
Parse27k
Pedestrian Attribute Recognition in Sequences
- >27,000 annotated pedestrians
- 10 attributes.
- carefully defined splits in train, validation, and test.
- taken from 8 video sequences recorded on multiple days - every 15th frame used.
This is a new pedestrian attribute benchmark dataset publicly available to the research community. The dataset is interesting for applications in robotics for interaction with persons. It is also interesting for Machine Learning researchers in general, due to the intriguing properties of the attribute classification task.
Examples
 |
 |
 |
 |
 |
 |
Background
This dataset was created as part of the ERC Starting Grant project CV-SUPER in the Computer Vision Group at the Visual Computing Institute, RWTH Aachen University. We work, among other things, on research for dynamic scene understanding for mobile vision applications, including robotics and automotive scenarios.
To this end, we want to move beyond localization of persons and to infer additional semantic information about their activities and interactions. This is a prerequisite for many interesting robotic applications.
There are several existing datasets for human attribute recognition. However, very few of them have been created with a mobile dynamic scene analysis application in mind, where the primary goal is to gain further information about people that are detected and tracked from a mobile platform (e.g., an intelligent vehicle or a mobile service robot). This task is notably different from an analysis of web images on a social media or community photo sharing website. A main difference in our target scenario is that the inputs for the attribute recognition task are fixed-size bounding boxes provided by a pedestrian detector or tracker. Thus, the input is already strongly aligned and features only a subset of possible human postures (namely the ones the initial detector could detect). On the other hand, the target scenario of outdoor scene analysis from live video implies challenging lighting conditions and the absence of photographer bias (i.e., the property of consciously taken photographs that the subject is typically nicely visible, well lit, and facing the camera).
We have therefore created this new dataset specifically catering to the constraints of mobile vision applications. We provide it to the public as an interesting benchmark set for further research on general human attribute recognition, but also with the hope that it will foster research that can be applied in mobile robotics or automotive applications.
The PARSE-27k dataset is also of interest from a Machine Learning perspective. By design, the annotated attributes feature interesting inter-dependencies. It is currently still unclear how such inter-dependencies are best represented in a recognition approach, and we hope that our dataset will help research progress in this direction. In addition, since our attribute recognition task is motivated by an application in a pedestrian tracking system where multiple estimates are integrated over time, it has the interesting property that each attribute recognition result should come with a confidence estimate and/or a prediction whether the target attribute can be reliably observed in the input image at all. Designing such confidence estimates is an interesting research task of its own and it is currently unclear what the best solution is here. We discuss those issues also in detail in our paper, please refer to the discussion there.
About the Dataset
PARSE-27k is based on 8 video sequences of varying length taken by a moving camera in a city environment. Every 15th frame of the sequences has been processed by the DPM pedestrian detector. We manually annotated the resulting bounding boxes with 10 attribute labels, while sorting out the detector's false positives. The choice of attributes is motivated by a robotics/automotive application scenario and features several visual properties concerned with handling carried items that affect a person's appearance and shape.
PARSE-27k has a careful training (50%), validation (25%) and test (25%) split. This means that we have split only along sequence boundaries. Additionally, sequences taken on the same day are either in train-val or test. This avoids highly similar examples across splits. Compared to other person attribute datasets, PARSE-27k has relatively little variance with respect to pose and crop, since it only contains crops of pedestrian bounding boxes obtained by a pedestrian detector. This is in contrast to some other publicly available datasets, which show a large variety of different poses and crops (upper-body shots, only face, full body). By both increasing the dataset size and reducing this variance, we hope to improve model quality.
Attributes
The attributes are all defined based on some binary or multinomial proposition. The annotated attributes include two orientation labels with 4 and 8 discretizations, and several binary attributes with an additional N/A state:
- N/A or ? - the observer cannot decide
- yes - the proposition holds
- no - the proposition does not hold
All attributes make use of the N/A label, so the binary attributes have 2+1 possible labels. Note that other attribute datasets also use such N/A labels. This is not specific to our dataset, but rather induced by the definition of the attribute recognition task. If the underlying proposal is not decidable, one cannot sensibly give a valid ground-truth label. This is the aspect that makes the task interesting from a machine learning perspective, as it sets the attribute recognition task apart from the regular classification task.
In the literature, the N/A-labels have often been handled by exluding them from the evaluation or treating them as don't cares (i.e., filtering them out). We call this the retrieval viewpoint. Alternatively, one can try to also predict the N/A labels, which views the task as an N+1-class classification task. Our evaluation scripts allow to take both views.
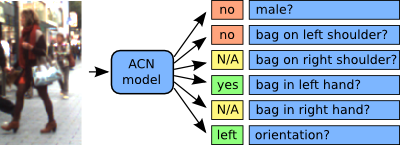
The examples are all annotated with the following attributes:
- Gender (male, female, ?)
- Posture (standing, walking, (sitting), ?)
- Orientation (4 discretizations + ?)
- Orientation8 (8 discretizations + ?)
- Bag on Left Shoulder (yes, no, ?)
- Bag on Right Shoulder (yes, no, ?)
- Bag in Left Hand (yes, no, ?)
- Bag in Right Hand (yes, no, ?)
- Backpack (yes, no, ?)
- isPushing (yes, no, ?) -- child-strollers, etc.
Actually, there is a third Orientation attribute Orientation12, which has been synthetically generated from the other two. It is also included in the published annotations database, but we have not used it in our published experiments.
Note, that the bag attributes are defined relative to the person. A bag on the person's right shoulder can be left or right in the bounding box, depending on the walking direction. We count a bag on the right shoulder also if only the shoulder strap is on that side, but the bag is on the other side. The position of the shoulder strap defines the location of the bag.
Additionally, there is a flag isOccluded that indicates whether the person is (partially) occluded. This has not been used in our experiments so far, but could be useful in the future.
We have also annotated two additional attributes: isPulling and isTalkingOnPhone. However, we found that too few examples of those attributes were available in our data, such that chances are very low to be able to learn useful models for these concepts. We therefore excluded those attributes from our experiments. Similarly, the Posture attribute is a four valued attribute in the database, where sitting is present. However, there are very few examples for this, due to the way we obtained the bounding boxes. Therefore, we exclude sitting from our experiments, and use Posture as a binary attribute with values (walking, standing and N/A).
Nonetheless, the labels for above concepts are included in the published annotations, such that they can be addded if the dataset is extended with additional examples. The scripts we provide can be easily adapted to work on these labels.
Technical Details
The annotations are stored in a convenient sqlite3 format. All the pedestrian examples are in table Pedestrian. Their corresponding labels are in table AttributeSet. For each attribute there is a table to translate the labels. The format is straight-forward. Additionally, we provide some Python scripts as examples on how to use the annotations.
We provide the full frames of the video sequences, and the bounding box information. This allows researchers to crop the bounding boxes according the their needs.
For convenience, we also provide some pre-cropped examples in HDF5-format. This can be useful to get started quickly, but for good performance you should consider to crop the examples yourself according to your model's needs.
Evaluation Tools
We provide some Python scripts along with the dataset. These include evaluation routines, that should be used when comparing to the results in our paper. Please, either use these tools directly -- or refer to their use of the dataset -- so you obtain comparable results (on the same set of training examples, etc.). Among some other helpful scripts, we provide:
- Evaluation routines -
parse_evaluation.py - Preparing crops of the examples -
preprocess_dataset.py
For details on installation and usage, please look at the README.md.
Follow these on GitHub, to be notified of updates!
Paper Reference
If you are using this dataset for a publication, please cite our paper:
BMVC Paper
This dataset has also been used in our BMVC paper.
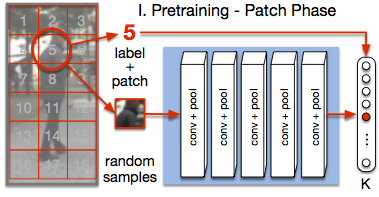
ConvNet training is highly sensitive to initialization of the weights. A widespread approach is to initialize the network with weights trained for a different task, an auxiliary task. The ImageNet-based ILSVRC classification task is a very popular choice for this, as it has shown to produce powerful feature representations applicable to a wide variety of tasks. However, this creates a significant entry barrier to exploring non-standard architectures. In this paper, we propose a self-supervised pretraining, the PatchTask, to obtain weight initializations for fine-grained recognition problems, such as person attribute recognition, pose estimation, or action recognition. Our pretraining allows us to leverage additional unlabeled data from the same source, which is often readily available, such as detection bounding boxes. We experimentally show that our method outperforms a standard random initialization by a considerable margin and closely matches the ImageNet-based initialization.
Find the accompanying code on GitHub. Get the unlabeled detection crops that can be used for the PatchTask pretraining.
Acknowledgement
This work was funded by ERC Starting Grant project CV-SUPER (ERC-2012-StG-307432).
Download
By downloading this dataset you agree to the following terms:
- This dataset is provided "AS IS", without any warranty of any kind.
- If you use this dataset to publish any work, you agree to cite our paper.
- If you publish any examples from the dataset, you agree to blur faces of individuals, such that no person is identifiable from the published pictures.
- Dataset - (full images) - to crop yourself (includes the annotations database).
- Annotation DB
sqlite3- just the annotation database. - Example Crops - HDF5 file format of 64x128 sized crops including labels (for quick experiments).
- Python Tools.
In our BMVC paper, we have leveraged unlabeled data for a semi-supervised pretraining that we called PatchTask. To let other researchers continue with this work, we also provide all detection bounding boxes from the training and validation sequences:
- HDF5 file - crops of all detections from training sequences (14GB!)
- HDF5 file - crops of all detections from validation sequences (9GB!)
Contact
For questions contact: Patrick Sudowe
(lastname -- at -- vision.rwth-aachen.de)
