
Welcome







Welcome to the Computer Vision Group at RWTH Aachen University!
The Computer Vision group has been established at RWTH Aachen University in context with the Cluster of Excellence "UMIC - Ultra High-Speed Mobile Information and Communication" and is associated with the Chair Computer Sciences 8 - Computer Graphics, Computer Vision, and Multimedia. The group focuses on computer vision applications for mobile devices and robotic or automotive platforms. Our main research areas are visual object recognition, tracking, self-localization, 3D reconstruction, and in particular combinations between those topics.
We offer lectures and seminars about computer vision and machine learning.
You can browse through all our publications and the projects we are working on.
Important information for the Wintersemester 2023/2024: Unfortunately the following lectures are not offered in this semester: a) Computer Vision 2 b) Advanced Machine Learning
News
| • |
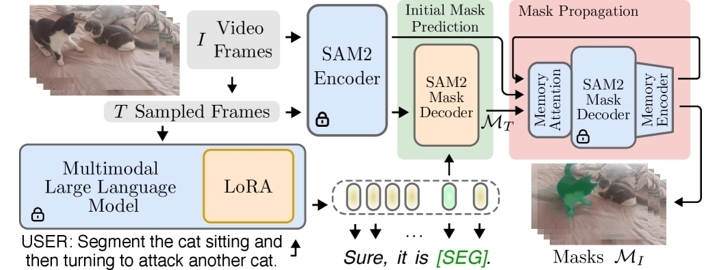
ICCV'25 Our paper DONUT: A Decoder-Only Model for Trajectory Prediction was accepted at the 2025 International Conference on Computer Vision (ICCV)! Our project: Sa2VA-i: Improving Sa2VA Results with Consistent Training and Inference achieves 3rd Place of LSVOS Workshop, MeViS Track. |
Oct. 1, 2025 |
| • |
RO-MAN'25 Our paper How do Foundation Models Compare to Skeleton-Based Approaches for Gesture Recognition in Human-Robot Interaction? has been accepted! |
June 12, 2025 |
| • |
CVPR'25 We have two papers accepted at Conference on Computer Vision and Pattern Recognition (CVPR) 2025! |
May 5, 2025 |
| • |
ICRA'25 We have four papers at the IEEE International Conference on Robotics and Automation (ICRA). See you all in Atlanta! |
Feb. 20, 2025 |
| • |
WACV'25 Our work "Fine-Tuning Image-Conditional Diffusion Models is Easier than You Think" has been accepted at WACV'25. |
Nov. 18, 2024 |
| • |
IROS'24 Our work "Look Gauss, No Pose: Novel View Synthesis using Gaussian Splatting without Accurate Pose Initialization" has been accepted at IROS'24. |
July 30, 2024 |
Recent Publications
 DINO in the Room: Leveraging 2D Foundation Models for 3D Segmentation 2026 International Conference on 3D Vision (3DV) Vision foundation models (VFMs) trained on large-scale image datasets provide high-quality features that have significantly advanced 2D visual recognition. However, their potential in 3D scene segmentation remains largely untapped, despite the common availability of 2D images alongside 3D point cloud datasets. While significant research has been dedicated to 2D-3D fusion, recent state-of-the-art 3D methods predominantly focus on 3D data, leaving the integration of VFMs into 3D models underexplored. In this work, we challenge this trend by introducing DITR, a generally applicable approach that extracts 2D foundation model features, projects them to 3D, and finally injects them into a 3D point cloud segmentation model. DITR achieves state-of-the-art results on both indoor and outdoor 3D semantic segmentation benchmarks. To enable the use of VFMs even when images are unavailable during inference, we additionally propose to pretrain 3D models by distilling 2D foundation models. By initializing the 3D backbone with knowledge distilled from 2D VFMs, we create a strong basis for downstream 3D segmentation tasks, ultimately boosting performance across various datasets. 
|
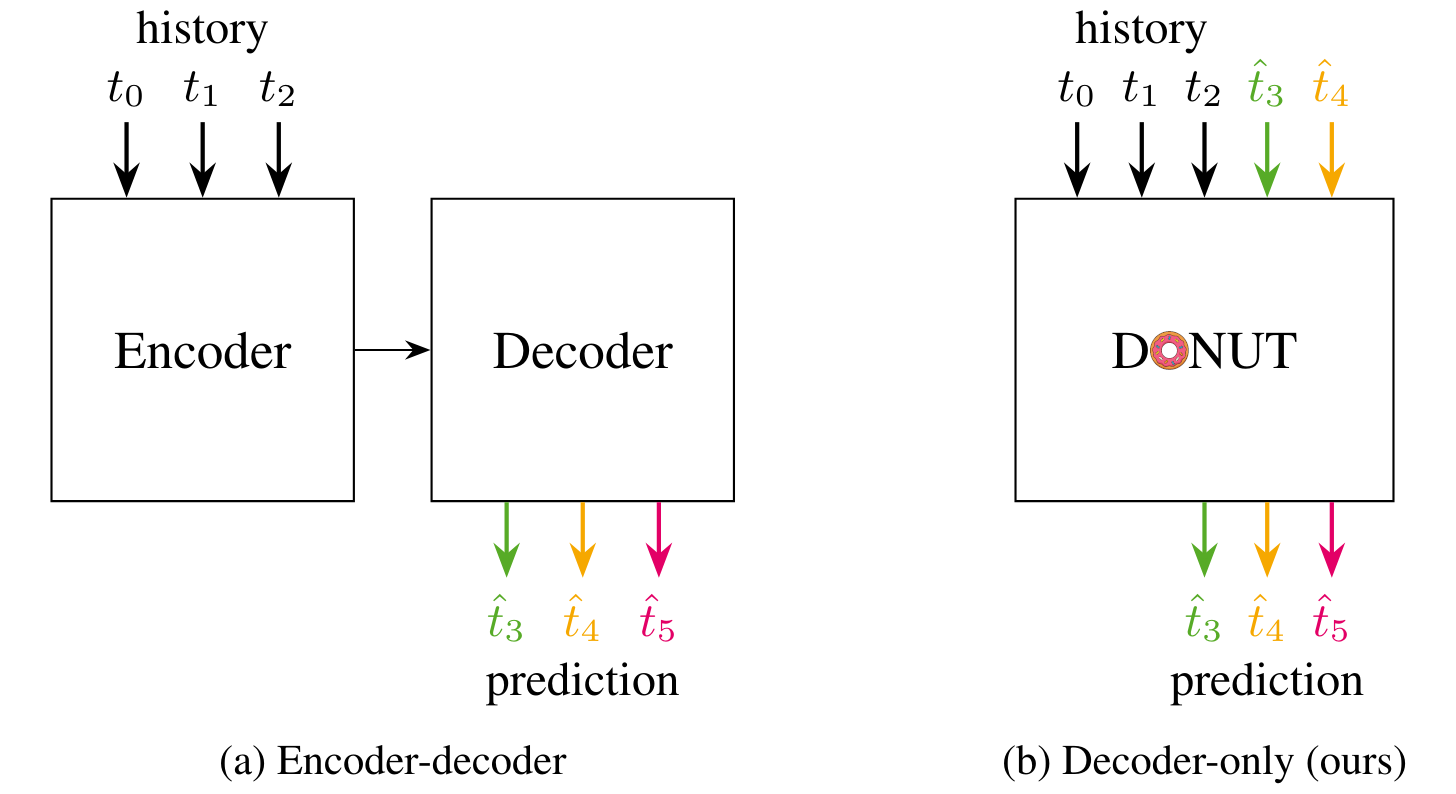 DONUT: A Decoder-Only Model for Trajectory Prediction International Conference on Computer Vision (ICCV) 2025 Predicting the motion of other agents in a scene is highly relevant for autonomous driving, as it allows a self-driving car to anticipate. Inspired by the success of decoder-only models for language modeling, we propose DONUT, a Decoder-Only Network for Unrolling Trajectories. Different from existing encoder-decoder forecasting models, we encode historical trajectories and predict future trajectories with a single autoregressive model. This allows the model to make iterative predictions in a consistent manner, and ensures that the model is always provided with up-to-date information, enhancing the performance. Furthermore, inspired by multi-token prediction for language modeling, we introduce an 'overprediction' strategy that gives the network the auxiliary task of predicting trajectories at longer temporal horizons. This allows the model to better anticipate the future, and further improves the performance. With experiments, we demonstrate that our decoder-only approach outperforms the encoder-decoder baseline, and achieves new state-of-the-art results on the Argoverse 2 single-agent motion forecasting benchmark.
|
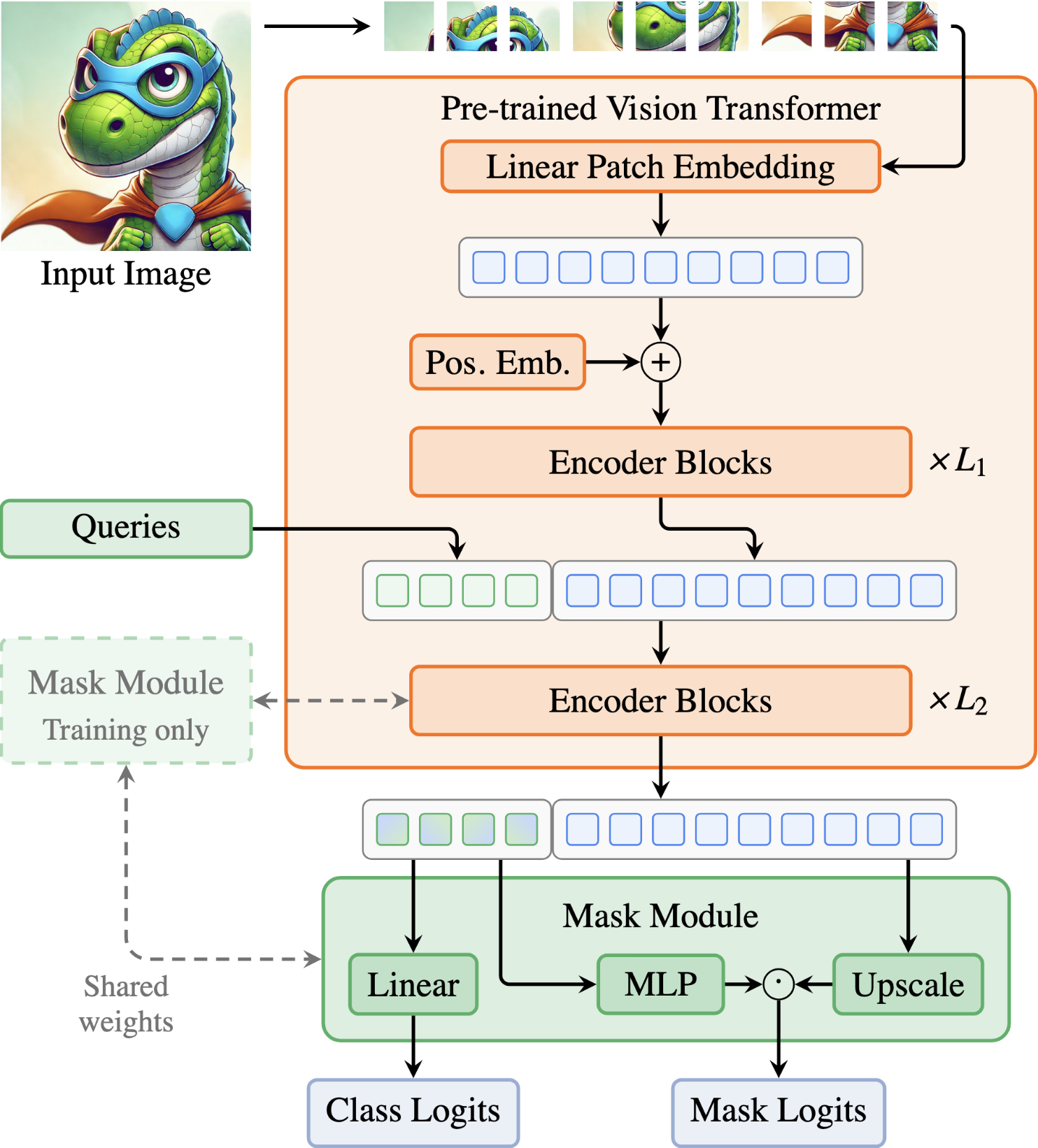 Your ViT is Secretly an Image Segmentation Model Conference on Computer Vision and Pattern Recognition (CVPR) 2025 (Highlight) Vision Transformers (ViTs) have shown remarkable performance and scalability across various computer vision tasks. To apply single-scale ViTs to image segmentation, existing methods adopt a convolutional adapter to generate multi-scale features, a pixel decoder to fuse these features, and a Transformer decoder that uses the fused features to make predictions. In this paper, we show that the inductive biases introduced by these task-specific components can instead be learned by the ViT itself, given sufficiently large models and extensive pre-training. Based on these findings, we introduce the Encoder-only Mask Transformer (EoMT), which repurposes the plain ViT architecture to conduct image segmentation. With large-scale models and pre-training, EoMT obtains a segmentation accuracy similar to state-of-the-art models that use task-specific components. At the same time, EoMT is significantly faster than these methods due to its architectural simplicity, e.g., up to 4× faster with ViT-L. Across a range of model sizes, EoMT demonstrates an optimal balance between segmentation accuracy and prediction speed, suggesting that compute resources are better spent on scaling the ViT itself rather than adding architectural complexity. Code: https://www.tue-mps.org/eomt/.
|
