
Profile

|
M.Sc. Idil Esen Zulfikar |
Publications
VidEoMT: Your ViT is Secretly Also a Video Segmentation Model

Existing online video segmentation models typically combine a per-frame segmenter with complex specialized tracking modules. While effective, these modules introduce significant architectural complexity and computational overhead. Recent studies suggest that plain Vision Transformer (ViT) encoders, when scaled with sufficient capacity and large-scale pre-training, can conduct accurate image segmentation without requiring specialized modules. Motivated by this observation, we propose the Video Encoder-only Mask Transformer (VidEoMT), a simple encoder-only video segmentation model that eliminates the need for dedicated tracking modules. To enable temporal modeling in an encoder-only ViT, VidEoMT introduces a lightweight query propagation mechanism that carries information across frames by reusing queries from the previous frame. To balance this with adaptability to new content, it employs a query fusion strategy that combines the propagated queries with a set of temporally-agnostic learned queries. As a result, VidEoMT attains the benefits of a tracker without added complexity, achieving competitive accuracy while being 5x--10x faster, running at up to 160 FPS with a ViT-L backbone.
@inproceedings{norouzi2026videomt,
author={Norouzi, Narges and Zulfikar, Idil and Cavagnero, Niccol\`{o} and Kerssies, Tommie and Leibe, Bastian and Dubbelman, Gijs and {de Geus}, Daan},
title={{VidEoMT: Your ViT is Secretly Also a Video Segmentation Model}},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026}
}
Interactive4D: Interactive 4D LiDAR Segmentation
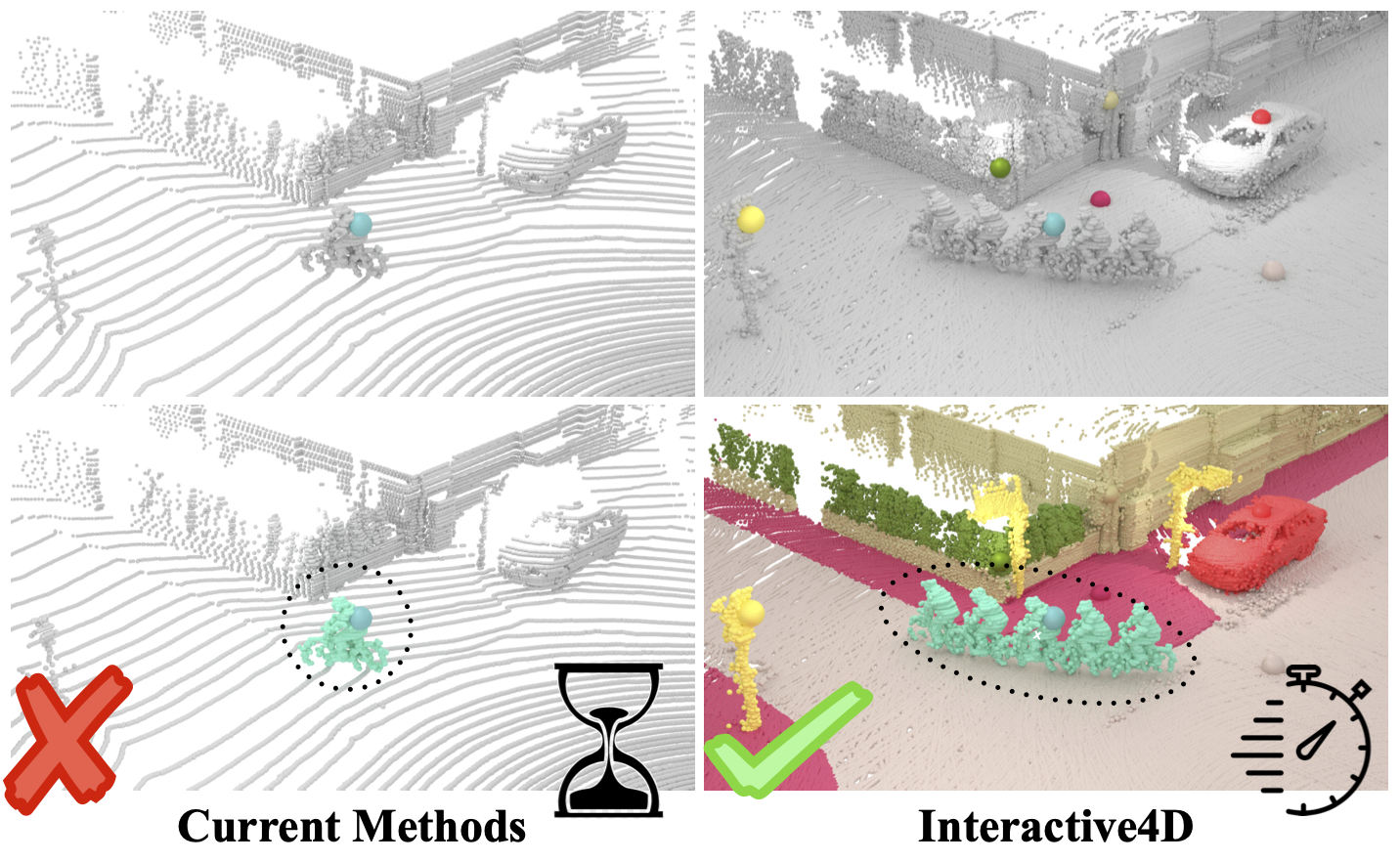
Interactive segmentation has an important role in facilitating the annotation process of future LiDAR datasets. Existing approaches sequentially segment individual objects at each LiDAR scan, repeating the process throughout the entire sequence, which is redundant and ineffective. In this work, we propose interactive 4D segmentation, a new paradigm that allows segmenting multiple objects on multiple LiDAR scans simultaneously, and Interactive4D, the first interactive 4D segmentation model that segments multiple objects on superimposed consecutive LiDAR scans in a single iteration by utilizing the sequential nature of LiDAR data. While performing interactive segmentation, our model leverages the entire space-time volume, leading to more efficient segmentation. Operating on the 4D volume, it directly provides consistent instance IDs over time and also simplifies tracking annotations. Moreover, we show that click simulations are crucial for successful model training on LiDAR point clouds. To this end, we design a click simulation strategy that is better suited for the characteristics of LiDAR data. To demonstrate its accuracy and effectiveness, we evaluate Interactive4D on multiple LiDAR datasets, where Interactive4D achieves a new state-of-the-art by a large margin.
@article{fradlin2024interactive4d,
title = {{Interactive4D: Interactive 4D LiDAR Segmentation}},
author = {Fradlin, Ilya and Zulfikar, Idil Esen and Yilmaz, Kadir and Kontogianni, Thodora and Leibe, Bastian},
journal = {arXiv preprint arXiv:2410.08206},
year = {2024}
}
Point-VOS: Pointing Up Video Object Segmentation

Current state-of-the-art Video Object Segmentation (VOS) methods rely on dense per-object mask annotations both during training and testing. This requires time-consuming and costly video annotation mechanisms. We propose a novel Point-VOS task with a spatio-temporally sparse point-wise annotation scheme that substantially reduces the annotation effort. We apply our annotation scheme to two large-scale video datasets with text descriptions and annotate over 19M points across 133K objects in 32K videos. Based on our annotations, we propose a new Point-VOS benchmark, and a corresponding point-based training mechanism, which we use to establish strong baseline results. We show that existing VOS methods can easily be adapted to leverage our point annotations during training, and can achieve results close to the fully-supervised performance when trained on pseudo-masks generated from these points. In addition, we show that our data can be used to improve models that connect vision and language, by evaluating it on the Video Narrative Grounding (VNG) task. We will make our code and annotations available at https://pointvos.github.io.
4D-StOP: Panoptic Segmentation of 4D LiDAR using Spatio-temporal Object Proposal Generation and Aggregation
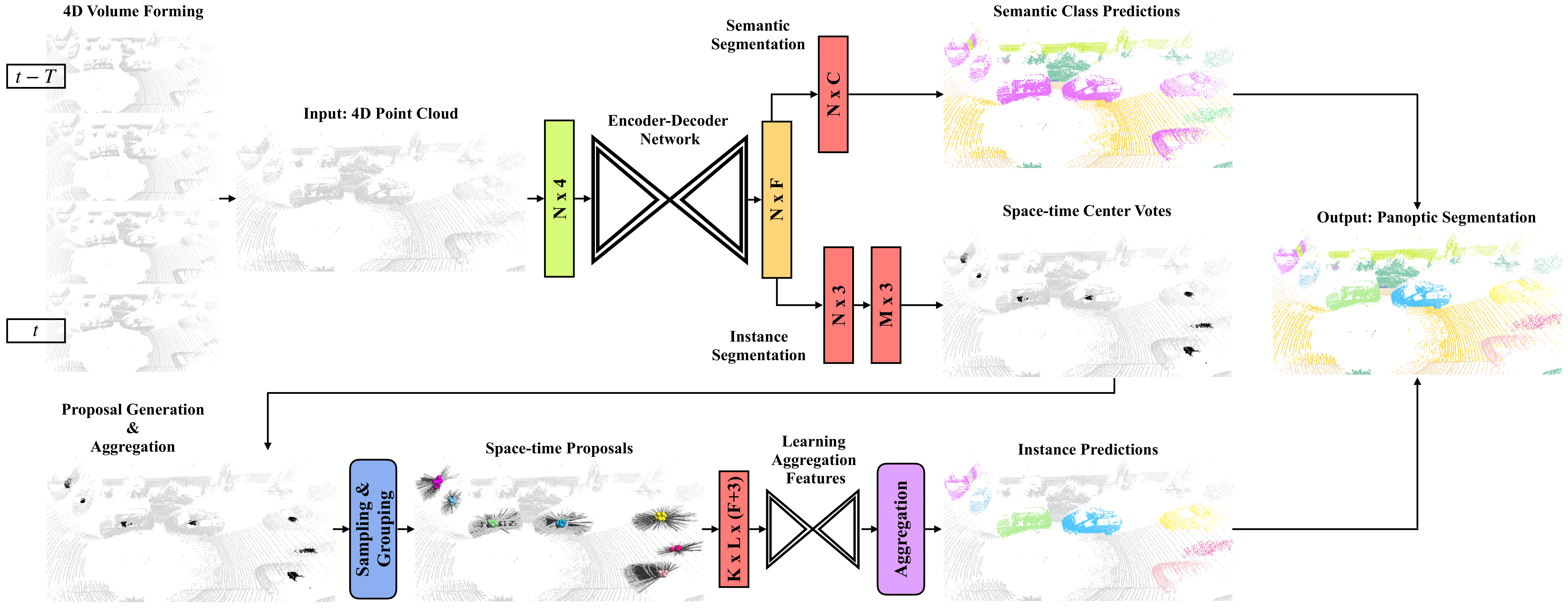
In this work, we present a new paradigm, called 4D-StOP, to tackle the task of 4D Panoptic LiDAR Segmentation. 4D-StOP first generates spatio-temporal proposals using voting-based center predictions, where each point in the 4D volume votes for a corresponding center. These tracklet proposals are further aggregated using learned geometric features. The tracklet aggregation method effectively generates a video-level 4D scene representation over the entire space-time volume. This is in contrast to existing end-to-end trainable state-of-the-art approaches which use spatio-temporal embeddings that are represented by Gaussian probability distributions. Our voting-based tracklet generation method followed by geometric feature-based aggregation generates significantly improved panoptic LiDAR segmentation quality when compared to modeling the entire 4D volume using Gaussian probability distributions. 4D-StOP achieves a new state-of-the-art when applied to the SemanticKITTI test dataset with a score of 63.9 LSTQ, which is a large (+7%) improvement compared to current best-performing end-to-end trainable methods. The code and pre-trained models are available at:https://github.com/LarsKreuzberg/4D-StOP
Opening up Open World Tracking

Tracking and detecting any object, including ones never-seen-before during model training, is a crucial but elusive capability of autonomous systems. An autonomous agent that is blind to never-seen-before objects poses a safety hazard when operating in the real world and yet this is how almost all current systems work. One of the main obstacles towards advancing tracking any object is that this task is notoriously difficult to evaluate. A benchmark that would allow us to perform an apples-to-apples comparison of existing efforts is a crucial first step towards advancing this important research field. This paper addresses this evaluation deficit and lays out the landscape and evaluation methodology for detecting and tracking both known and unknown objects in the open-world setting. We propose a new benchmark, TAO-OW: Tracking Any Object in an Open World}, analyze existing efforts in multi-object tracking, and construct a baseline for this task while highlighting future challenges. We hope to open a new front in multi-object tracking research that will hopefully bring us a step closer to intelligent systems that can operate safely in the real world.
@inproceedings{liu2022opening,
title={Opening up Open-World Tracking},
author={Liu, Yang and Zulfikar, Idil Esen and Luiten, Jonathon and Dave, Achal and Ramanan, Deva and Leibe, Bastian and O{\v{s}}ep, Aljo{\v{s}}a and Leal-Taix{\'e}, Laura},
journal={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2022}
}
UnOVOST: Unsupervised Offline Video Object Segmentation and Tracking

We address Unsupervised Video Object Segmentation (UVOS), the task of automatically generating accurate pixel masks for salient objects in a video sequence and of tracking these objects consistently through time, without any input about which objects should be tracked. Towards solving this task, we present UnOVOST (Unsupervised Offline Video Object Segmentation and Tracking) as a simple and generic algorithm which is able to track and segment a large variety of objects. This algorithm builds up tracks in a number stages, first grouping segments into short tracklets that are spatio-temporally consistent, before merging these tracklets into long-term consistent object tracks based on their visual similarity. In order to achieve this we introduce a novel tracklet-based Forest Path Cutting data association algorithm which builds up a decision forest of track hypotheses before cutting this forest into paths that form long-term consistent object tracks. When evaluating our approach on the DAVIS 2017 Unsupervised dataset we obtain state-of-the-art performance with a mean J &F score of 67.9% on the val, 58% on the test-dev and 56.4% on the test-challenge benchmarks, obtaining first place in the DAVIS 2019 Unsupervised Video Object Segmentation Challenge. UnOVOST even performs competitively with many semi-supervised video object segmentation algorithms even though it is not given any input as to which objects should be tracked and segmented.
@inproceedings{luiten2020unovost,
title={UnOVOST: Unsupervised Offline Video Object Segmentation and Tracking},
author={Luiten, Jonathon and Zulfikar, Idil Esen and Leibe, Bastian},
booktitle={Proceedings of the IEEE Winter Conference on Applications in Computer Vision},
year={2020}
}
UnOVOST: Unsupervised Offline Video Object Segmentation and Tracking for the 2019 Unsupervised DAVIS Challenge

We address Unsupervised Video Object Segmentation (UVOS), the task of automatically generating accurate pixelmasks for salient objects in a video sequence and of track-ing these objects consistently through time, without any in-formation about which objects should be tracked. Towardssolving this task, we present UnOVOST (Unsupervised Of-fline Video Object Segmentation and Tracking) as a simpleand generic algorithm which is able to track a large varietyof objects. This algorithm hierarchically builds up tracksin five stages. First, object proposal masks are generatedusing Mask R-CNN. Second, masks are sub-selected andclipped so that they do not overlap in the image domain.Third, tracklets are generated by grouping object propos-als that are strongly temporally consistent with each otherunder optical flow warping. Fourth, tracklets are mergedinto long-term consistent object tracks using their temporalconsistency and an appearance similarity metric calculatedusing an object re-identification network. Finally, the mostsalient object tracks are selected based on temporal tracklength and detection confidence scores. We evaluate ourapproach on the DAVIS 2017 Unsupervised dataset and ob-tain state-of-the-art performance with a meanJ&Fscoreof 58% on the test-dev benchmark. Our approach furtherachieves first place in the DAVIS 2019 Unsupervised VideoObject Segmentation Challenge with a mean ofJ&Fscoreof 56.4% on the test-challenge benchmark.
@article{ZulfikarLuitenUnOVOST,
title={UnOVOST: Unsupervised Offline Video Object Segmentation and Tracking for the 2019 Unsupervised DAVIS Challenge},
author={Zulfikar, Idil Esen and Luiten, Jonathon and Leibe, Bastian}
booktitle = {The 2019 DAVIS Challenge on Video Object Segmentation - CVPR Workshops},
year = {2019}
}
