
Profile

|
Dr. Lucas Beyer |
About
Busy doing too many cool things. See my homepage for more. Mostly working on these things:

Students
In Germany, it is common that PhD students closely supervise Bachelor and Master students. I have supervised the following students during my PhD:
- Kilian Yutaka Pfeiffer - student assistant (re-ID, tracking, VAEs)
- Vitaly Kurin - student assistant (head-orientation, re-ID) and master thesis (Speed up deep RL)
- Dian Tsai - master thesis (Unsupervised re-ID and continuous clustering)
- Iaroslava Grinchenko - master thesis (CNNs on head classification)
- Diego Gomez - student assistant (Tooling for the robot)
- Vojtek Novak - student assistant (Tooling for the robot)
Publications
Deep Person Detection in 2D Range Data
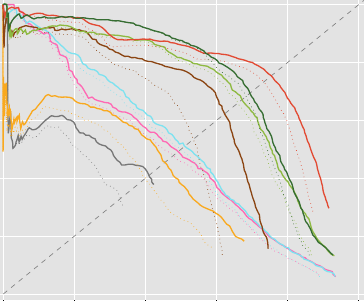
TL;DR: Extend the DROW dataset to persons, extend the method to include short temporal context, and extensively benchmark all available methods.
Detecting humans is a key skill for mobile robots and intelligent vehicles in a large variety of applications. While the problem is well studied for certain sensory modalities such as image data, few works exist that address this detection task using 2D range data. However, a widespread sensory setup for many mobile robots in service and domestic applications contains a horizontally mounted 2D laser scanner. Detecting people from 2D range data is challenging due to the speed and dynamics of human leg motion and the high levels of occlusion and self-occlusion particularly in crowds of people. While previous approaches mostly relied on handcrafted features, we recently developed the deep learning based wheelchair and walker detector DROW. In this paper, we show the generalization to people, including small modifications that significantly boost DROW's performance. Additionally, by providing a small, fully online temporal window in our network, we further boost our score. We extend the DROW dataset with person annotations, making this the largest dataset of person annotations in 2D range data, recorded during several days in a real-world environment with high diversity. Extensive experiments with three current baseline methods indicate it is a challenging dataset, on which our improved DROW detector beats the current state-of-the-art.
@article{Beyer2018RAL,
title = {{Deep Person Detection in 2D Range Data}},
author = {Beyer, Lucas and Hermans, Alexander and Linder, Timm and Arras, Kai Oliver and Leibe, Bastian},
journal = {IEEE Robotics and Automation Letters},
volume = {3},
number = {3},
pages = {2726--2733}
year = {2018}
}
Detection-Tracking for Efficient Person Analysis: The DetTA Pipeline

TL;DR: Detection+Tracking+{head orientation,skeleton} analysis. Smooth per-track enables filtering outliers as well as a "free flight" mode where expensive analysis modules are run with a stride, dramatically increasing runtime performance at almost no loss of prediction quality.
In the past decade many robots were deployed in the wild, and people detection and tracking is an important component of such deployments. On top of that, one often needs to run modules which analyze persons and extract higher level attributes such as age and gender, or dynamic information like gaze and pose. The latter ones are especially necessary for building a reactive, social robot-person interaction.
In this paper, we combine those components in a fully modular detection-tracking-analysis pipeline, called DetTA. We investigate the benefits of such an integration on the example of head and skeleton pose, by using the consistent track ID for a temporal filtering of the analysis modules’ observations, showing a slight improvement in a challenging real-world scenario. We also study the potential of a so-called “free-flight” mode, where the analysis of a person attribute only relies on the filter’s predictions for certain frames. Here, our study shows that this boosts the runtime dramatically, while the prediction quality remains stable. This insight is especially important for reducing power consumption and sharing precious (GPU-)memory when running many analysis components on a mobile platform, especially so in the era of expensive deep learning methods.
@article{BreuersBeyer2018Arxiv,
title = {{Detection-Tracking for Efficient Person Analysis: The DetTA Pipeline}},
author = {Breuers*, Stefan and Beyer*, Lucas and Rafi, Umer and Leibe, Bastian},
journal = {arXiv preprint arXiv:TBD},
year = {2018}
}
DROW: Real-Time Deep Learning based Wheelchair Detection in 2D Range Data
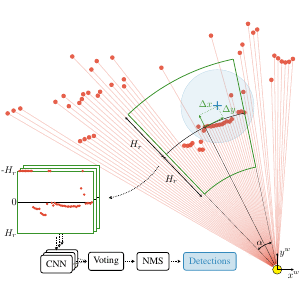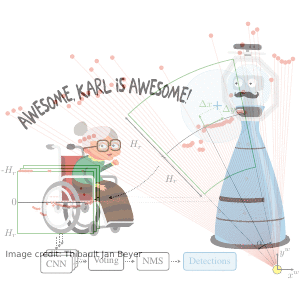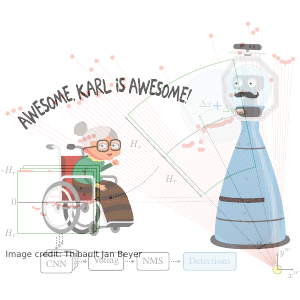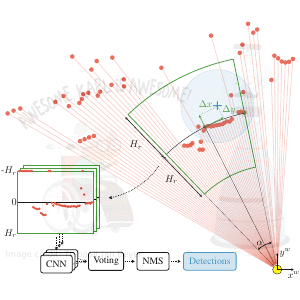
TL;DR: Collected & annotated laser detection dataset. Use window around each point to cast vote on detection center.
We introduce the DROW detector, a deep learning based detector for 2D range data. Laser scanners are lighting invariant, provide accurate range data, and typically cover a large field of view, making them interesting sensors for robotics applications. So far, research on detection in laser range data has been dominated by hand-crafted features and boosted classifiers, potentially losing performance due to suboptimal design choices. We propose a Convolutional Neural Network (CNN) based detector for this task. We show how to effectively apply CNNs for detection in 2D range data, and propose a depth preprocessing step and voting scheme that significantly improve CNN performance. We demonstrate our approach on wheelchairs and walkers, obtaining state of the art detection results. Apart from the training data, none of our design choices limits the detector to these two classes, though. We provide a ROS node for our detector and release our dataset containing 464k laser scans, out of which 24k were annotated.
» Show BibTeX
@article{BeyerHermans2016RAL,
title = {{DROW: Real-Time Deep Learning based Wheelchair Detection in 2D Range Data}},
author = {Beyer*, Lucas and Hermans*, Alexander and Leibe, Bastian},
journal = {{IEEE Robotics and Automation Letters (RA-L)}},
year = {2016}
}
Towards a Principled Integration of Multi-Camera Re-Identification and Tracking through Optimal Bayes Filters
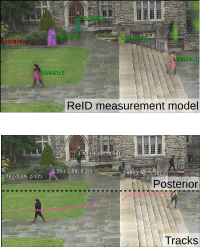
TL;DR: Explorative paper. Learn a Triplet-ReID net, embed the full image. Keep embeddings of known tracks, correlate them with image embeddings and use that as measurement model in a Bayesian filtering tracker. MOT score is mediocre, but framework is theoretically pleasing.
With the rise of end-to-end learning through deep learning, person detectors and re-identification (ReID) models have recently become very strong. Multi-camera multi-target (MCMT) tracking has not fully gone through this transformation yet. We intend to take another step in this direction by presenting a theoretically principled way of integrating ReID with tracking formulated as an optimal Bayes filter. This conveniently side-steps the need for data-association and opens up a direct path from full images to the core of the tracker. While the results are still sub-par, we believe that this new, tight integration opens many interesting research opportunities and leads the way towards full end-to-end tracking from raw pixels.
@article{BeyerBreuers2017Arxiv,
author = {Lucas Beyer and
Stefan Breuers and
Vitaly Kurin and
Bastian Leibe},
title = {{Towards a Principled Integration of Multi-Camera Re-Identification
and Tracking through Optimal Bayes Filters}},
journal = {{2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)}},
year = {2017},
pages ={1444-1453},
}
In Defense of the Triplet Loss for Person Re-Identification

TL;DR: Use triplet loss, hard-mining inside mini-batch performs great, is similar to offline semi-hard mining but much more efficient.
In the past few years, the field of computer vision has gone through a revolution fueled mainly by the advent of large datasets and the adoption of deep convolutional neural networks for end-to-end learning. The person re-identification subfield is no exception to this, thanks to the notable publication of the Market-1501 and MARS datasets and several strong deep learning approaches. Unfortunately, a prevailing belief in the community seems to be that the triplet loss is inferior to using surrogate losses (classification, verification) followed by a separate metric learning step. We show that, for models trained from scratch as well as pretrained ones, using a variant of the triplet loss to perform end-to-end deep metric learning outperforms any other published method by a large margin.
@article{HermansBeyer2017Arxiv,
title = {{In Defense of the Triplet Loss for Person Re-Identification}},
author = {Hermans*, Alexander and Beyer*, Lucas and Leibe, Bastian},
journal = {arXiv preprint arXiv:1703.07737},
year = {2017}
}
The STRANDS Project: Long-Term Autonomy in Everyday Environments

Thanks to the efforts of our community, autonomous robots are becoming capable of ever more complex and impressive feats. There is also an increasing demand for, perhaps even an expectation of, autonomous capabilities from end-users. However, much research into autonomous robots rarely makes it past the stage of a demonstration or experimental system in a controlled environment. If we don't confront the challenges presented by the complexity and dynamics of real end-user environments, we run the risk of our research becoming irrelevant or ignored by the industries who will ultimately drive its uptake. In the STRANDS project we are tackling this challenge head-on. We are creating novel autonomous systems, integrating state-of-the-art research in artificial intelligence and robotics into robust mobile service robots, and deploying these systems for long-term installations in security and care environments. To date, over four deployments, our robots have been operational for a combined duration of 2545 hours (or a little over 106 days), covering 116km while autonomously performing end-user defined tasks. In this article we present an overview of the motivation and approach of the STRANDS project, describe the technology we use to enable long, robust autonomous runs in challenging environments, and describe how our robots are able to use these long runs to improve their own performance through various forms of learning.
Biternion Nets: Continuous Head Pose Regression from Discrete Training Labels

TL;DR: By doing the obvious thing of encoding an angle φ as (cos φ, sin φ), we can do cool things and simplify data labeling requirements.
While head pose estimation has been studied for some time, continuous head pose estimation is still an open problem. Most approaches either cannot deal with the periodicity of angular data or require very fine-grained regression labels. We introduce biternion nets, a CNN-based approach that can be trained on very coarse regression labels and still estimate fully continuous 360° head poses. We show state-of-the-art results on several publicly available datasets. Finally, we demonstrate how easy it is to record and annotate a new dataset with coarse orientation labels in order to obtain continuous head pose estimates using our biternion nets.
» Show BibTeX
@inproceedings{Beyer2015BiternionNets,
author = {Lucas Beyer and Alexander Hermans and Bastian Leibe},
title = {Biternion Nets: Continuous Head Pose Regression from Discrete Training Labels},
booktitle = {Pattern Recognition},
publisher = {Springer},
series = {Lecture Notes in Computer Science},
volume = {9358},
pages = {157-168},
year = {2015},
isbn = {978-3-319-24946-9},
doi = {10.1007/978-3-319-24947-6_13},
ee = {http://lucasb.eyer.be/academic/biternions/biternions_gcpr15.pdf},
}
SPENCER: A Socially Aware Service Robot for Passenger Guidance and Help in Busy Airports

We present an ample description of a socially compliant mobile robotic platform, which is developed in the EU-funded project SPENCER. The purpose of this robot is to assist, inform and guide passengers in large and busy airports. One particular aim is to bring travellers of connecting flights conveniently and efficiently from their arrival gate to the passport control. The uniqueness of the project stems from the strong demand of service robots for this application with a large potential impact for the aviation industry on one side, and on the other side from the scientific advancements in social robotics, brought forward and achieved in SPENCER. The main contributions of SPENCER are novel methods to perceive, learn, and model human social behavior and to use this knowledge to plan appropriate actions in real- time for mobile platforms. In this paper, we describe how the project advances the fields of detection and tracking of individuals and groups, recognition of human social relations and activities, normative human behavior learning, socially-aware task and motion planning, learning socially annotated maps, and conducting empir- ical experiments to assess socio-psychological effects of normative robot behaviors.
@article{triebel2015spencer,
title={SPENCER: a socially aware service robot for passenger guidance and help in busy airports},
author={Triebel, Rudolph and Arras, Kai and Alami, Rachid and Beyer, Lucas and Breuers, Stefan and Chatila, Raja and Chetouani, Mohamed and Cremers, Daniel and Evers, Vanessa and Fiore, Michelangelo and Hung, Hayley and Islas Ramírez, Omar A. and Joosse, Michiel and Khambhaita, Harmish and Kucner, Tomasz and Leibe, Bastian and Lilienthal, Achim J. and Linder, Timm and Lohse, Manja and Magnusson, Martin and Okal, Billy and Palmieri, Luigi and Rafi, Umer and Rooij, Marieke van and Zhang, Lu},
journal={Field and Service Robotics (FSR)
year={2015},
publisher={University of Toronto}
}
Streaming Data from HDD to GPUs for Sustained Peak Performance
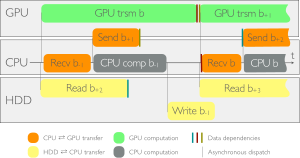
In the context of the genome-wide association studies (GWAS), one has to solve long sequences of generalized least-squares problems; such a task has two limiting factors: execution time --often in the range of days or weeks-- and data management --data sets in the order of Terabytes. We present an algorithm that obviates both issues. By pipelining the computation, and thanks to a sophisticated transfer strategy, we stream data from hard disk to main memory to GPUs and achieve sustained peak performance; with respect to a highly-optimized CPU implementation, our algorithm shows a speedup of 2.6x. Moreover, the approach lends itself to multiple GPUs and attains almost perfect scalability. When using 4 GPUs, we observe speedups of 9x over the aforementioned implementation, and 488x over a widespread biology library.
@inproceedings{Beyer2013GWAS,
author = {Lucas Beyer and Paolo Bientinesi},
title = {Streaming Data from HDD to GPUs for Sustained Peak Performance},
booktitle = {Euro-Par},
publisher = {Springer},
series = {Lecture Notes in Computer Science},
volume = {8097},
pages = {788-799},
year = {2013},
isbn = {3642400477},
ee = {http://arxiv.org/abs/1302.4332},
}
Exploiting Graphics Adapters for Computational Biology
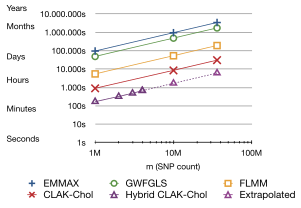
Accelerate Genome-Wide Association Studies (GWAS) by performing the most demanding computation on the GPU in a batched, streamed fashion. Involves huge data size (terabytes), streaming, asynchronicity, parallel computation and some more buzzwords.
@MastersThesis{Beyer2012GWAS,
author = {Lucas Beyer},
title = {{Exploiting Graphics Adapters for Computational Biology}},
school = {RWTH Aachen (AICES)},
address = {Aachen, Germany},
year = {2012},
}
