
Publications
Mix3D: Out-of-Context Data Augmentation for 3D Scenes

Mix3D is a data augmentation technique for segmenting large-scale 3D scenes. Since scene context helps reasoning about object semantics, current works focus on models with large capacity and receptive fields that can fully capture the global context of an input 3D scene. However, strong contextual priors can have detrimental implications like mistaking a pedestrian crossing the street for a car. In this work, we focus on the importance of balancing global scene context and local geometry, with the goal of generalizing beyond the contextual priors in the training set. In particular, we propose a "mixing" technique which creates new training samples by combining two augmented scenes. By doing so, object instances are implicitly placed into novel out-of-context environments and therefore making it harder for models to rely on scene context alone, and instead infer semantics from local structure as well.
In the paper, we perform detailed analysis to understand the importance of global context, local structures and the effect of mixing scenes. In experiments, we show that models trained with Mix3D profit from a significant performance boost on indoor (ScanNet, S3DIS) and outdoor datasets (SemanticKITTI). Mix3D can be trivially used with any existing method, e.g., trained with Mix3D, MinkowskiNet outperforms all prior state-of-the-art methods by a significant margin on the ScanNet test benchmark 78.1 mIoU.
@inproceedings{Nekrasov213DV,
title = {{Mix3D: Out-of-Context Data Augmentation for 3D Scenes}},
author = {Nekrasov, Alexey and Schult, Jonas and Or, Litany and Leibe, Bastian and Engelmann, Francis},
booktitle = {{International Conference on 3D Vision (3DV)}},
year = {2021}
}
From Points to Multi-Object 3D Reconstruction

We propose a method to detect and reconstruct multiple 3D objects from a single RGB image. The key idea is to optimize for detection, alignment and shape jointly over all objects in the RGB image, while focusing on realistic and physically plausible reconstructions. To this end, we propose a keypoint detector that localizes objects as center points and directly predicts all object properties, including 9-DoF bounding boxes and 3D shapes -- all in a single forward pass. The proposed method formulates 3D shape reconstruction as a shape selection problem, i.e. it selects among exemplar shapes from a given database. This makes it agnostic to shape representations, which enables a lightweight reconstruction of realistic and visually-pleasing shapes based on CAD-models, while the training objective is formulated around point clouds and voxel representations. A collision-loss promotes non-intersecting objects, further increasing the reconstruction realism. Given the RGB image, the presented approach performs lightweight reconstruction in a single-stage, it is real-time capable, fully differentiable and end-to-end trainable. Our experiments compare multiple approaches for 9-DoF bounding box estimation, evaluate the novel shape-selection mechanism and compare to recent methods in terms of 3D bounding box estimation and 3D shape reconstruction quality.
@inproceedings{Engelmann21CVPR,
title = {{From Points to Multi-Object 3D Reconstruction}},
author = {Engelmann, Francis and Rematas, Konstantinos and Leibe, Bastian and Ferrari, Vittorio},
booktitle = {{IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}},
year = {2021}
}
MeTRAbs: Metric-Scale Truncation-Robust Heatmaps for Absolute 3D Human Pose Estimation

Heatmap representations have formed the basis of human pose estimation systems for many years, and their extension to 3D has been a fruitful line of recent research. This includes 2.5D volumetric heatmaps, whose X and Y axes correspond to image space and Z to metric depth around the subject. To obtain metric-scale predictions, 2.5D methods need a separate post-processing step to resolve scale ambiguity. Further, they cannot localize body joints outside the image boundaries, leading to incomplete estimates for truncated images. To address these limitations, we propose metric-scale truncation-robust (MeTRo) volumetric heatmaps, whose dimensions are all defined in metric 3D space, instead of being aligned with image space. This reinterpretation of heatmap dimensions allows us to directly estimate complete, metric-scale poses without test-time knowledge of distance or relying on anthropometric heuristics, such as bone lengths. To further demonstrate the utility our representation, we present a differentiable combination of our 3D metric-scale heatmaps with 2D image-space ones to estimate absolute 3D pose (our MeTRAbs architecture). We find that supervision via absolute pose loss is crucial for accurate non-root-relative localization. Using a ResNet-50 backbone without further learned layers, we obtain state-of-the-art results on Human3.6M, MPI-INF-3DHP and MuPoTS-3D. Our code is publicly available to facilitate further research.
Winning submission at the ECCV 2020 3D Poses in the Wild Challenge
» Show BibTeX
@article{Sarandi21metrabs,
title={{MeTRAbs:} Metric-Scale Truncation-Robust Heatmaps for Absolute {3D} Human Pose Estimation},
author={S\'ar\'andi, Istv\'an and Linder, Timm and Arras, Kai O. and Leibe, Bastian},
journal={IEEE Transactions on Biometrics, Behavior, and Identity Science},
year={2021},
volume={3},
number={1},
pages={16--30}
}
Reducing the Annotation Effort for Video Object Segmentation Datasets

For further progress in video object segmentation (VOS), larger, more diverse, and more challenging datasets will be necessary. However, densely labeling every frame with pixel masks does not scale to large datasets. We use a deep convolutional network to automatically create pseudo-labels on a pixel level from much cheaper bounding box annotations and investigate how far such pseudo-labels can carry us for training state-of-the-art VOS approaches. A very encouraging result of our study is that adding a manually annotated mask in only a single video frame for each object is sufficient to generate pseudo-labels which can be used to train a VOS method to reach almost the same performance level as when training with fully segmented videos. We use this workflow to create pixel pseudo-labels for the training set of the challenging tracking dataset TAO, and we manually annotate a subset of the validation set. Together, we obtain the new TAO-VOS benchmark, which we make publicly available at http://www.vision.rwth-aachen.de/page/taovos. While the performance of state-of-the-art methods on existing datasets starts to saturate, TAO-VOS remains very challenging for current algorithms and reveals their shortcomings.
@inproceedings{Voigtlaender21WACV,
title={Reducing the Annotation Effort for Video Object Segmentation Datasets},
author={Paul Voigtlaender and Lishu Luo and Chun Yuan and Yong Jiang and Bastian Leibe},
booktitle={WACV},
year={2021}
}
Person-MinkUNet: 3D Person Detection with LiDAR Point Cloud
In this preliminary work we attempt to apply submanifold sparse convolution to the task of 3D person detection. In particular, we present Person-MinkUNet, a single-stage 3D person detection network based on Minkowski Engine with U-Net architecture. The network achieves a 76.4% average precision (AP) on the JRDB 3D detection benchmark.
Winner of JRDB 3D detection challenge in JRDB-ACT Workshop at CVPR 2021
Self-Supervised Person Detection in 2D Range Data using a Calibrated Camera
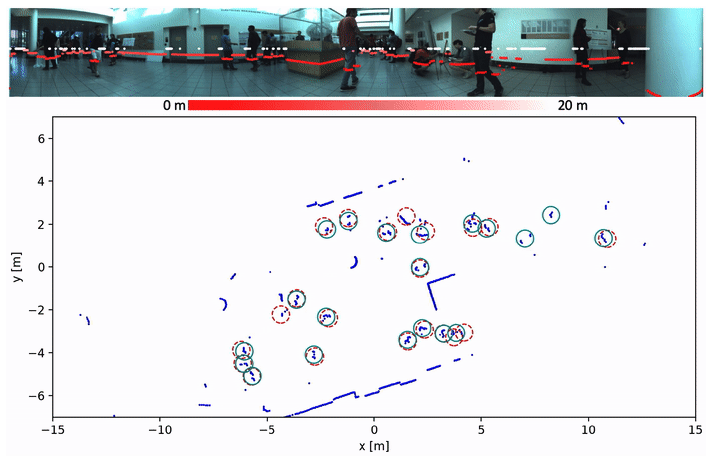
Deep learning is the essential building block of state-of-the-art person detectors in 2D range data. However, only a few annotated datasets are available for training and testing these deep networks, potentially limiting their performance when deployed in new environments or with different LiDAR models. We propose a method, which uses bounding boxes from an image-based detector (e.g. Faster R-CNN) on a calibrated camera to automatically generate training labels (called pseudo-labels) for 2D LiDAR-based person detectors. Through experiments on the JackRabbot dataset with two detector models, DROW3 and DR-SPAAM, we show that self- supervised detectors, trained or fine-tuned with pseudo-labels, outperform detectors trained using manual annotations from a different dataset. Combined with robust training techniques, the self-supervised detectors reach a performance close to the ones trained using manual annotations. Our method is an effective way to improve person detectors during deployment without any additional labeling effort, and we release our source code to support relevant robotic applications.
Previous Year (2020)
