximates the regular global dot-product attention via a series of coarsening and interpolation operations over multiple hierarchy levels. The advantage of GHA is two-fold. First, it has linear complexity with respect to the number of points, enabling the processing of large point clouds. Second, GHA inherently possesses the inductive bias to focus on spatially close points, while retaining the global connectivity among all points. Combined with a feedforward network, GHA can be inserted into many existing network architectures. We experiment with multiple baseline networks and show that adding GHA consistently improves performance across different tasks and datasets. For the task of semantic segmentation, GHA gives a +1.7% mIoU increase to the MinkowskiEngine baseline on ScanNet. For the 3D object detection task, GHA improves the CenterPoint baseline by +0.5% mAP on the nuScenes dataset, and the 3DETR baseline by +2.1% mAP25 and +1.5% mAP50 on ScanNet.
Differentiable Soft-Masked Attention
Transformers have become prevalent in computer vision due to their performance and flexibility in modelling complex operations. Of particular significance is the ‘cross-attention’ operation, which allows a vector representation (e.g. of an object in an image) to be learned by ‘attending’ to an arbitrarily sized set of input features. Recently, ‘Masked Attention’ was proposed in which a given object representation only attends to those image pixel features for which the segmentation mask of that object is active. This specialization of attention proved beneficial for various image and video segmentation tasks. In this paper, we propose another specialization of attention which enables attending over ‘soft-masks’ (those with continuous mask probabilities instead of binary values), and is also differentiable through these mask probabilities, thus allowing the mask used for attention to be learned within the network without requiring direct loss supervision. This can be useful for several applications. Specifically, we employ our ‘Differentiable Soft-Masked Attention’ for the task of Weakly Supervised Video Object Segmentation (VOS), where we develop a transformer-based network for VOS which only requires a single annotated image frame for training, but can also benefit from cycle consistency training on a video with just one annotated frame. Although there is no loss for masks in unlabeled frames, the network is still able to segment objects in those frames due to our novel attention formulation.
2D vs. 3D LiDAR-based Person Detection on Mobile Robots
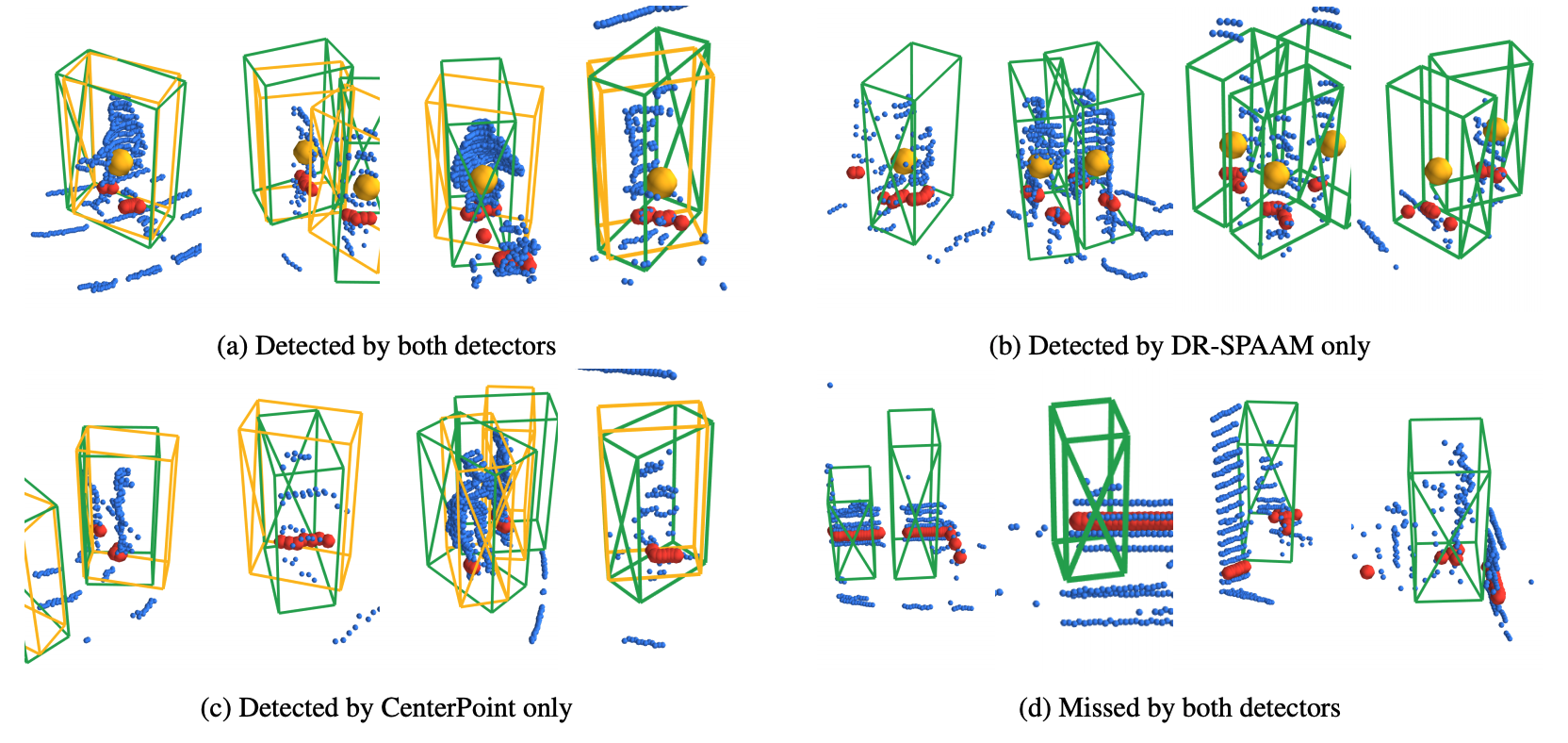
Person detection is a crucial task for mobile robots navigating in human-populated environments. LiDAR sensors are promising for this task, thanks to their accurate depth measurements and large field of view. Two types of LiDAR sensors exist: the 2D LiDAR sensors, which scan a single plane, and the 3D LiDAR sensors, which scan multiple planes, thus forming a volume. How do they compare for the task of person detection? To answer this, we conduct a series of experiments, using the public, large-scale JackRabbot dataset and the state-of-the-art 2D and 3D LiDAR-based person detectors (DR-SPAAM and CenterPoint respectively). Our experiments include multiple aspects, ranging from the basic performance and speed comparison, to more detailed analysis on localization accuracy and robustness against distance and scene clutter. The insights from these experiments highlight the strengths and weaknesses of 2D and 3D LiDAR sensors as sources for person detection, and are especially valuable for designing mobile robots that will operate in close proximity to surrounding humans (e.g. service or social robot).
Self-Supervised Person Detection in 2D Range Data using a Calibrated Camera
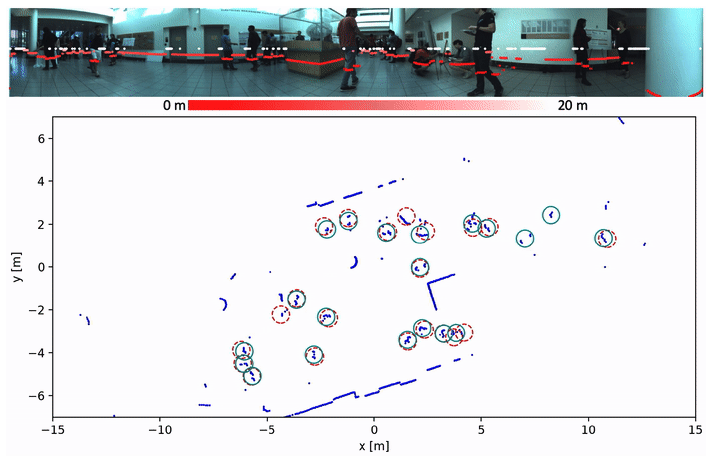
Deep learning is the essential building block of state-of-the-art person detectors in 2D range data. However, only a few annotated datasets are available for training and testing these deep networks, potentially limiting their performance when deployed in new environments or with different LiDAR models. We propose a method, which uses bounding boxes from an image-based detector (e.g. Faster R-CNN) on a calibrated camera to automatically generate training labels (called pseudo-labels) for 2D LiDAR-based person detectors. Through experiments on the JackRabbot dataset with two detector models, DROW3 and DR-SPAAM, we show that self- supervised detectors, trained or fine-tuned with pseudo-labels, outperform detectors trained using manual annotations from a different dataset. Combined with robust training techniques, the self-supervised detectors reach a performance close to the ones trained using manual annotations. Our method is an effective way to improve person detectors during deployment without any additional labeling effort, and we release our source code to support relevant robotic applications.
DR-SPAAM: A Spatial-Attention and Auto-regressive Model for Person Detection in 2D Range Data

Detecting persons using a 2D LiDAR is a challenging task due to the low information content of 2D range data. To alleviate the problem caused by the sparsity of the LiDAR points, current state-of-the-art methods fuse multiple previous scans and perform detection using the combined scans. The downside of such a backward looking fusion is that all the scans need to be aligned explicitly, and the necessary alignment operation makes the whole pipeline more expensive -- often too expensive for real-world applications. In this paper, we propose a person detection network which uses an alternative strategy to combine scans obtained at different times. Our method, Distance Robust SPatial Attention and Auto-regressive Model (DR-SPAAM), follows a forward looking paradigm. It keeps the intermediate features from the backbone network as a template and recurrently updates the template when a new scan becomes available. The updated feature template is in turn used for detecting persons currently in the scene. On the DROW dataset, our method outperforms the existing state-of-the-art, while being approximately four times faster, running at 87.2 FPS on a laptop with a dedicated GPU and at 22.6 FPS on an NVIDIA Jetson AGX embedded GPU. We release our code in PyTorch and a ROS node including pre-trained models.
Jetson project of the month for September 2020
Visual Person Understanding through Multi-Task and Multi-Dataset Learning
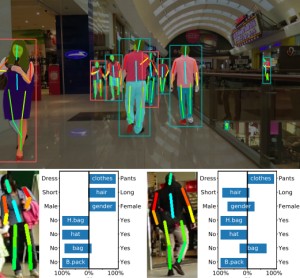
We address the problem of learning a single model for person re-identification, attribute classification, body part segmentation, and pose estimation. With predictions for these tasks we gain a more holistic understanding of persons, which is valuable for many applications. This is a classical multi-task learning problem. However, no dataset exists that these tasks could be jointly learned from. Hence several datasets need to be combined during training, which in other contexts has often led to reduced performance in the past. We extensively evaluate how the different task and datasets influence each other and how different degrees of parameter sharing between the tasks affect performance. Our final model matches or outperforms its single-task counterparts without creating significant computational overhead, rendering it highly interesting for resource-constrained scenarios such as mobile robotics.
@inproceedings{Pfeiffer19GCPR,
title = {Visual Person Understanding Through Multi-task and Multi-dataset Learning},
author = {Kilian Pfeiffer and Alexander Hermans and Istv\'{a}n S\'{a}r\'{a}ndi and Mark Weber and Bastian Leibe},
booktitle = {German Conference on Pattern Recognition (GCPR)},
date = {2019}
}
MaskLab: Instance Segmentation by Refining Object Detection with Semantic and Direction Features
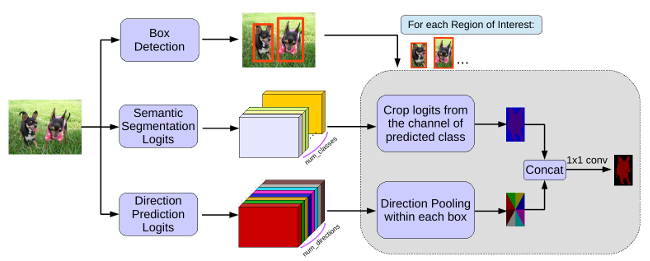
In this work, we tackle the problem of instance segmentation, the task of simultaneously solving object detection and semantic segmentation. Towards this goal, we present a model, called MaskLab, which produces three outputs: box detection, semantic segmentation, and direction prediction. Building on top of the Faster-RCNN object detector, the predicted boxes provide accurate localization of object instances. Within each region of interest, MaskLab performs foreground/background segmentation by combining semantic and direction prediction. Semantic segmentation assists the model in distinguishing between objects of different semantic classes including background, while the direction prediction, estimating each pixel's direction towards its corresponding center, allows separating instances of the same semantic class. Moreover, we explore the effect of incorporating recent successful methods from both segmentation and detection (i.e. atrous convolution and hypercolumn). Our proposed model is evaluated on the COCO instance segmentation benchmark and shows comparable performance with other state-of-art models.
@article{Chen18CVPR,
title = {{MaskLab: Instance Segmentation by Refining Object Detection with Semantic and Direction Features}},
author = {Chen, Liang-Chieh and Hermans, Alexander and Papandreou, George and Schroff, Florian and Wang, Peng and Adam, Hartwig},
journal = {{IEEE Conference on Computer Vision and Pattern Recognition (CVPR'18)}},,
year = {2018}
}
Deep Person Detection in 2D Range Data
TL;DR: Extend the DROW dataset to persons, extend the method to include short temporal context, and extensively benchmark all available methods.
Detecting humans is a key skill for mobile robots and intelligent vehicles in a large variety of applications. While the problem is well studied for certain sensory modalities such as image data, few works exist that address this detection task using 2D range data. However, a widespread sensory setup for many mobile robots in service and domestic applications contains a horizontally mounted 2D laser scanner. Detecting people from 2D range data is challenging due to the speed and dynamics of human leg motion and the high levels of occlusion and self-occlusion particularly in crowds of people. While previous approaches mostly relied on handcrafted features, we recently developed the deep learning based wheelchair and walker detector DROW. In this paper, we show the generalization to people, including small modifications that significantly boost DROW's performance. Additionally, by providing a small, fully online temporal window in our network, we further boost our score. We extend the DROW dataset with person annotations, making this the largest dataset of person annotations in 2D range data, recorded during several days in a real-world environment with high diversity. Extensive experiments with three current baseline methods indicate it is a challenging dataset, on which our improved DROW detector beats the current state-of-the-art.
@article{Beyer2018RAL,
title = {{Deep Person Detection in 2D Range Data}},
author = {Beyer, Lucas and Hermans, Alexander and Linder, Timm and Arras, Kai Oliver and Leibe, Bastian},
journal = {IEEE Robotics and Automation Letters},
volume = {3},
number = {3},
pages = {2726--2733}
year = {2018}
}
Exploring Spatial Context for 3D Semantic Segmentation of Point Clouds
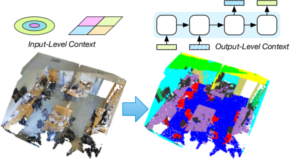
Deep learning approaches have made tremendous progress in the field of semantic segmentation over the past few years. However, most current approaches operate in the 2D image space. Direct semantic segmentation of unstructured 3D point clouds is still an open research problem. The recently proposed PointNet architecture presents an interesting step ahead in that it can operate on unstructured point clouds, achieving decent segmentation results. However, it subdivides the input points into a grid of blocks and processes each such block individually. In this paper, we investigate the question how such an architecture can be extended to incorporate larger-scale spatial context. We build upon PointNet and propose two extensions that enlarge the receptive field over the 3D scene. We evaluate the proposed strategies on challenging indoor and outdoor datasets and show improved results in both scenarios.
» Show BibTeX
@inproceedings{3dsemseg_ICCVW17,
author = {Francis Engelmann and
Theodora Kontogianni and
Alexander Hermans and
Bastian Leibe},
title = {Exploring Spatial Context for 3D Semantic Segmentation of Point Clouds},
booktitle = {{IEEE} International Conference on Computer Vision, 3DRMS Workshop, {ICCV}},
year = {2017}
}
Full-Resolution Residual Networks for Semantic Segmentation in Street Scenes
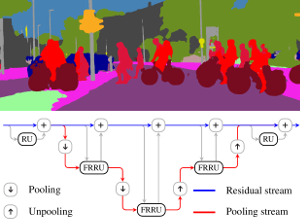
Semantic image segmentation is an essential component of modern autonomous driving systems, as an accurate understanding of the surrounding scene is crucial to navigation and action planning. Current state-of-the-art approaches in semantic image segmentation rely on pre-trained networks that were initially developed for classifying images as a whole. While these networks exhibit outstanding recognition performance (i.e., what is visible?), they lack localization accuracy (i.e., where precisely is something located?). Therefore, additional processing steps have to be performed in order to obtain pixel-accurate segmentation masks at the full image resolution. To alleviate this problem we propose a novel ResNet-like architecture that exhibits strong localization and recognition performance. We combine multi-scale context with pixel-level accuracy by using two processing streams within our network: One stream carries information at the full image resolution, enabling precise adherence to segment boundaries. The other stream undergoes a sequence of pooling operations to obtain robust features for recognition. The two streams are coupled at the full image resolution using residuals. Without additional processing steps and without pre-training, our approach achieves an intersection-over-union score of 71.8% on the Cityscapes dataset.
» Show BibTeX
@inproceedings{Pohlen2017CVPR,
title = {{Full-Resolution Residual Networks for Semantic Segmentation in Street Scenes}},
author = {Pohlen, Tobias and Hermans, Alexander and Mathias, Markus and Leibe, Bastian},
booktitle = {{IEEE Conference on Computer Vision and Pattern Recognition (CVPR'17)}},
year = {2017}
}
DROW: Real-Time Deep Learning based Wheelchair Detection in 2D Range Data
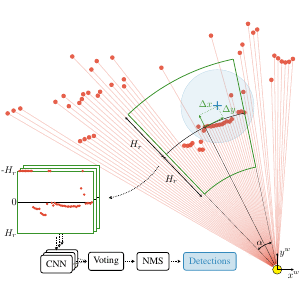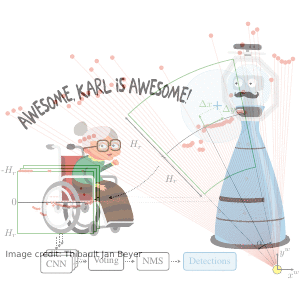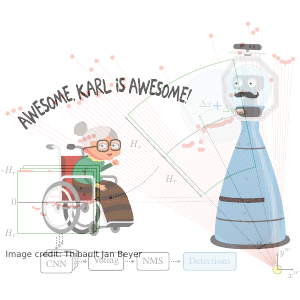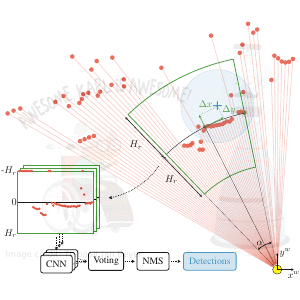
TL;DR: Collected & annotated laser detection dataset. Use window around each point to cast vote on detection center.
We introduce the DROW detector, a deep learning based detector for 2D range data. Laser scanners are lighting invariant, provide accurate range data, and typically cover a large field of view, making them interesting sensors for robotics applications. So far, research on detection in laser range data has been dominated by hand-crafted features and boosted classifiers, potentially losing performance due to suboptimal design choices. We propose a Convolutional Neural Network (CNN) based detector for this task. We show how to effectively apply CNNs for detection in 2D range data, and propose a depth preprocessing step and voting scheme that significantly improve CNN performance. We demonstrate our approach on wheelchairs and walkers, obtaining state of the art detection results. Apart from the training data, none of our design choices limits the detector to these two classes, though. We provide a ROS node for our detector and release our dataset containing 464k laser scans, out of which 24k were annotated.
» Show BibTeX
@article{BeyerHermans2016RAL,
title = {{DROW: Real-Time Deep Learning based Wheelchair Detection in 2D Range Data}},
author = {Beyer*, Lucas and Hermans*, Alexander and Leibe, Bastian},
journal = {{IEEE Robotics and Automation Letters (RA-L)}},
year = {2016}
}
In Defense of the Triplet Loss for Person Re-Identification

TL;DR: Use triplet loss, hard-mining inside mini-batch performs great, is similar to offline semi-hard mining but much more efficient.
In the past few years, the field of computer vision has gone through a revolution fueled mainly by the advent of large datasets and the adoption of deep convolutional neural networks for end-to-end learning. The person re-identification subfield is no exception to this, thanks to the notable publication of the Market-1501 and MARS datasets and several strong deep learning approaches. Unfortunately, a prevailing belief in the community seems to be that the triplet loss is inferior to using surrogate losses (classification, verification) followed by a separate metric learning step. We show that, for models trained from scratch as well as pretrained ones, using a variant of the triplet loss to perform end-to-end deep metric learning outperforms any other published method by a large margin.
@article{HermansBeyer2017Arxiv,
title = {{In Defense of the Triplet Loss for Person Re-Identification}},
author = {Hermans*, Alexander and Beyer*, Lucas and Leibe, Bastian},
journal = {arXiv preprint arXiv:1703.07737},
year = {2017}
}
Multi-Scale Object Candidates for Generic Object Tracking in Street Scenes

Most vision based systems for object tracking in urban environments focus on a limited number of important object categories such as cars or pedestrians, for which powerful detectors are available. However, practical driving scenarios contain many additional objects of interest, for which suitable detectors either do not yet exist or would be cumbersome to obtain. In this paper we propose a more general tracking approach which does not follow the often used tracking-by- detection principle. Instead, we investigate how far we can get by tracking unknown, generic objects in challenging street scenes. As such, we do not restrict ourselves to only tracking the most common categories, but are able to handle a large variety of static and moving objects. We evaluate our approach on the KITTI dataset and show competitive results for the annotated classes, even though we are not restricted to them.
@inproceedings{Osep16ICRA,
title={Multi-Scale Object Candidates for Generic Object Tracking in Street
Scenes},
author={O\v{s}ep, Aljo\v{s}a and Hermans, Alexander and Engelmann, Francis and Klostermann, Dirk and and Mathias, Markus and Leibe, Bastian},
booktitle={ICRA},
year={2016}
}
The STRANDS Project: Long-Term Autonomy in Everyday Environments

Thanks to the efforts of our community, autonomous robots are becoming capable of ever more complex and impressive feats. There is also an increasing demand for, perhaps even an expectation of, autonomous capabilities from end-users. However, much research into autonomous robots rarely makes it past the stage of a demonstration or experimental system in a controlled environment. If we don't confront the challenges presented by the complexity and dynamics of real end-user environments, we run the risk of our research becoming irrelevant or ignored by the industries who will ultimately drive its uptake. In the STRANDS project we are tackling this challenge head-on. We are creating novel autonomous systems, integrating state-of-the-art research in artificial intelligence and robotics into robust mobile service robots, and deploying these systems for long-term installations in security and care environments. To date, over four deployments, our robots have been operational for a combined duration of 2545 hours (or a little over 106 days), covering 116km while autonomously performing end-user defined tasks. In this article we present an overview of the motivation and approach of the STRANDS project, describe the technology we use to enable long, robust autonomous runs in challenging environments, and describe how our robots are able to use these long runs to improve their own performance through various forms of learning.
Superpixels: An Evaluation of the State-of-the-Art
Superpixels group perceptually similar pixels to create visually meaningful entities while heavily reducing the number of primitives. As of these properties, superpixel algorithms have received much attention since their naming in 2003. By today, publicly available and well-understood superpixel algorithms have turned into standard tools in low-level vision. As such, and due to their quick adoption in a wide range of applications, appropriate benchmarks are crucial for algorithm selection and comparison. Until now, the rapidly growing number of algorithms as well as varying experimental setups hindered the development of a unifying benchmark. We present a comprehensive evaluation of 28 state-of-the-art superpixel algorithms utilizing a benchmark focussing on fair comparison and designed to provide new and relevant insights. To this end, we explicitly discuss parameter optimization and the importance of strictly enforcing connectivity. Furthermore, by extending well-known metrics, we are able to summarize algorithm performance independent of the number of generated superpixels, thereby overcoming a major limitation of available benchmarks. Furthermore, we discuss runtime, robustness against noise, blur and affine transformations, implementation details as well as aspects of visual quality. Finally, we present an overall ranking of superpixel algorithms which redefines the state-of-the-art and enables researchers to easily select appropriate algorithms and the corresponding implementations which themselves are made publicly available as part of our benchmark at davidstutz.de/projects/superpixel-benchmark/.
@article{Stutz2016Arxiv,
title = {{Superpixels: An Evaluation of the State-of-the-Art}},
author = {David Stutz and Alexander Hermans and Bastian Leibe},
journal = {arXiv preprint arXiv:1612.01601},
year = {2016}
}
Biternion Nets: Continuous Head Pose Regression from Discrete Training Labels

TL;DR: By doing the obvious thing of encoding an angle φ as (cos φ, sin φ), we can do cool things and simplify data labeling requirements.
While head pose estimation has been studied for some time, continuous head pose estimation is still an open problem. Most approaches either cannot deal with the periodicity of angular data or require very fine-grained regression labels. We introduce biternion nets, a CNN-based approach that can be trained on very coarse regression labels and still estimate fully continuous 360° head poses. We show state-of-the-art results on several publicly available datasets. Finally, we demonstrate how easy it is to record and annotate a new dataset with coarse orientation labels in order to obtain continuous head pose estimates using our biternion nets.
» Show BibTeX
@inproceedings{Beyer2015BiternionNets,
author = {Lucas Beyer and Alexander Hermans and Bastian Leibe},
title = {Biternion Nets: Continuous Head Pose Regression from Discrete Training Labels},
booktitle = {Pattern Recognition},
publisher = {Springer},
series = {Lecture Notes in Computer Science},
volume = {9358},
pages = {157-168},
year = {2015},
isbn = {978-3-319-24946-9},
doi = {10.1007/978-3-319-24947-6_13},
ee = {http://lucasb.eyer.be/academic/biternions/biternions_gcpr15.pdf},
}
Dense 3D Semantic Mapping of Indoor Scenes from RGB-D Images
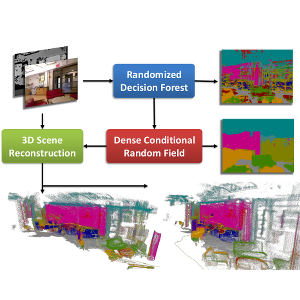
Dense semantic segmentation of 3D point clouds is a challenging task. Many approaches deal with 2D semantic segmentation and can obtain impressive results. With the availability of cheap RGB-D sensors the field of indoor semantic segmentation has seen a lot of progress. Still it remains unclear how to deal with 3D semantic segmentation in the best way. We propose a novel 2D-3D label transfer based on Bayesian updates and dense pairwise 3D Conditional Random Fields. This approach allows us to use 2D semantic segmentations to create a consistent 3D semantic reconstruction of indoor scenes. To this end, we also propose a fast 2D semantic segmentation approach based on Randomized Decision Forests. Furthermore, we show that it is not needed to obtain a semantic segmentation for every frame in a sequence in order to create accurate semantic 3D reconstructions. We evaluate our approach on both NYU Depth datasets and show that we can obtain a significant speed-up compared to other methods.
@inproceedings{Hermans14ICRA,
author = {Alexander Hermans and Georgios Floros and Bastian Leibe},
title = {{Dense 3D Semantic Mapping of Indoor Scenes from RGB-D Images}},
booktitle = {International Conference on Robotics and Automation},
year = {2014}
}
