
Publications
HOTA: A Higher Order Metric for Evaluating Multi-object Tracking
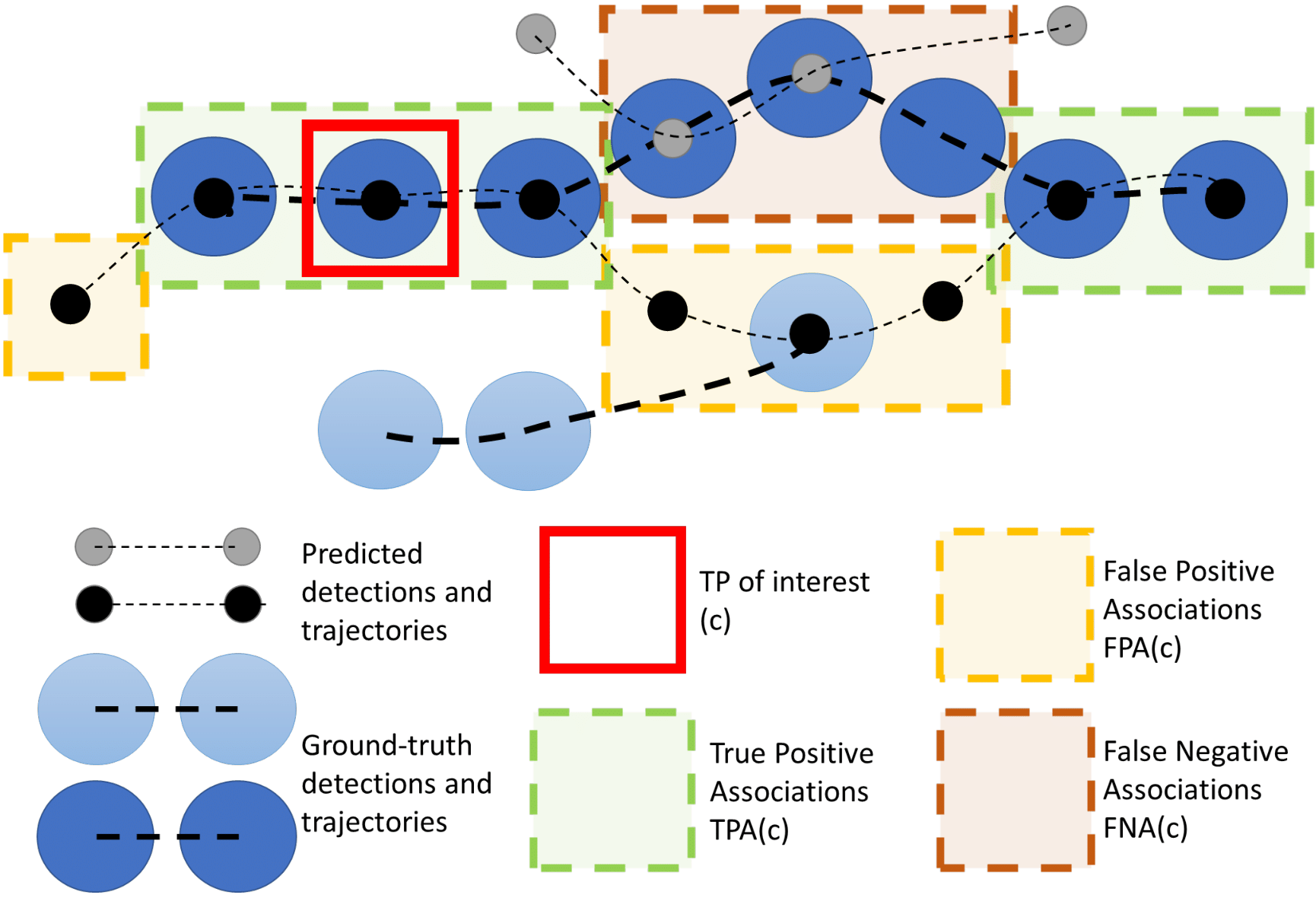
Multi-object tracking (MOT) has been notoriously difficult to evaluate. Previous metrics overemphasize the importance of either detection or association. To address this, we present a novel MOT evaluation metric, higher order tracking accuracy (HOTA), which explicitly balances the effect of performing accurate detection, association and localization into a single unified metric for comparing trackers. HOTA decomposes into a family of sub-metrics which are able to evaluate each of five basic error types separately, which enables clear analysis of tracking performance. We evaluate the effectiveness of HOTA on the MOTChallenge benchmark, and show that it is able to capture important aspects of MOT performance not previously taken into account by established metrics. Furthermore, we show HOTA scores better align with human visual evaluation of tracking performance.
@article{luiten2020IJCV,
title={HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking},
author={Luiten, Jonathon and Osep, Aljosa and Dendorfer, Patrick and Torr, Philip and Geiger, Andreas and Leal-Taix{\'e}, Laura and Leibe, Bastian},
journal={International Journal of Computer Vision},
pages={1--31},
year={2020},
publisher={Springer}
}
Continuous Adaptation for Interactive Object Segmentation by Learning from Corrections

In interactive object segmentation a user collaborates with a computer vision model to segment an object. Recent works employ convolutional neural networks for this task: Given an image and a set of corrections made by the user as input, they output a segmentation mask. These approaches achieve strong performance by training on large datasets but they keep the model parameters unchanged at test time. Instead, we recognize that user corrections can serve as sparse training examples and we propose a method that capitalizes on that idea to update the model parameters on-the-fly to the data at hand. Our approach enables the adaptation to a particular object and its background, to distributions shifts in a test set, to specific object classes, and even to large domain changes, where the imaging modality changes between training and testing. We perform extensive experiments on 8 diverse datasets and show: Compared to a model with frozen parameters, our method reduces the required corrections (i) by 9%-30% when distribution shifts are small between training and testing; (ii) by 12%-44% when specializing to a specific class; (iii) and by 60% and 77% when we completely change domain between training and testing.
» Show BibTeX
@inproceedings{Kontogianni20ECCV,
title={Continuous Adaptation for Interactive Object Segmentation by Learning from Corrections},
author={ Kontogianni, Theodora and Gygli, Michael and Uijlings, Jasper and Ferrari, Vittorio},
booktitle=ECCV,
year={2020}
}
STEm-Seg: Spatio-temporal Embeddings for Instance Segmentation in Videos

Existing methods for instance segmentation in videos typically involve multi-stage pipelines that follow the tracking-by-detection paradigm and model a video clip as a sequence of images. Multiple networks are used to detect objects in individual frames, and then associate these detections over time. Hence, these methods are often non-end-to-end trainable and highly tailored to specific tasks. In this paper, we propose a different approach that is well-suited to a variety of tasks involving instance segmentation in videos. In particular, we model a video clip as a single 3D spatio-temporal volume, and propose a novel approach that segments and tracks instances across space and time in a single stage. Our problem formulation is centered around the idea of spatio-temporal embeddings which are trained to cluster pixels belonging to a specific object instance over an entire video clip. To this end, we introduce (i) novel mixing functions that enhance the feature representation of spatio-temporal embeddings, and (ii) a single-stage, proposal-free network that can reason about temporal context. Our network is trained end-to-end to learn spatio-temporal embeddings as well as parameters required to cluster these embeddings, thus simplifying inference. Our method achieves state-of-the-art results across multiple datasets and tasks.
» Show BibTeX
@inproceedings{AtharMahadevan20ECCV,
title={STEm-Seg: Spatio-temporal Embeddings for Instance Segmentation in Videos},
author={Athar, Ali and Mahadevan, Sabarinath and O{\v{s}}ep, Aljo{\v{s}}a and Leal-Taix{\'e}, Laura and Leibe, Bastian},
booktitle=ECCV,
year={2020}
}
3D-MPA: Multi Proposal Aggregation for 3D Semantic Instance Segmentation

We present 3D-MPA, a method for instance segmentation on 3D point clouds. Given an input point cloud, we propose an object-centric approach where each point votes for its object center. We sample object proposals from the predicted object centers. Then we learn proposal features from grouped point features that voted for the same object center. A graph convolutional network introduces inter-proposal relations, providing higher-level feature learning in addition to the lower-level point features. Each proposal comprises a semantic label, a set of associated points over which we define a foreground-background mask, an objectness score and aggregation features. Previous works usually perform non-maximum-suppression (NMS) over proposals to obtain the final object detections or semantic instances. However, NMS can discard potentially correct predictions. Instead, our approach keeps all proposals and groups them together based on the learned aggregation features. We show that grouping proposals improves over NMS and outperforms previous state-of-the-art methods on the tasks of 3D object detection and semantic instance segmentation on the ScanNetV2 benchmark and the S3DIS dataset.
@inproceedings{Engelmann20CVPR,
title = {{3D-MPA: Multi Proposal Aggregation for 3D Semantic Instance Segmentation}},
author = {Engelmann, Francis and Bokeloh, Martin and Fathi, Alireza and Leibe, Bastian and Nie{\ss}ner, Matthias},
booktitle = {{IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}},
year = {2020}
}
DualConvMesh-Net: Joint Geodesic and Euclidean Convolutions on 3D Meshes
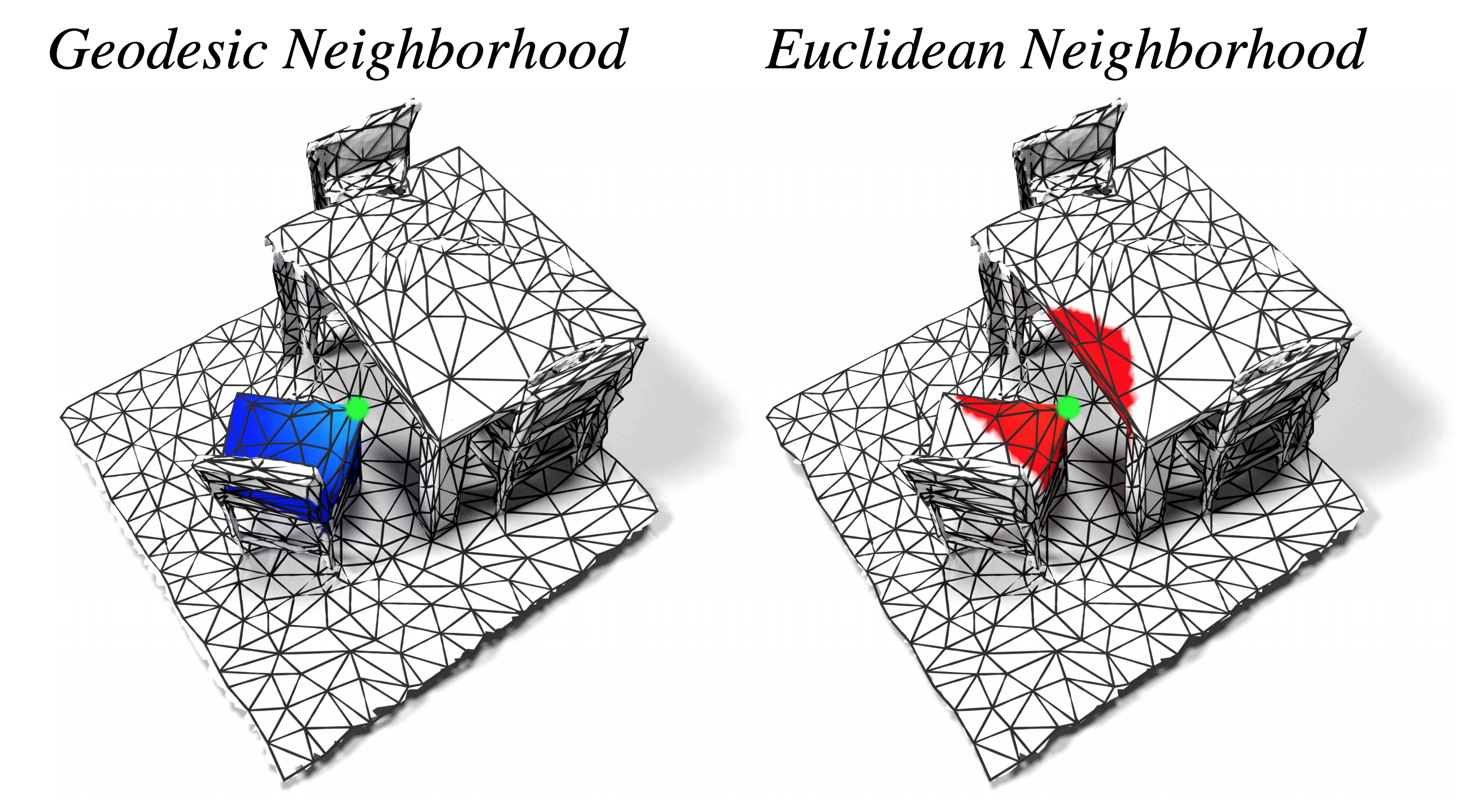
We propose DualConvMesh-Nets (DCM-Net) a family of deep hierarchical convolutional networks over 3D geometric data that combines two types of convolutions. The first type, geodesic convolutions, defines the kernel weights over mesh surfaces or graphs. That is, the convolutional kernel weights are mapped to the local surface of a given mesh. The second type, Euclidean convolutions, is independent of any underlying mesh structure. The convolutional kernel is applied on a neighborhood obtained from a local affinity representation based on the Euclidean distance between 3D points. Intuitively, geodesic convolutions can easily separate objects that are spatially close but have disconnected surfaces, while Euclidean convolutions can represent interactions between nearby objects better, as they are oblivious to object surfaces. To realize a multi-resolution architecture, we borrow well-established mesh simplification methods from the geometry processing domain and adapt them to define mesh-preserving pooling and unpooling operations. We experimentally show that combining both types of convolutions in our architecture leads to significant performance gains for 3D semantic segmentation, and we report competitive results on three scene segmentation benchmarks.
@inproceedings{Schult20CVPR,
author = {Jonas Schult* and
Francis Engelmann* and
Theodora Kontogianni and
Bastian Leibe},
title = {{DualConvMesh-Net: Joint Geodesic and Euclidean Convolutions on 3D Meshes}},
booktitle = {{IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}},
year = {2020}
}
Siam R-CNN: Visual Tracking by Re-Detection

We present Siam R-CNN, a Siamese re-detection architecture which unleashes the full power of two-stage object detection approaches for visual object tracking. We combine this with a novel tracklet-based dynamic programming algorithm, which takes advantage of re-detections of both the first-frame template and previous-frame predictions, to model the full history of both the object to be tracked and potential distractor objects. This enables our approach to make better tracking decisions, as well as to re-detect tracked objects after long occlusion. Finally, we propose a novel hard example mining strategy to improve Siam RCNN’s robustness to similar looking objects. The proposed tracker achieves the current best performance on ten tracking benchmarks, with especially strong results for long-term tracking.
@inproceedings{Voigtlaender20CVPR,
title={Siam R-CNN: Visual Tracking by Re-Detection},
author={Paul Voigtlaender and Jonathon Luiten and Philip H. S. Torr and Bastian Leibe},
year={2020},
booktitle={CVPR},
}
Making a Case for 3D Convolutions for Object Segmentation in Videos

The task of object segmentation in videos is usually accomplished by processing appearance and motion information separately using standard 2D convolutional networks, followed by a learned fusion of the two sources of information. On the other hand, 3D convolutional networks have been successfully applied for video classification tasks, but have not been leveraged as effectively to problems involving dense per-pixel interpretation of videos compared to their 2D convolutional counterparts and lag behind the aforementioned networks in terms of performance. In this work, we show that 3D CNNs can be effectively applied to dense video prediction tasks such as salient object segmentation. We propose a simple yet effective encoder-decoder network architecture consisting entirely of 3D convolutions that can be trained end-to-end using a standard cross-entropy loss. To this end, we leverage an efficient 3D encoder, and propose a 3D decoder architecture, that comprises novel 3D Global Convolution layers and 3D Refinement modules. Our approach outperforms existing state-of-the-arts by a large margin on the DAVIS'16 Unsupervised, FBMS and ViSal dataset benchmarks in addition to being faster, thus showing that our architecture can efficiently learn expressive spatio-temporal features and produce high quality video segmentation masks.
» Show BibTeX
@inproceedings{Mahadevan20BMVC,
title={Making a Case for 3D Convolutions for Object Segmentation in Videos},
author={Mahadevan, Sabarinath and Athar, Ali and O{\v{s}}ep, Aljo{\v{s}}a and Hennen, Sebastian and Leal-Taix{\'e}, Laura and Leibe, Bastian},
booktitle={BMVC},
year={2020}
}
Dilated Point Convolutions: On the Receptive Field Size of Point Convolutions on 3D Point Clouds
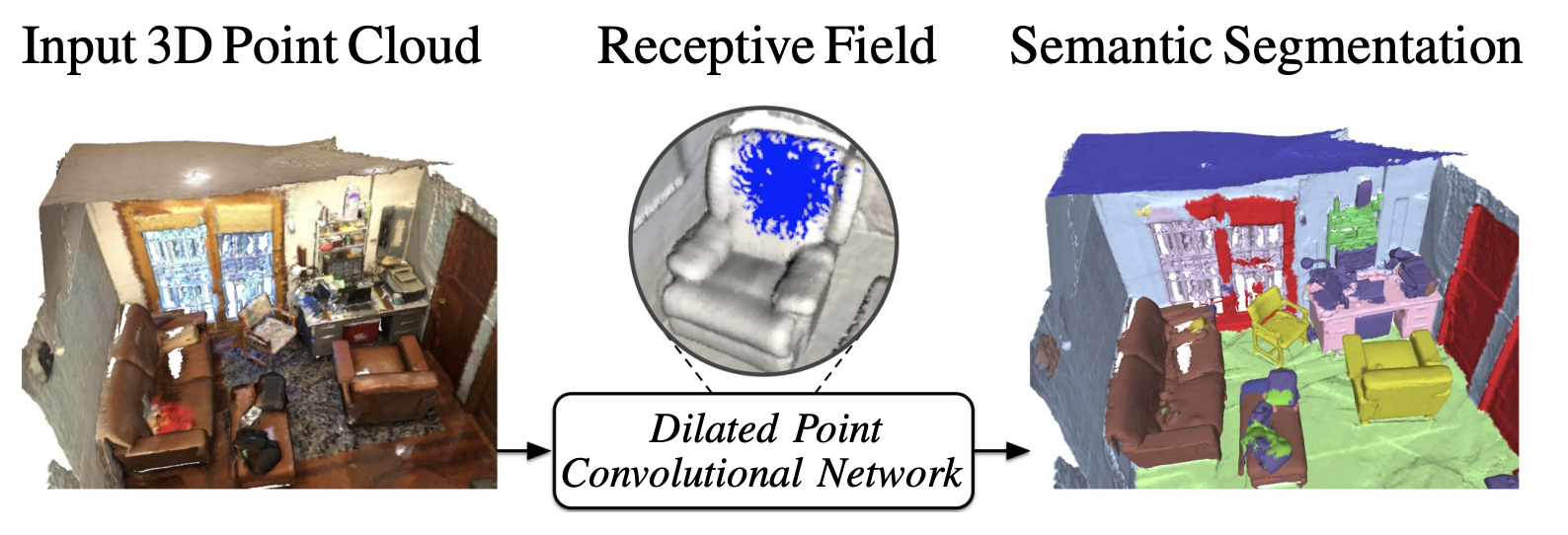
In this work, we propose Dilated Point Convolutions (DPC). In a thorough ablation study, we show that the receptive field size is directly related to the performance of 3D point cloud processing tasks, including semantic segmentation and object classification. Point convolutions are widely used to efficiently process 3D data representations such as point clouds or graphs. However, we observe that the receptive field size of recent point convolutional networks is inherently limited. Our dilated point convolutions alleviate this issue, they significantly increase the receptive field size of point convolutions. Importantly, our dilation mechanism can easily be integrated into most existing point convolutional networks. To evaluate the resulting network architectures, we visualize the receptive field and report competitive scores on popular point cloud benchmarks.
@inproceedings{Engelmann20ICRA,
author = {Engelmann, Francis and Kontogianni, Theodora and Leibe, Bastian},
title = {{Dilated Point Convolutions: On the Receptive Field Size of Point Convolutions on 3D Point Clouds}},
booktitle = {{International Conference on Robotics and Automation (ICRA)}},
year = {2020}
}
Track to Reconstruct and Reconstruct to Track

Object tracking and 3D reconstruction are often performed together, with tracking used as input for reconstruction. However, the obtained reconstructions also provide useful information for improving tracking. We propose a novel method that closes this loop, first tracking to reconstruct, and then reconstructing to track. Our approach, MOTSFusion (Multi-Object Tracking, Segmentation and dynamic object Fusion), exploits the 3D motion extracted from dynamic object reconstructions to track objects through long periods of complete occlusion and to recover missing detections. Our approach first builds up short tracklets using 2D optical flow, and then fuses these into dynamic 3D object reconstructions. The precise 3D object motion of these reconstructions is used to merge tracklets through occlusion into long-term tracks, and to locate objects when detections are missing. On KITTI, our reconstruction-based tracking reduces the number of ID switches of the initial tracklets by more than 50%, and outperforms all previous approaches for both bounding box and segmentation tracking.
@article{luiten2020track,
title={Track to Reconstruct and Reconstruct to Track},
author={Luiten, Jonathon and Fischer, Tobias and Leibe, Bastian},
journal={IEEE Robotics and Automation Letters},
volume={5},
number={2},
pages={1803--1810},
year={2020},
publisher={IEEE}
}
UnOVOST: Unsupervised Offline Video Object Segmentation and Tracking

We address Unsupervised Video Object Segmentation (UVOS), the task of automatically generating accurate pixel masks for salient objects in a video sequence and of tracking these objects consistently through time, without any input about which objects should be tracked. Towards solving this task, we present UnOVOST (Unsupervised Offline Video Object Segmentation and Tracking) as a simple and generic algorithm which is able to track and segment a large variety of objects. This algorithm builds up tracks in a number stages, first grouping segments into short tracklets that are spatio-temporally consistent, before merging these tracklets into long-term consistent object tracks based on their visual similarity. In order to achieve this we introduce a novel tracklet-based Forest Path Cutting data association algorithm which builds up a decision forest of track hypotheses before cutting this forest into paths that form long-term consistent object tracks. When evaluating our approach on the DAVIS 2017 Unsupervised dataset we obtain state-of-the-art performance with a mean J &F score of 67.9% on the val, 58% on the test-dev and 56.4% on the test-challenge benchmarks, obtaining first place in the DAVIS 2019 Unsupervised Video Object Segmentation Challenge. UnOVOST even performs competitively with many semi-supervised video object segmentation algorithms even though it is not given any input as to which objects should be tracked and segmented.
@inproceedings{luiten2020unovost,
title={UnOVOST: Unsupervised Offline Video Object Segmentation and Tracking},
author={Luiten, Jonathon and Zulfikar, Idil Esen and Leibe, Bastian},
booktitle={Proceedings of the IEEE Winter Conference on Applications in Computer Vision},
year={2020}
}
Metric-Scale Truncation-Robust Heatmaps for 3D Human Pose Estimation
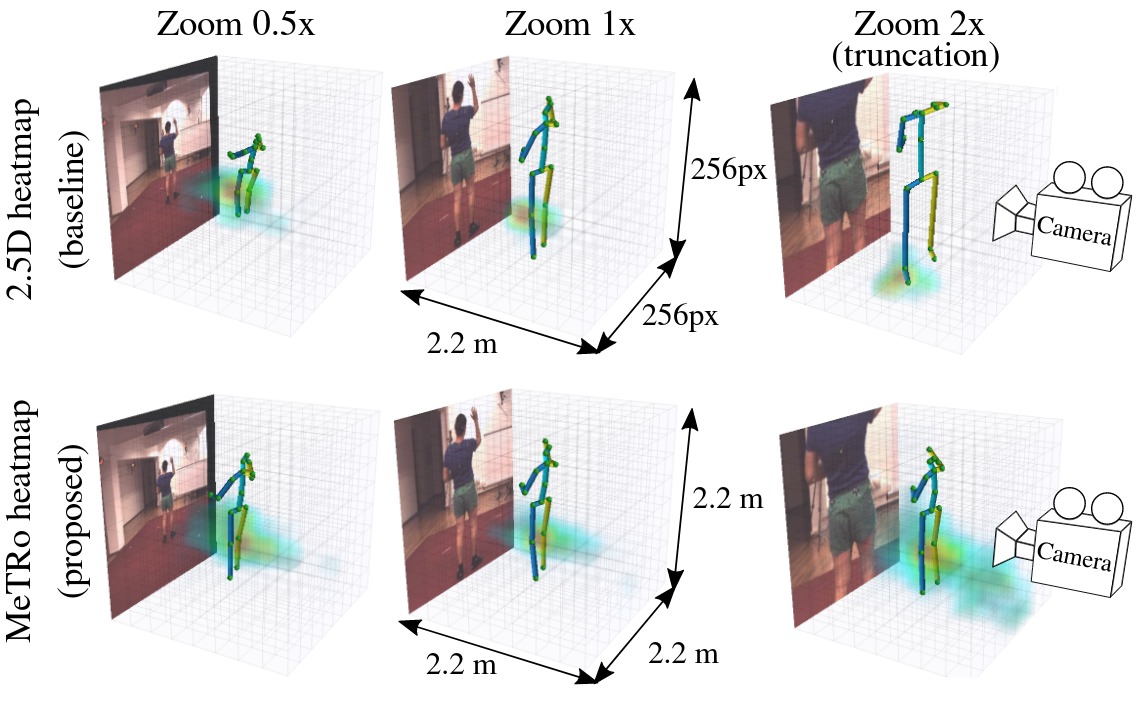
Heatmap representations have formed the basis of 2D human pose estimation systems for many years, but their generalizations for 3D pose have only recently been considered. This includes 2.5D volumetric heatmaps, whose X and Y axes correspond to image space and the Z axis to metric depth around the subject. To obtain metric-scale predictions, these methods must include a separate, explicit post-processing step to resolve scale ambiguity. Further, they cannot encode body joint positions outside of the image boundaries, leading to incomplete pose estimates in case of image truncation. We address these limitations by proposing metric-scale truncation-robust (MeTRo) volumetric heatmaps, whose dimensions are defined in metric 3D space near the subject, instead of being aligned with image space. We train a fully-convolutional network to estimate such heatmaps from monocular RGB in an end-to-end manner. This reinterpretation of the heatmap dimensions allows us to estimate complete metric-scale poses without test-time knowledge of the focal length or person distance and without relying on anthropometric heuristics in post-processing. Furthermore, as the image space is decoupled from the heatmap space, the network can learn to reason about joints beyond the image boundary. Using ResNet-50 without any additional learned layers, we obtain state-of-the-art results on the Human3.6M and MPI-INF-3DHP benchmarks. As our method is simple and fast, it can become a useful component for real-time top-down multi-person pose estimation systems. We make our code publicly available to facilitate further research.
See also the extended journal version of this paper at https://vision.rwth-aachen.de/publication/00203 (journal version preferred for citation).
» Show BibTeX
@inproceedings{Sarandi20metro,
title={Metric-Scale Truncation-Robust Heatmaps for {3D} Human Pose Estimation},
author={S\'ar\'andi, Istv\'an and Linder, Timm and Arras, Kai O. and Leibe, Bastian},
booktitle={IEEE International Conference on Automatic Face and Gesture Recognition (FG)},
year={2020}
}
Reposing Humans by Warping 3D Features
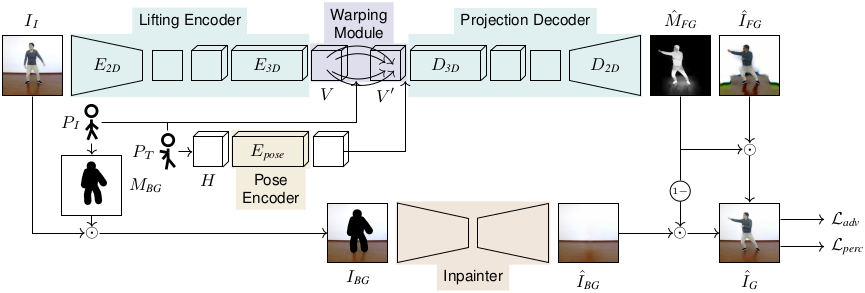
We address the problem of reposing an image of a human into any desired novel pose. This conditional image-generation task requires reasoning about the 3D structure of the human, including self-occluded body parts. Most prior works are either based on 2D representations or require fitting and manipulating an explicit 3D body mesh. Based on the recent success in deep learning-based volumetric representations, we propose to implicitly learn a dense feature volume from human images, which lends itself to simple and intuitive manipulation through explicit geometric warping. Once the latent feature volume is warped according to the desired pose change, the volume is mapped back to RGB space by a convolutional decoder. Our state-of-the-art results on the DeepFashion and the iPER benchmarks indicate that dense volumetric human representations are worth investigating in more detail.
» Show BibTeX
@inproceedings{Knoche20reposing,
author = {Markus Knoche and Istv\'an S\'ar\'andi and Bastian Leibe},
title = {Reposing Humans by Warping {3D} Features},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)},
year = {2020}
}
Single-Shot Panoptic Segmentation
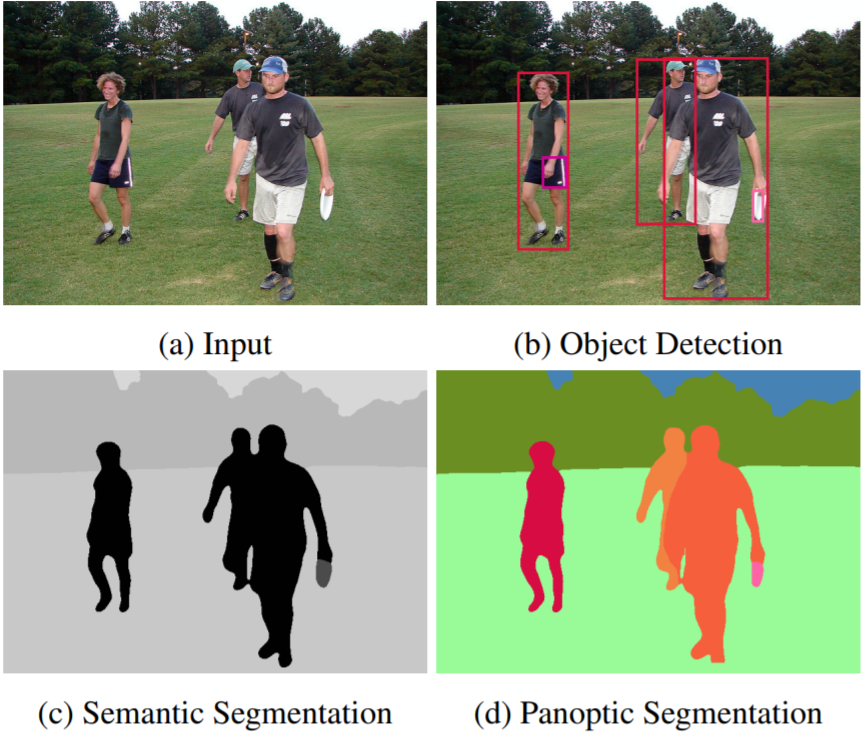
We present a novel end-to-end single-shot method that segments countable object instances (things) as well as background regions (stuff) into a non-overlapping panoptic segmentation at almost video frame rate. Current state-of-the-art methods are far from reaching video frame rate and mostly rely on merging instance segmentation with semantic background segmentation. Our approach relaxes this requirement by using an object detector but is still able to resolve inter- and intra-class overlaps to achieve a non-overlapping segmentation. On top of a shared encoder-decoder backbone, we utilize multiple branches for semantic segmentation, object detection, and instance center prediction. Finally, our panoptic head combines all outputs into a panoptic segmentation and can even handle conflicting predictions between branches as well as certain false predictions. Our network achieves 32.6% PQ on MS-COCO at 21.8 FPS, opening up panoptic segmentation to a broader field of applications.
@article{weber2019single,
title={Single-Shot Panoptic Segmentation},
author={Weber, Mark and Luiten, Jonathon and Leibe, Bastian},
journal={arXiv preprint arXiv:1911.00764},
year={2019}
}
DR-SPAAM: A Spatial-Attention and Auto-regressive Model for Person Detection in 2D Range Data

Detecting persons using a 2D LiDAR is a challenging task due to the low information content of 2D range data. To alleviate the problem caused by the sparsity of the LiDAR points, current state-of-the-art methods fuse multiple previous scans and perform detection using the combined scans. The downside of such a backward looking fusion is that all the scans need to be aligned explicitly, and the necessary alignment operation makes the whole pipeline more expensive -- often too expensive for real-world applications. In this paper, we propose a person detection network which uses an alternative strategy to combine scans obtained at different times. Our method, Distance Robust SPatial Attention and Auto-regressive Model (DR-SPAAM), follows a forward looking paradigm. It keeps the intermediate features from the backbone network as a template and recurrently updates the template when a new scan becomes available. The updated feature template is in turn used for detecting persons currently in the scene. On the DROW dataset, our method outperforms the existing state-of-the-art, while being approximately four times faster, running at 87.2 FPS on a laptop with a dedicated GPU and at 22.6 FPS on an NVIDIA Jetson AGX embedded GPU. We release our code in PyTorch and a ROS node including pre-trained models.
Jetson project of the month for September 2020
Previous Year (2019)
